Автор: Денис Аветисян
Новый подход позволяет существенно повысить скорость и надежность поиска релевантной информации при использовании архитектур вычислений в памяти.
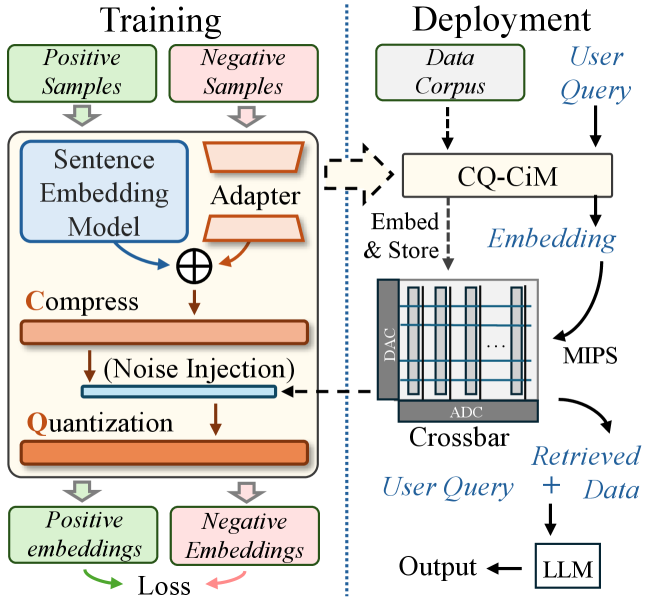
Представлена методика CQ-CiM, формирующая низкобитные векторные представления для устойчивого поиска в системах с использованием энергонезависимой памяти.
Несмотря на растущий спрос на развертывание генеративных моделей с поиском по базе знаний (RAG) на периферийных устройствах, традиционные архитектуры сталкиваются с ограничениями, связанными с задержками при передаче и обработке больших объемов данных. В данной работе, ‘CQ-CiM: Hardware-Aware Embedding Shaping for Robust CiM-Based Retrieval’, представлен новый подход, направленный на преодоление “разрыва в представлении” между высокоточными векторными представлениями и аппаратными ограничениями архитектур вычислений в памяти (CiM). Предложенный фреймворк CQ-CiM объединяет сжатие и квантизацию для создания низкобитных вложений, оптимизированных для различных CiM-реализаций, обеспечивая тем самым эффективный и надежный поиск. Возможно ли, благодаря такому аппаратно-ориентированному формированию данных, расширить возможности CiM и ускорить внедрение RAG на периферийных устройствах?
Высокоразмерные Векторы: Узкое Место Современных RAG-Систем
В основе систем генерации с расширенным поиском (RAG) лежит эффективный поиск релевантного контекста в многомерных векторных пространствах, где каждый фрагмент информации представлен в виде числового вектора — эмбеддинга. Этот процесс предполагает сопоставление запроса пользователя с существующими эмбеддингами для выявления наиболее близких и, следовательно, релевантных источников данных. Точность и скорость этого поиска напрямую влияют на качество генерируемого ответа, поскольку система опирается на найденный контекст для формирования связного и информативного текста. Таким образом, способность эффективно ориентироваться в этих высокоразмерных пространствах является ключевым фактором, определяющим производительность и применимость RAG-систем в различных задачах, от ответов на вопросы до создания контента.
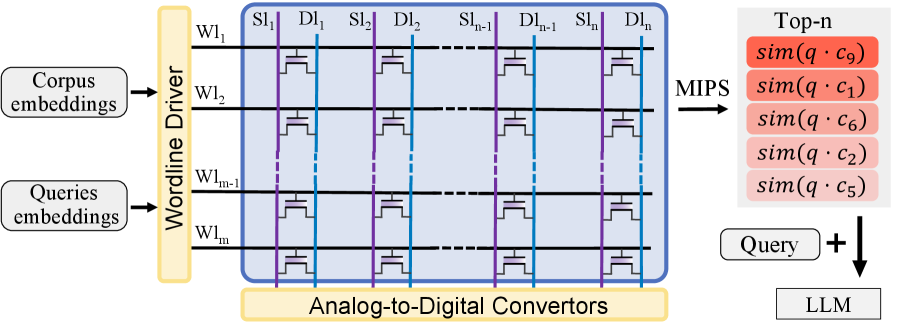
Поиск по максимальному скалярному произведению, являясь эффективным методом извлечения информации в системах генерации на основе извлечения (RAG), сталкивается с существенными вычислительными ограничениями при увеличении размерности векторных представлений. По мере роста числа измерений, необходимых для точного кодирования семантического значения, сложность вычислений возрастает экспоненциально, что приводит к замедлению скорости поиска и увеличению потребления ресурсов. Это особенно критично при работе с большими базами знаний и в ситуациях, требующих быстрого ответа, таких как мобильные устройства или системы реального времени. Ограничения масштабируемости, связанные с высокой размерностью, препятствуют широкому внедрению мощных языковых моделей в ресурсоограниченных средах, подчеркивая необходимость разработки новых, более эффективных алгоритмов поиска и методов снижения размерности.
Ограничения в производительности при поиске в высокоразмерных векторных пространствах становятся серьезным препятствием для внедрения больших языковых моделей (LLM) в устройства с ограниченными вычислительными ресурсами, такие как мобильные телефоны или встроенные системы. Невозможность быстро и эффективно извлекать релевантную информацию из векторных представлений контекста значительно снижает практическую ценность LLM в сценариях, требующих мгновенного ответа и автономной работы. Это требует разработки принципиально новых вычислительных подходов и алгоритмов, способных обеспечить необходимую скорость и эффективность поиска в условиях ограниченной памяти и энергопотребления, открывая путь к более широкому применению LLM в повседневной жизни и специализированных областях.
Вычисления в Памяти: Новый Импульс для Эффективности
Вычисления в памяти (CiM) представляют собой принципиально новый подход к обработке данных, заключающийся в выполнении вычислений непосредственно внутри массива памяти. Традиционная архитектура фон Неймана требует постоянного перемещения данных между процессором и памятью, что создает узкое место, известное как “узкое место фон Неймана”. CiM устраняет эту задержку, позволяя выполнять операции умножения и сложения (основные компоненты многих алгоритмов машинного обучения) непосредственно в ячейках памяти, что значительно снижает энергопотребление и увеличивает скорость обработки данных. Это достигается за счет использования физических свойств ячеек памяти для выполнения вычислений, минуя необходимость в отдельном процессоре.
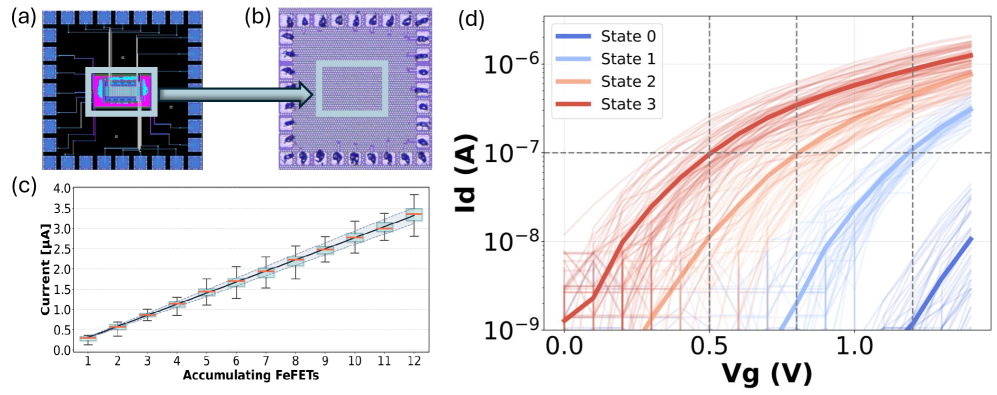
Существуют различные реализации Compute-in-Memory (CiM), использующие различные типы памяти. Статическая оперативная память (SRAM) обеспечивает высокую скорость и надежность, но характеризуется низкой плотностью и высоким энергопотреблением. Резистивная оперативная память (ReRAM) предлагает более высокую плотность и низкое энергопотребление, однако ее скорость работы и надежность могут быть ниже, чем у SRAM. Ферроэлектрические полевые транзисторы (FeFET) представляют собой компромисс между этими двумя подходами, обеспечивая умеренную плотность, скорость и энергоэффективность. Выбор конкретной технологии CiM зависит от требований конкретного приложения, учитывая взаимосвязь между плотностью, скоростью вычислений и потребляемой мощностью.
Непосредственное применение высокоточных векторных представлений (embeddings) к аппаратному обеспечению Compute-in-Memory (CiM) сталкивается с проблемой, известной как “Разрыв в представлении” (Representation Gap). Суть заключается в несоответствии между точностью представления данных в embeddings (обычно 32 или 16 бит) и ограниченной точностью самих CiM-устройств, использующих, например, резистивную память (ReRAM) или полевые транзисторы с плавающим затвором (FeFET). Это ограничение точности может привести к существенным потерям информации и снижению точности вычислений, особенно при работе с задачами, требующими высокой точности, такими как глубокое обучение. Для смягчения данной проблемы разрабатываются методы квантования и обучения с учетом ограничений точности CiM-аппаратного обеспечения.
CQ-CiM: Объединяя Сжатие и Квантование для Оптимальной Эффективности
CQ-CiM представляет собой унифицированную структуру, разработанную для одновременного сжатия и квантования векторных представлений (embeddings). Данный подход направлен на минимизацию потери информации при уменьшении размерности и точности представлений, обеспечивая при этом максимальную совместимость с устройствами Compute-in-Memory (CiM). В отличие от последовательного применения сжатия и квантования, CQ-CiM интегрирует оба процесса в единый фреймворк, что позволяет оптимизировать их совместно и достичь более высокой эффективности и точности при работе с данными на CiM-устройствах. Ключевая особенность заключается в одновременной оптимизации параметров сжатия и квантования с целью сохранения семантической близости между исходными и преобразованными представлениями.
CQ-CiM использует последовательную архитектуру, состоящую из Компрессионного блока (Compression Head) и Блока Квантования (Quantization Head). Компрессионный блок отвечает за снижение размерности векторных представлений (embeddings), уменьшая количество параметров и вычислительную сложность. Последующий Блок Квантования преобразует сжатые векторы в низкобитные представления, что необходимо для эффективного использования в устройствах Compute-in-Memory (CiM). Такая последовательность позволяет оптимизировать как сжатие, так и квантование, обеспечивая совместимость с ограничениями аппаратного обеспечения CiM и минимизируя потери информации.
Для стабилизации процессов сжатия и квантования, а также для улучшения семантической геометрии векторных представлений, в CQ-CiM используется комбинация функции потерь среднеквадратичной ошибки (Mean Squared Error, MSE) и контрастивного обучения. MSE обеспечивает реконструкцию исходных эмбеддингов после сжатия и квантования, минимизируя потерю информации. Контрастивное обучение, в свою очередь, направлено на сохранение относительных расстояний между семантически близкими эмбеддингами, что позволяет более эффективно различать релевантные и нерелевантные векторы при поиске и извлечении информации. Комбинация этих двух подходов позволяет получить более устойчивые и точные векторные представления, адаптированные для работы с устройствами Compute-in-Memory (CiM).
Для повышения устойчивости векторных представлений к вариациям, присущим массивам Compute-in-Memory (CiM), в CQ-CiM используется инъекция шума. Данный метод позволяет моделировать неточности, возникающие в процессе аппаратной реализации CiM, такие как отклонения в сопротивлении памяти и другие источники шума. Внедрение контролируемого шума во время обучения позволяет алгоритму адаптироваться к этим вариациям, снижая чувствительность векторных представлений к аппаратным неточностям и обеспечивая более стабильную работу системы CiM. В результате, повышается надежность и точность операций поиска и сопоставления, выполняемых на базе CiM-устройств.
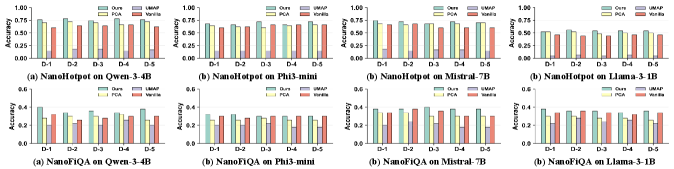
Применение разработанного подхода позволило добиться улучшения точности поиска до 7% по сравнению с базовыми методами на различных наборах данных, включая ARCChallenge, NanoHotpotQA, CQADupStackGisRetrieval и ArguAna. Данный прирост точности демонстрирует эффективность предложенной схемы одновременной компрессии и квантования векторных представлений для задач информационного поиска и является значимым результатом применительно к системам, использующим Compute-in-Memory (CiM) устройства.
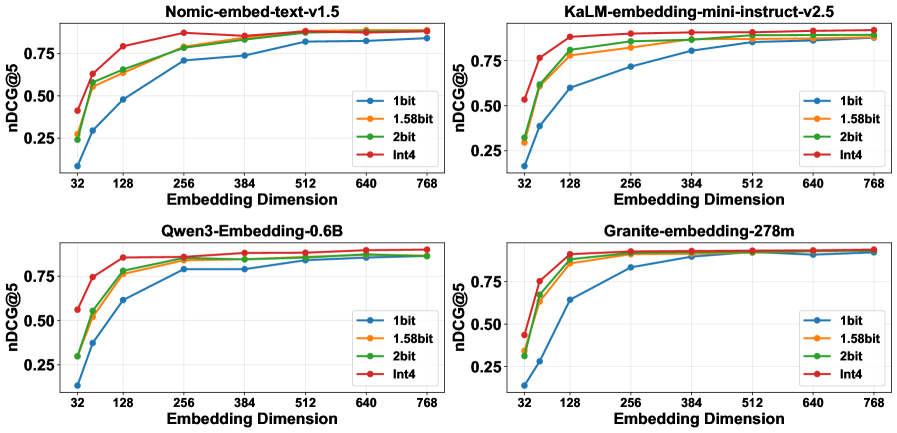
Универсальность и Производительность на Различных Моделях Вложений
Для всесторонней оценки применимости CQ-CiM проводилось тщательное тестирование с использованием различных моделей для создания векторных представлений предложений, включая All-MiniLM-L6-v2, Nomic-embed-text-v1.5, KaLM-embedding-mini-instruct-v2.5, Qwen3-Embedding-0.6B и Granite-embedding-278m. Данный подход позволил установить, что эффективность CQ-CiM сохраняется независимо от выбранной модели эмбеддингов, что подтверждает его универсальность и способность к адаптации к различным архитектурам систем поиска и извлечения информации. Использование столь широкого спектра моделей эмбеддингов обеспечило надежную проверку и подтвердило стабильность работы CQ-CiM в различных условиях, демонстрируя его потенциал для интеграции в широкий спектр приложений.
Исследования показали, что методика CQ-CiM демонстрирует стабильно высокую точность в задачах RAG (Retrieval-Augmented Generation) даже при моделировании различных условий работы устройств. Данное свойство особенно важно для практического применения, поскольку позволяет сохранять качество генерации ответов независимо от аппаратных ограничений или колебаний производительности. Стабильность работы CQ-CiM в различных условиях подтверждает её надежность и потенциал для интеграции в широкий спектр систем, требующих высокой точности и устойчивости к внешним факторам, что делает её ценным инструментом для повышения эффективности и масштабируемости RAG-систем.
Исследования показали, что адаптация моделей, насчитывающих сотни миллионов параметров, становится возможной всего за несколько минут благодаря применению CQ-CiM. Этот значительный прирост в скорости адаптации открывает новые возможности для быстрого развертывания и оптимизации систем поиска и извлечения информации (RAG). Возможность оперативно настраивать модели, не жертвуя при этом точностью, позволяет исследователям и разработчикам эффективно экспериментировать с различными архитектурами и параметрами, значительно сокращая время, необходимое для достижения оптимальной производительности. Данная особенность делает CQ-CiM особенно ценным инструментом в условиях, требующих быстрой итерации и масштабирования.
Адаптивность, демонстрируемая CQ-CiM, открывает значительные перспективы для интеграции с широким спектром систем извлечения информации на основе генеративного поиска (RAG). Данная технология позволяет эффективно масштабировать RAG-системы, оптимизируя их производительность и снижая вычислительные затраты, при этом не допуская снижения точности извлеченных данных. Возможность быстрой адаптации, даже с использованием моделей, содержащих сотни миллионов параметров, делает CQ-CiM ценным инструментом для разработчиков, стремящихся к созданию высокопроизводительных и масштабируемых систем обработки естественного языка, способных эффективно работать в различных условиях и с разными объемами данных.
Исследование, представленное в данной работе, демонстрирует стремление к оптимизации и адаптации систем к существующим аппаратным ограничениям. Подобный подход, направленный на «взлом» системы изнутри, а не на грубую силу, находит отклик в словах Андрея Николаевича Колмогорова: «Вероятность того, что эксперимент даст определённый результат, может быть оценена, даже если мы не знаем механизма, лежащего в основе этого результата». CQ-CiM, сфокусированный на формировании низкобитных представлений для Compute-in-Memory, иллюстрирует эту идею, поскольку позволяет оценить эффективность системы даже при упрощении представлений данных. Очевидно, что каждый «патч» — в данном случае, оптимизация алгоритма под конкретное «железо» — есть философское признание несовершенства любой модели, и постоянное стремление к её улучшению.
Что дальше?
Представленный подход CQ-CiM, безусловно, демонстрирует потенциал формования представлений для эффективного поиска в памяти. Однако, что произойдёт, если отказаться от самой идеи «сжатия»? Вместо того, чтобы насильно втискивать информацию в ограниченное аппаратное пространство, не стоит ли поискать принципиально новые архитектуры NVM, способные оперировать с полноразмерными, «раскованными» представлениями? Ограничение размерности — это компромисс, но не является ли это признаком слабости самой системы?
Следующий этап, вероятно, будет связан с преодолением узкого места, связанного с адаптацией LoRA. Что, если вместо тонкой настройки существующих моделей, разработать алгоритмы, способные создавать представления, изначально оптимизированные для архитектур CiM? Необходимо переосмыслить процесс обучения, отказавшись от парадигмы «модель + адаптация» в пользу «аппаратное-ориентированного» синтеза знаний.
И, конечно, нельзя игнорировать вопрос о робастности. Да, CQ-CiM повышает устойчивость к шумам, но что произойдёт, если изменить саму природу «шума»? Если вместо случайных ошибок, ввести в систему намеренные искажения, способные «обучать» систему новым, неожиданным способам обработки информации? В конце концов, хаос — это не всегда разрушение, иногда — это источник новых возможностей.
Оригинал статьи: https://arxiv.org/pdf/2602.20083.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Ядерный синтез и Искусственный Интеллект: Новый подход к проектированию реакторов
- Надежность ускорителей: от замысла до реализации
- Карта ошибок: Анатомия сбоев больших языковых моделей
- Вода под микроскопом: как машинное обучение предсказывает таяние льда
- Квантовые нейросети для реалистичной 3D-визуализации
- От миллиметровых волн к кубитному управлению: единый подход
- Данные в движении: Автоматизация подготовки данных с помощью искусственного интеллекта
- Автоматический анализ алгоритмов: новый подход к оптимизации
- Квантовые Загадки: От «Призрачного Действия на Расстоянии» к Суперкомпьютерам
- Пути информации в VideoLLM: визуализация логики видеопонимания
2026-02-24 23:52