Автор: Денис Аветисян
Исследователи предлагают инновационный подход к эффективному распределению вычислительных ресурсов при масштабировании больших языковых моделей в реальном времени.
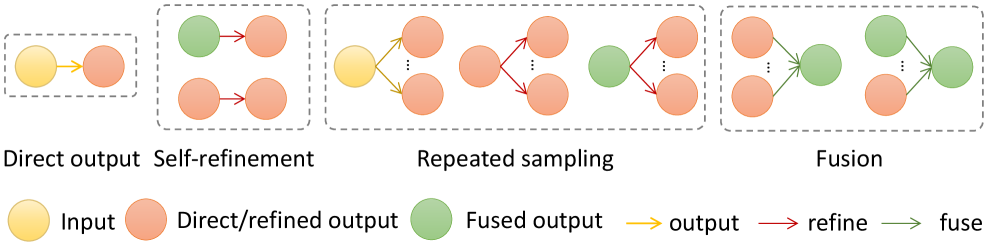
В статье представлена Agent-REINFORCE – система, использующая агентов и обучение с подкреплением для поиска оптимальных графов сотрудничества между моделями при заданном вычислительном бюджете.
Несмотря на успехи масштабирования больших языковых моделей (LLM), оптимальное распределение вычислительных ресурсов во время инференса остается сложной задачей. В работе ‘Generalizing Test-time Compute-optimal Scaling as an Optimizable Graph’ предложен новый подход к задаче поиска оптимальных комбинаций LLM и архитектур для test-time scaling, рассматривая ее как оптимизацию графа совместной работы моделей. Ключевым результатом является разработка фреймворка Agent-REINFORCE, использующего LLM-агентов и обучение с подкреплением для эффективного поиска оптимальных графов сотрудничества моделей при фиксированном вычислительном бюджете. Сможет ли предложенный подход значительно улучшить производительность LLM и открыть новые возможности для адаптивного распределения ресурсов в реальных приложениях?
За гранью последовательной обработки: Ограничения традиционного TTS
Традиционные методы преобразования текста в речь, основанные на последовательной обработке, испытывают трудности при решении задач, требующих сложного логического вывода и разнообразных выходных данных. Масштабирование таких систем сталкивается с законом убывающей доходности, что стимулирует поиск новых архитектур, исследующих возможности параллелизации. Вычислительная стоимость становится критическим узким местом, требующим эффективного распределения ресурсов. Повышение эффективности алгоритмов и оптимизация аппаратного обеспечения – ключевые направления исследований. Иногда кажется, что каждая попытка создать «умный» синтезатор речи обречена на то, чтобы стать очередным сложным и неэффективным механизмом.
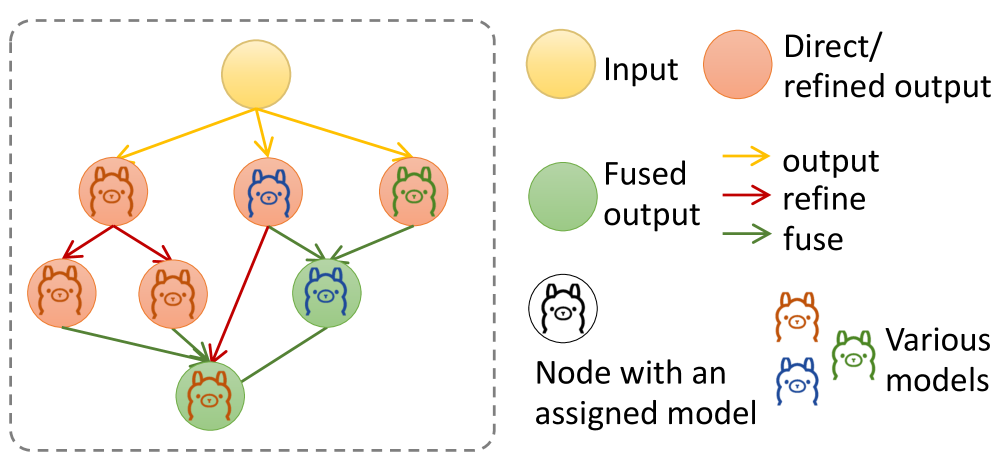
Оркестровка интеллекта: Граф совместной работы Multi-LLM
Представлена архитектура Multi-LLM Collaboration Graph, в которой большие языковые модели (LLaMA Models, Gemma Models) функционируют как специализированные узлы. Каждый узел выполняет определенную роль, обеспечивая поток информации и совместное уточнение результатов. Данный подход позволяет осуществлять параллельное исследование пространства решений, преодолевая ограничения последовательной обработки. Архитектура позволяет динамически регулировать ширину и глубину графа, оптимизируя компромисс между ними для конкретных задач.
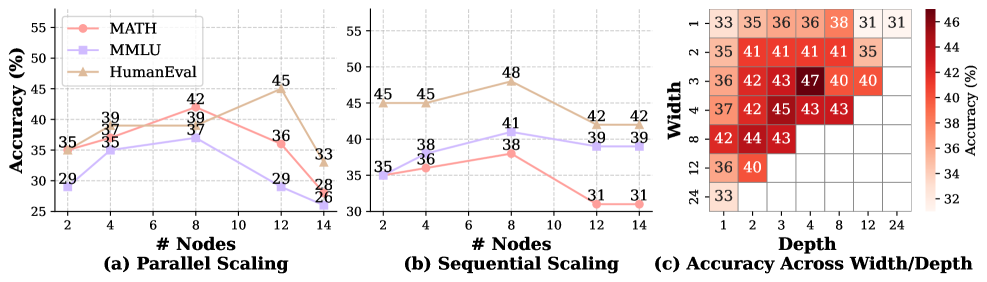
Поиск оптимального графа: Agent-REINFORCE
Для эффективного поиска оптимальной конфигурации графа преобразования текста в речь используется Agent-REINFORCE, фреймворк, основанный на алгоритме REINFORCE и дополненный возможностями больших языковых моделей. Экспериментальные исследования демонстрируют значительные улучшения производительности на сложных эталонных задачах, включая HumanEval, MATH и MMLU. В частности, на задаче MATH достигнута точность в 47% при вычислительном бюджете в 8080 FLOPs. Оптимизация с учётом задержки позволяет добиться времени отклика в 5.6 секунд, сохраняя высокую производительность.
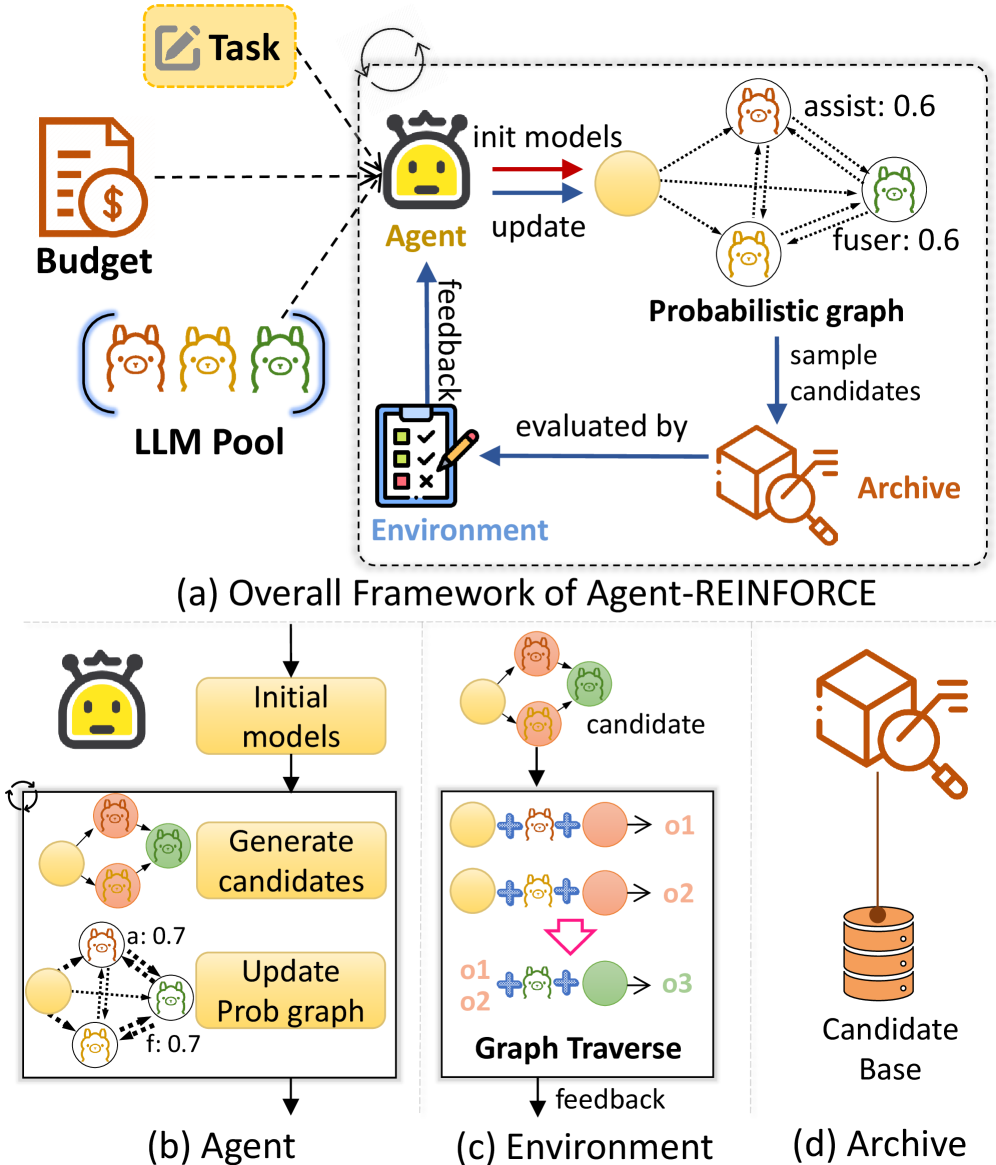
За пределами бенчмарков: Адаптивное и эффективное рассуждение
В ходе исследований алгоритм Agent-REINFORCE продемонстрировал превосходство над традиционными методами оптимизации, такими как Bayesian Optimization и TextGrad, как по производительности, так и по эффективности. Адаптивность платформы выходит за рамки конкретных тестов, демонстрируя устойчивость при решении широкого спектра задач. Эффективное использование вычислительных ресурсов позволяет минимизировать необходимое количество операций с плавающей точкой, что открывает перспективы для применения технологии в средах с ограниченными ресурсами. Каждая «революционная» технология завтра станет техдолгом.
Наблюдатель видит, как стремление к оптимальности в масштабировании LLM-моделей во время тестирования, описанное в работе, неизбежно сталкивается с суровой реальностью ограниченных вычислительных ресурсов. Подобно тому, как элегантная теоретическая конструкция рушится под напором практической реализации, Agent-REINFORCE ищет не абсолютное совершенство, а компромисс, максимизирующий производительность в заданных рамках. Как однажды заметил Давид Гильберт: «В математике нет трапез, только пейзажи». И в этой работе пейзаж оптимизации, формируемый графами коллаборации, ограничен жесткими рамками бюджета, а поиск оптимального пути – это всегда баланс между желаемым и возможным.
Что дальше?
Предложенный подход, безусловно, демонстрирует потенциал автоматизированного поиска компромиссов в распределении вычислительных ресурсов. Однако, стоит признать: оптимизация графа коллаборации – это лишь один из уровней сложности. Производство всегда найдёт способ выявить узкие места, будь то латентные задержки в коммуникациях между моделями или нелинейное масштабирование стоимости отдельных узлов. Архитектура, как известно, – это не схема, а компромисс, переживший деплой.
Будущие исследования неизбежно столкнутся с необходимостью учитывать динамически меняющиеся вычислительные бюджеты и требования к задержке. Более того, вопрос о репрезентативности используемых обучающих данных для формирования графа остаётся открытым. Всё, что оптимизировано, рано или поздно оптимизируют обратно, и в данном случае, это может потребовать адаптации графа к новым, непредвиденным сценариям.
В конечном счёте, задача не в создании идеально оптимизированного графа, а в разработке самоадаптирующихся систем, способных к непрерывной реабилитации надежды. Мы не рефакторим код – мы реанимируем надежду. И этот процесс, как показывает опыт, бесконечен.
Оригинал статьи: https://arxiv.org/pdf/2511.00086.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Автономные агенты для анализа материалов: новый уровень автоматизации
- Энергоэффективность сотовой сети: обучение с подкреплением и управление режимами сна
- Динамика в кадре: Как научить ИИ понимать физику видео
- Сердце музыки: открытые модели для создания композиций
- Где большие языковые модели терпят неудачи в программировании?
- Логика машин: Как научить ИИ рассуждать, а не просто повторять
- Геометрия Искусственного Интеллекта: Путь к Универсальности
- Вариационные и полувариационные неравенства: от теории к практике
- Данные в движении: Автоматизация подготовки данных с помощью искусственного интеллекта
- Квантовый свет: Когда лазер перестает быть экспериментом
2025-11-04 21:25