Автор: Денис Аветисян
В статье рассматривается, как современные инструменты, такие как машинное обучение и языковые модели, влияют на подходы к преподаванию статистики и формированию новых компетенций.
Обзор эволюции статистического образования в эпоху развития технологий, с акцентом на интеграцию языков программирования R и Python, машинного обучения и принципов воспроизводимости исследований.
Быстрое развитие технологий ставит перед статистическим образованием задачу адаптации к меняющимся требованиям современной практики. В статье ‘Reflections on the Future of Statistics Education in a Technological Era’ рассматриваются ключевые тенденции и вызовы, связанные с интеграцией современных инструментов в учебный процесс. Основной тезис работы заключается в необходимости пересмотра существующих учебных программ с учетом таких направлений, как программирование на R и Python, машинное обучение и, особенно, возможности применения генеративных моделей искусственного интеллекта. Какие стратегии позволят сформировать у студентов навыки критического мышления и анализа данных, необходимые для успешной работы в эпоху больших данных и автоматизации?
От данных к пониманию: Основы современной науки о данных
Современная наука о данных зиждется на способности извлекать ценную информацию из сложных наборов данных, что требует применения надежных аналитических методов. Несмотря на экспоненциальный рост объемов информации, задача не ограничивается простым накоплением — ключевым является выявление скрытых закономерностей, трендов и взаимосвязей. Для этого используются разнообразные статистические модели и алгоритмы машинного обучения, позволяющие не только описывать текущее состояние, но и прогнозировать будущие изменения. Эффективность этих методов напрямую зависит от качества данных и строгости применяемых аналитических процедур, поскольку даже незначительные погрешности могут привести к ошибочным выводам и неверным решениям. Таким образом, наука о данных представляет собой междисциплинарную область, требующую глубоких знаний в статистике, математике, информатике и предметной области, чтобы обеспечить достоверность и значимость полученных результатов.
Статистическое моделирование и машинное обучение представляют собой ключевые инструменты в извлечении знаний из данных. Эти подходы позволяют не только выявлять скрытые закономерности и тенденции в сложных наборах данных, но и строить прогностические модели, способные предсказывать будущие события или поведение систем. Используя методы, такие как регрессионный анализ, классификация, кластеризация и нейронные сети, специалисты по данным могут преобразовывать необработанную информацию в ценные инсайты. y = f(x) + \epsilon — простейшая модель регрессии демонстрирует, как зависимая переменная y предсказывается на основе независимой переменной x с учетом случайной ошибки ε. Эффективное применение этих методов требует глубокого понимания как математических основ, так и специфики конкретной предметной области, что позволяет получать надежные и практически значимые результаты.
Строгая методология: Обеспечение воспроизводимости анализа
Воспроизводимость рабочих процессов имеет решающее значение для проверки результатов анализа данных и укрепления доверия к полученным выводам. Отсутствие воспроизводимости может привести к неверной интерпретации результатов и ошибочным решениям, особенно в критически важных областях применения. Воспроизводимость обеспечивается путем документирования всех этапов анализа, включая используемые данные, код, параметры и окружение исполнения. Это позволяет другим исследователям или аналитикам независимо повторить анализ и подтвердить полученные результаты. Использование систем контроля версий, контейнеризации и автоматизированных пайплайнов значительно упрощает обеспечение воспроизводимости и повышает надежность анализа данных.
Системы контроля версий являются основополагающими для отслеживания изменений в коде, данных и конфигурациях, обеспечивая возможность отката к предыдущим состояниям и совместной работы над проектами. Они позволяют фиксировать каждое изменение с указанием автора и комментарием, что облегчает аудит и отладку. Параллельно, облачные вычисления предоставляют масштабируемые вычислительные ресурсы и хранилища данных, необходимые для обработки больших объемов информации и запуска ресурсоемких задач, при этом избавляя от необходимости поддерживать собственную инфраструктуру. Комбинация этих технологий позволяет командам эффективно сотрудничать, управлять изменениями и масштабировать свои проекты без ограничений, связанных с локальными ресурсами.
Эффективное получение данных часто основывается на доступе к API и веб-скрейпинге, что значительно упрощает процесс сбора информации. Использование API позволяет получать структурированные данные напрямую от поставщиков, обеспечивая автоматизированный и надежный способ получения актуальной информации. В ситуациях, когда API недоступны, веб-скрейпинг предоставляет возможность извлекать данные из HTML-структуры веб-страниц. Автоматизация этих процессов с помощью скриптов и специализированных библиотек позволяет собирать большие объемы данных с высокой скоростью и точностью, минимизируя ручной труд и потенциальные ошибки. Важно учитывать условия использования веб-сайтов и соблюдать этические нормы при веб-скрейпинге.
Инструменты исследователя: Экосистемы R и Python для анализа данных
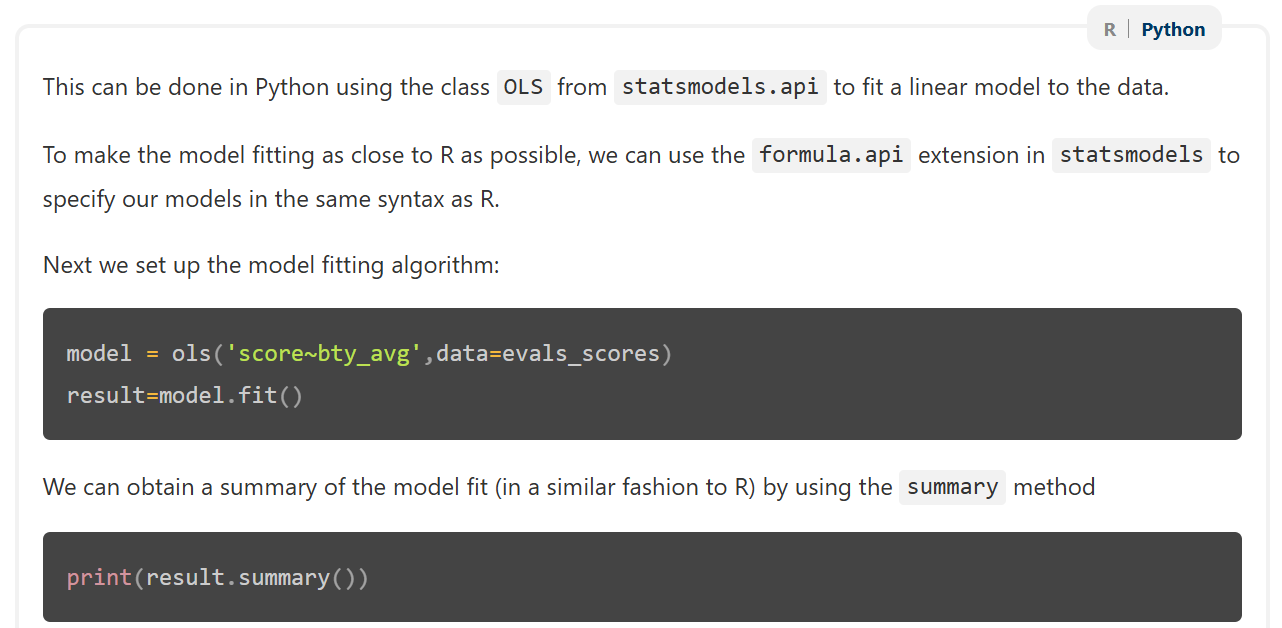
Языки программирования R и Python в настоящее время являются лидирующими в области анализа данных, благодаря обширным библиотекам и инструментам для статистических вычислений. Python располагает такими пакетами, как NumPy, SciPy, pandas и scikit-learn, предоставляющими возможности для численных расчетов, научных вычислений, анализа данных и машинного обучения. В R аналогичные функции обеспечиваются пакетами, входящими в состав Tidyverse, а также базовыми статистическими функциями и пакетами, такими как stats и lme4. Оба языка поддерживают широкий спектр статистических методов, включая регрессионный анализ, временные ряды, кластерный анализ и методы машинного обучения, что делает их незаменимыми инструментами для специалистов в области data science.
В языке R экосистема Tidyverse предоставляет согласованный набор пакетов, таких как dplyr, ggplot2 и tidyr, для эффективной обработки, визуализации и преобразования данных. В Python аналогичные возможности обеспечиваются такими пакетами, как pandas для манипулирования данными, matplotlib и seaborn для визуализации, и NumPy для численных вычислений. Эти библиотеки предлагают высокоуровневые функции и структуры данных, позволяющие пользователям выполнять сложные операции анализа данных с минимальным объемом кода, включая фильтрацию, агрегирование, преобразование и построение графиков. Обе экосистемы поддерживают как интерактивный анализ данных, так и создание воспроизводимых отчетов и аналитических пайплайнов.
Языки R и Python предоставляют инструменты для создания интерактивных веб-приложений и динамических отчетов. Пакет Shiny в R позволяет разрабатывать интерактивные приложения непосредственно из R-кода, не требуя знаний веб-технологий. Для создания динамических отчетов, объединяющих код, текст и результаты вычислений, в R используются пакеты RMarkdown и Quarto. Quarto является кросс-платформенным инструментом, поддерживающим не только R, но и Python, что позволяет создавать воспроизводимые отчеты и презентации, используя оба языка в одном документе. Эти инструменты облегчают процесс представления результатов анализа данных и делают их доступными для широкой аудитории.
Новая волна интеллекта: От машинного обучения к генеративным моделям
Искусственный интеллект, основанный на машинном обучении, коренным образом меняет ландшафт науки о данных, открывая беспрецедентные возможности для автоматизации рутинных задач и выявления скрытых закономерностей в больших объемах информации. Вместо того, чтобы требовать от аналитиков ручного анализа, алгоритмы машинного обучения способны самостоятельно извлекать ценные сведения, прогнозировать тенденции и оптимизировать процессы. Этот процесс включает в себя обучение моделей на исторических данных, что позволяет им адаптироваться и совершенствоваться без явного программирования для каждой конкретной задачи. В результате, специалисты по данным могут сосредоточиться на более сложных аспектах анализа, таких как интерпретация результатов и принятие стратегических решений, в то время как машины берут на себя бремя трудоемкой обработки информации.
Генеративный искусственный интеллект, в особенности крупные языковые модели, значительно расширяет границы возможностей анализа данных, позволяя не просто выявлять закономерности в существующих наборах, но и создавать принципиально новый контент и глубокие инсайты. Эти модели способны генерировать тексты, изображения, и даже программный код, основываясь на изученных паттернах, что открывает перспективы для автоматизации творческих процессов и решения задач, ранее требовавших человеческого участия. В отличие от традиционных алгоритмов машинного обучения, фокусирующихся на предсказаниях и классификации, генеративный ИИ способен к самостоятельному созданию нового материала, имитируя стили и структуры, что делает его мощным инструментом для исследований, разработки продуктов и контент-маркетинга.
Представленная работа является всесторонним обзором развивающихся технологий и педагогических подходов, подчеркивая необходимость адаптивных учебных программ, в которых интегрируются современные методы обработки данных, навыки программирования на языках R и Python, принципы машинного обучения и инструменты генеративного искусственного интеллекта. Такой подход призван подготовить студентов к работе в современных аналитических средах, где способность эффективно работать с большими данными и применять передовые алгоритмы становится ключевым требованием. Особое внимание уделяется формированию у обучающихся навыков критического мышления и адаптации к быстро меняющимся технологическим условиям, что позволит им успешно решать сложные задачи в различных областях науки и практики.
Исследование закономерностей в статистическом образовании, представленное в статье, находит отклик в философских взглядах Жан-Жака Руссо. Он утверждал: «Вернуться к природе — вот что необходимо». В контексте статьи, это означает возвращение к фундаментальному статистическому мышлению, несмотря на стремительное развитие технологий вроде машинного обучения и генеративного искусственного интеллекта. Акцент на воспроизводимость исследований и использование инструментов вроде R и Python лишь усиливает необходимость критического анализа данных, выявления скрытых зависимостей и понимания принципов, лежащих в основе статистических методов. Каждое отклонение от стандартных подходов, каждое новое направление в образовании — возможность углубить понимание мира данных.
Куда же дальше?
Представленный анализ, хотя и очерчивает контуры необходимой трансформации статистического образования, неизбежно сталкивается с вопросами, требующими дальнейшего осмысления. Автоматизация рутинных вычислений, безусловно, освобождает ресурсы для развития критического мышления, однако существует риск сведения статистики к набору «черных ящиков», где понимание лежащих в основе принципов уступает место умению запускать алгоритмы. Необходимо тщательно изучить, как сохранить акцент на фундаментальных концепциях, не перегружая учебные программы новыми инструментами.
Особый интерес представляет потенциал генеративных моделей искусственного интеллекта. Они могут стать мощным инструментом для визуализации сложных данных и создания интерактивных учебных материалов, но одновременно порождают вопрос о границах автоматической интерпретации. Достаточно ли будет обучения «проверке фактов», когда сама реальность становится результатом машинного обучения? Очевидно, что образовательный процесс должен научить не просто использовать, но и критически оценивать результаты, генерируемые искусственным интеллектом.
В конечном счете, успех трансформации статистического образования зависит не только от внедрения новых технологий, но и от изменения самой философии обучения. Необходимо сместить акцент с запоминания формул на развитие способности к построению моделей, выявлению закономерностей и интерпретации данных в контексте реальных проблем. Понимание системы, а не просто владение инструментами — вот истинная цель статистического образования в технологическую эпоху.
Оригинал статьи: https://arxiv.org/pdf/2602.18242.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Поиск материалов с помощью интеллекта: от текста к новым открытиям
- Квантовые точки: Насос против напряжения
- Видео в Уравнения: Как ИИ Раскрывает Скрытые Законы Физики
- Искусственный интеллект и рефакторинг кода: что пока умеют AI-агенты?
- Диалоги на грани языков: новый тест для искусственного интеллекта
- Квантовый код: Слияние классики и управления
- Погода под контролем: Квантово-классическое моделирование для точного прогнозирования
- Квантовые нейросети: новый взгляд на приближение периодических функций
- Восстановление фотореализма: новый подход к обработке реальных изображений
- Наука на новом языке: Модель Innovator-VL открывает горизонты исследований
2026-02-24 06:49