Автор: Денис Аветисян
В статье представлена архитектура P-NTM, упрощенная версия нейронных машин Тьюринга, позволяющая существенно повысить эффективность параллельных вычислений без потери качества при решении алгоритмических задач.
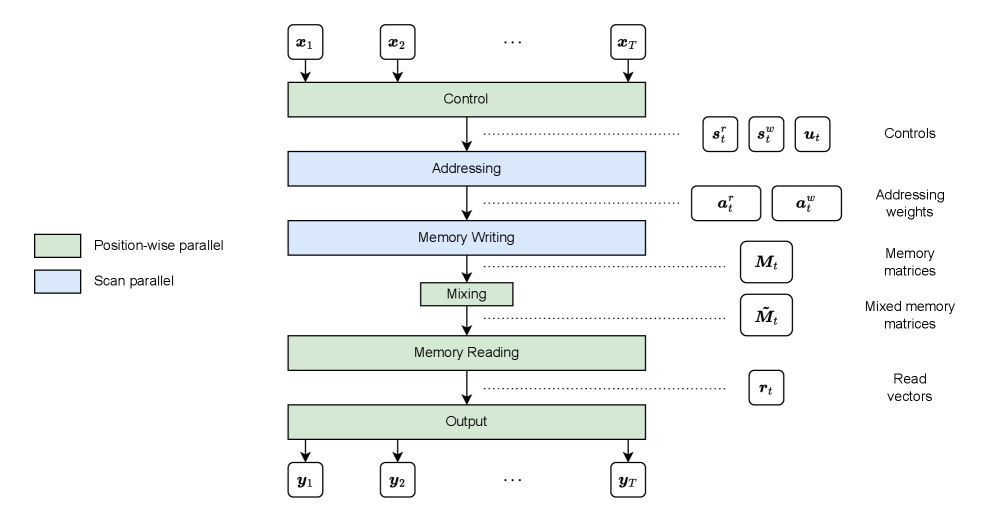
Разработка P-NTM направлена на оптимизацию работы рекуррентных нейронных сетей с использованием внешних блоков памяти для обработки долгосрочных зависимостей.
Несмотря на впечатляющие возможности нейронных сетей в решении сложных задач, эффективная реализация алгоритмических вычислений остается сложной задачей. В работе ‘Parallelizable Neural Turing Machines’ предложена упрощенная архитектура параллелизируемой машины Тьюринга (P-NTM), обеспечивающая эффективное параллельное выполнение операций сканирования памяти. Показано, что, несмотря на упрощения, P-NTM демонстрирует сопоставимую с оригинальной моделью обобщающую способность при решении алгоритмических задач, а также значительно превосходит стандартную реализацию НТМ по скорости обучения. Способна ли данная архитектура стать основой для создания более эффективных и масштабируемых нейронных сетей, способных к выражению широкого класса алгоритмов?
Параллельные Нейронные Машины Тьюринга: Новая Основа для Последовательностей
Традиционные рекуррентные нейронные сети, несмотря на свою эффективность в обработке последовательностей, испытывают значительные трудности при работе с долгосрочными зависимостями. Ограничение заключается в последовательной природе обработки информации — каждое новое входное значение обрабатывается только после завершения обработки предыдущего. Это создает “узкое место”, при котором информация о ранних шагах последовательности постепенно “забывается” по мере продвижения по ней, что препятствует установлению связей между отдаленными элементами. В результате, сети испытывают сложности в задачах, требующих запоминания и использования информации, полученной на больших временных интервалах, что ограничивает их возможности в понимании контекста и сложных последовательностей данных. Данная проблема является фундаментальным ограничением архитектуры и требует разработки новых подходов к моделированию последовательностей.
Архитектура P-NTM представляет собой принципиально новый подход к обработке информации, отходящий от последовательной обработки данных, свойственной традиционным рекуррентным нейронным сетям. Вдохновлённая концепцией машины Тьюринга, она позволяет осуществлять параллельные вычисления, что значительно повышает эффективность решения задач, требующих анализа больших объёмов данных и установления долгосрочных зависимостей. Вместо последовательного прохождения информации через скрытые состояния, P-NTM использует внешнюю память для хранения и извлечения данных, подобно тому, как машина Тьюринга использует ленту. Такой подход позволяет сети одновременно обрабатывать различные части информации, избегая «узких мест», возникающих при последовательной обработке, и открывая путь к созданию более мощных и гибких систем искусственного интеллекта.
Параллельные нейронные машины Тьюринга (P-NTM) решают проблему ограниченной памяти, свойственную традиционным рекуррентным нейронным сетям, благодаря интеграции внешней памяти. В отличие от сетей с фиксированным размером скрытого состояния, P-NTM способны хранить и извлекать информацию из внешнего хранилища, что позволяет им эффективно обрабатывать длинные последовательности данных и запоминать важные детали на протяжении всего процесса вычислений. Этот подход, вдохновленный машиной Тьюринга, позволяет сети не просто обрабатывать информацию последовательно, а активно «запоминать» и «вспоминать» данные по мере необходимости, значительно расширяя возможности обучения и решения сложных задач, требующих сохранения контекста на протяжении длительного времени. Благодаря этому, P-NTM демонстрируют повышенную эффективность в задачах, связанных с обработкой естественного языка, распознаванием речи и другими приложениями, где долгосрочная память играет ключевую роль.
Стабилизация процесса обучения и возможность построения глубоких архитектур в Parallel Neural Turing Machines (P-NTM) достигается благодаря применению предварительной нормализации и остаточных связей. Предварительная нормализация, применяемая к входным данным каждого слоя, позволяет контролировать градиенты и предотвращает их взрыв или затухание, что особенно важно при обучении глубоких сетей. В свою очередь, остаточные связи — соединения, напрямую передающие входные данные слоя на выход — обеспечивают беспрепятственный поток информации, обходя потенциальные проблемы с затуханием градиентов и позволяя модели эффективно учиться даже на очень сложных задачах. Такое сочетание методов позволяет P-NTM преодолевать ограничения традиционных рекуррентных нейронных сетей и эффективно использовать внешнюю память для обработки длинных последовательностей данных, открывая путь к созданию более мощных и устойчивых моделей искусственного интеллекта.
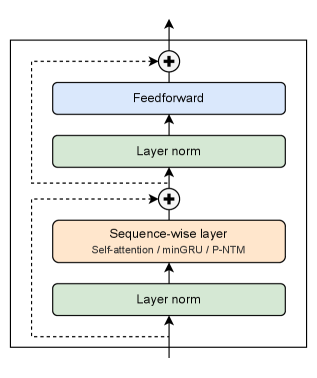
Эффективный Доступ к Памяти: Параллельные Методы Сканирования
Вычисление весов адресации является ключевым этапом в управлении операциями чтения и записи во внешней памяти P-NTM (Parallel Neural Turing Machine). Эти веса определяют, какие ячейки памяти будут прочитаны или перезаписаны в процессе обработки информации. Внешняя память P-NTM организована как матрица, и веса адресации, представляющие собой вероятностное распределение, указывают на степень «внимания» к каждой ячейке. Точность и эффективность вычисления этих весов напрямую влияют на скорость и точность работы всей системы, поскольку определяют, какие данные будут извлечены и использованы для дальнейших вычислений. Неправильно вычисленные веса могут привести к доступу к нерелевантным данным или к потере важной информации, что снижает производительность модели.
Вычисление весов адресации в P-NTM может быть значительно ускорено применением теоремы о свёртке. Данная теорема позволяет заменить операции прямой адресации и суммирования, требующие O(N) времени, на свёртку, которая может быть выполнена за O(N \log N) с использованием быстрого преобразования Фурье (FFT). В контексте P-NTM, веса адресации представляют собой последовательность, которую можно рассматривать как сигнал. Применение FFT к этому сигналу и к ядру свёртки, соответствующему паттерну доступа, позволяет вычислить свёртку, представляющую собой обновленные веса адресации. Этот подход особенно эффективен для больших объемов данных, поскольку сложность алгоритма снижается, что приводит к существенному сокращению времени вычислений и повышению производительности системы.
Алгоритмы параллельного сканирования (Parallel Scan) используются для эффективного вычисления префиксных сумм, являющихся ключевой операцией при обновлении весов адресации в P-NTM. В контексте работы с внешней памятью, вычисление префиксных сумм необходимо для определения смещений и адресов, к которым обращаются головки чтения/записи. Традиционное последовательное вычисление префиксных сумм имеет сложность O(N), где N — размер вектора весов. Параллельные алгоритмы сканирования позволяют снизить эту сложность до O(log N) или даже O(1) при использовании специализированного аппаратного обеспечения, что значительно ускоряет процесс обновления весов адресации и повышает общую производительность системы. \sum_{i=1}^{n} a_i является примером операции префиксной суммы, которая эффективно вычисляется с помощью Parallel Scan.
Логарифмический параллельный скан (Log-Space Parallel Scan) представляет собой оптимизацию алгоритма параллельного сканирования, направленную на повышение численной устойчивости и производительности при выполнении параллельных вычислений. Традиционный параллельный скан подвержен проблемам, связанным с накоплением ошибок округления при большом количестве операций сложения, особенно при работе с числами с плавающей точкой. Логарифмический подход решает эту проблему путем выполнения операций сложения в логарифмической области. Вместо непосредственного суммирования значений, вычисляется сумма их логарифмов: log(\sum_{i=1}^{n} x_i) = log(x_1) + log(exp(x_2-x_1)) + ... + log(exp(x_n-x_{n-1})) . Это позволяет избежать больших промежуточных значений и снижает риск переполнения или потери значимости, что обеспечивает более стабильные и точные результаты, особенно при обработке больших объемов данных и выполнении длительных вычислений.
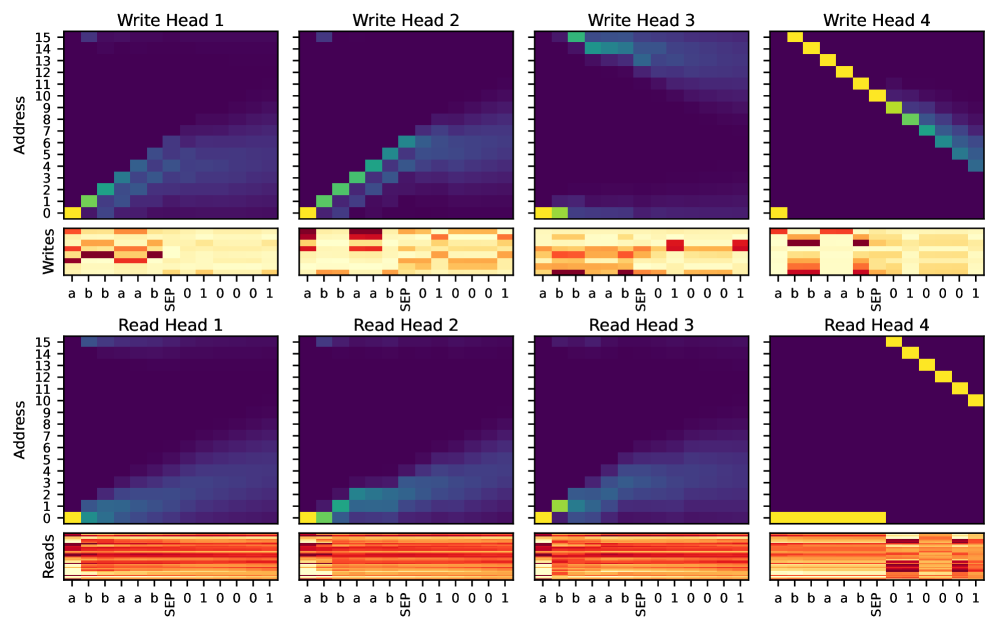
Последовательная Обработка и Управление Состоянием
Последовательная обработка входных данных является основой работы P-NTM при работе с временными рядами или последовательными данными. В P-NTM входные данные обрабатываются последовательно, что позволяет модели учитывать временную зависимость между элементами последовательности. Этот подход принципиально важен для задач, где порядок данных имеет значение, таких как обработка естественного языка, анализ временных рядов и распознавание речи. Каждый входной элемент обрабатывается поочередно, влияя на внутреннее состояние системы и модифицируя внешнюю память, что позволяет модели сохранять и использовать информацию из предыдущих шагов последовательности для формирования выходных данных.
Мини-GRU контроллер эффективно выполняет предварительную обработку входных данных и инициализацию внутреннего состояния в системе P-NTM. Он представляет собой упрощенную версию GRU (Gated Recurrent Unit), оптимизированную для снижения вычислительных затрат без существенной потери производительности. Предварительная обработка включает в себя преобразование входных данных в векторное представление, пригодное для последующей обработки. Инициализация внутреннего состояния заключается в создании начального вектора состояния, который отражает информацию о начале последовательности и служит отправной точкой для рекуррентных вычислений. Использование мини-GRU позволяет значительно ускорить процесс обработки последовательностей, особенно при работе с большими объемами данных, сохраняя при этом способность модели учитывать контекст и зависимости во входных данных.
Механизмы обновления памяти в P-NTM модифицируют внешнюю матрицу памяти на основе вычисленных весов адресации и входных данных. Веса адресации, полученные контроллером, определяют, какие части памяти будут прочитаны и обновлены. В процессе обновления, входные данные комбинируются с текущим содержимым памяти, используя эти веса, для создания новых значений, которые перезаписывают соответствующие ячейки внешней матрицы памяти. Этот процесс позволяет системе динамически адаптировать свою память к поступающей информации, сохраняя и обновляя релевантные данные для последующих операций и генерации выходных токенов.
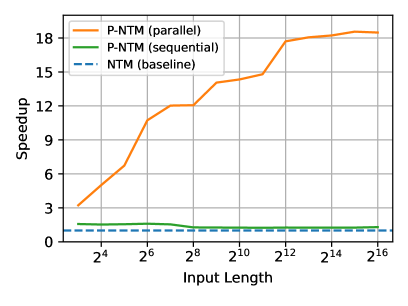
Генерация выходных токенов в P-NTM осуществляется на основе текущего состояния системы и извлеченных данных из внешней памяти. Эксперименты показывают, что P-NTM достигает сопоставимой точности со стандартными NTM при решении алгоритмических задач. При этом, обработка последовательностей длиной 65 536 элементов демонстрирует значительное ускорение работы P-NTM — до 18-кратного по сравнению со стандартными NTM.
В статье рассматривается упрощённая архитектура P-NTM, стремящаяся к эффективным параллельным вычислениям. Авторы, по сути, пытаются обуздать рекуррентные нейронные сети, чтобы те могли справляться с долгосрочными зависимостями, не превращаясь в вычислительный кошмар. Как метко заметила Грейс Хоппер: «Лучший способ предсказать будущее — это создать его». В данном случае, создаётся не будущее как таковое, а попытка заставить существующие алгоритмы работать быстрее и эффективнее. Идея параллелизации, представленная в P-NTM, лишь подтверждает, что рано или поздно любой элегантный теоретический подход столкнётся с суровой реальностью необходимости масштабирования и оптимизации. Иначе, даже самая красивая модель останется лишь академическим упражнением.
Что дальше?
Представленная архитектура P-NTM, несомненно, является шагом к уменьшению вычислительной неповоротливости рекуррентных сетей. Однако, иллюзия параллельности часто разбивается о суровую реальность последовательного доступа к памяти. Пока система способна демонстрировать сравнимую производительность на алгоритмических задачах, вопрос о масштабируемости на действительно больших объемах данных остаётся открытым. Ведь каждая «революционная» технология завтра станет техдолгом.
Более того, упрощения, внесённые в конструкцию NTM, неизбежно накладывают ограничения на выразительность модели. Возникает закономерный вопрос: какова цена этой упрощённой параллельности? Не окажется ли, что экономия вычислительных ресурсов достигается за счёт потери способности к решению более сложных задач? И, конечно, стоит помнить, что продакшен всегда найдёт способ сломать элегантную теорию.
Вероятно, дальнейшие исследования будут направлены на поиск компромиссов между параллельностью и выразительностью, возможно, за счёт разработки новых методов организации памяти и доступа к ней. А пока, можно констатировать, что эта работа — ещё одно напоминание о том, что legacy — это не просто старый код, а воспоминание о лучших временах, когда всё казалось проще. И, конечно, не стоит забывать, что мы не чиним продакшен — мы просто продлеваем его страдания.
Оригинал статьи: https://arxiv.org/pdf/2602.18508.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Ядерный синтез и Искусственный Интеллект: Новый подход к проектированию реакторов
- Карта ошибок: Анатомия сбоев больших языковых моделей
- Надежность ускорителей: от замысла до реализации
- Квантовые нейросети для реалистичной 3D-визуализации
- От миллиметровых волн к кубитному управлению: единый подход
- Искусственный интеллект на службе материалов: от открытий до инноваций
- Искусственный интеллект осваивает манипуляции: новая модель для роботов
- Квантовые вычисления: от Y2K к Q-Дню и дальше
- Автоматический анализ алгоритмов: новый подход к оптимизации
- Мощное моделирование жидкости: новый подход к методу решетчатых уравнений Больцмана
2026-02-25 03:04