Автор: Денис Аветисян
Новое исследование раскрывает фундаментальные закономерности, определяющие точность идентификации параметров и оценки неопределенности в сложных биологических моделях.
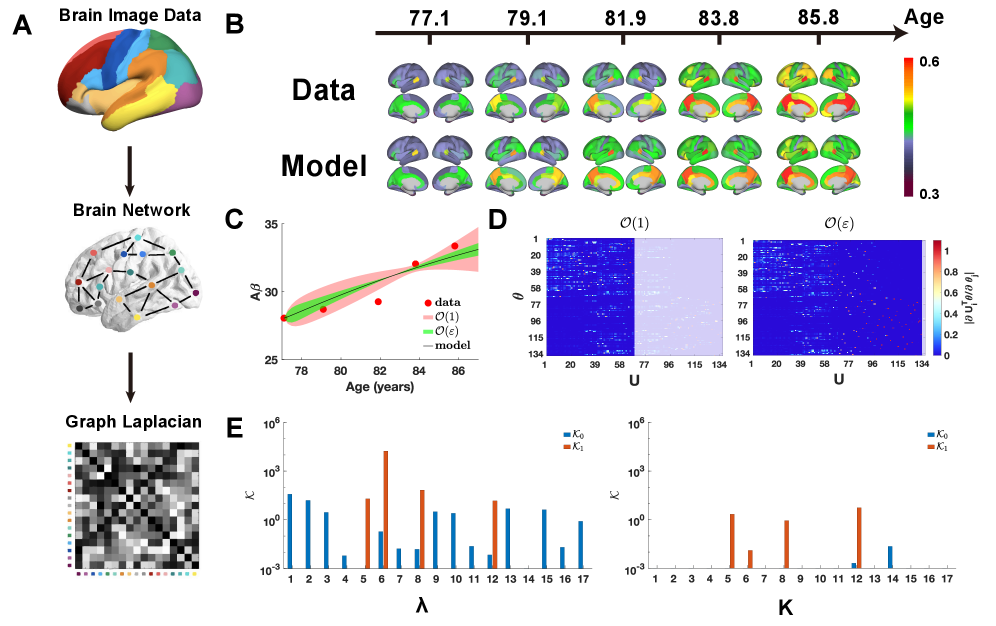
![Анализ идентификации параметров высшего порядка, интегрирующий разложение собственных значений и дополнительный минор Шюра, позволяет классифицировать параметры по иерархическим уровням, где порядок идентификации, отраженный в цветовой кодировке матрицы собственных значений - красный для нулевого [𝒪(1)], синий для первого [𝒪(ε)], и серый для второго [𝒪(ε2)] - определяет соответствующие комбинации параметров в матрице собственных векторов, а метрика [𝒦i] и фреймворк квантификации неопределённости высшего порядка позволяют оценить вклад неидентифицируемых параметров нулевого (красная область) и первого (синяя область) порядков в общую неопределённость предсказаний.](https://arxiv.org/html/2602.20495v1/x1.png)
Представлен вычислительный фреймворк для анализа законов масштабирования идентифицируемости параметров и надежной количественной оценки неопределенности в данных, используемых для построения биомоделей.
Несмотря на растущую сложность биологических моделей, оценка надежности их параметров и сопутствующая неопределенность остаются сложной задачей. В работе ‘Unveiling Scaling Laws of Parameter Identifiability and Uncertainty Quantification in Data-Driven Biological Modeling’ представлен вычислительный фреймворк, выявляющий закономерности масштабирования идентифицируемости параметров и обеспечивающий надежную количественную оценку неопределенности в сложных биологических моделях. На основе асимптотического анализа и синтеза информации Фишера с возмущенными матрицами Гессе, предложен иерархический подход к оценке идентифицируемости координат, применимый к динамике пространственно-временных процессов. Позволит ли этот подход повысить точность и надежность выводов, полученных на основе данных, и приблизить создание достоверных цифровых двойников биологических систем?
Идентификация параметров: вызов сложности
Математические модели играют ключевую роль в современной науке, однако процесс оценки параметров этих моделей часто сталкивается с проблемой идентифицируемости. Суть этой проблемы заключается в том, что даже при наличии достаточного объема данных, невозможно однозначно определить значения всех параметров модели. Это означает, что различные комбинации параметров могут приводить к одинаковому соответствию модели наблюдаемым данным, что делает невозможным выделение истинных значений и, как следствие, снижает надежность прогнозов и интерпретаций. Идентифицируемость становится особенно сложной задачей в случае сложных, нелинейных систем, где взаимосвязи между параметрами и данными могут быть весьма запутанными. Неспособность однозначно определить параметры ограничивает возможность использования модели для точного описания изучаемого явления и проверки выдвигаемых гипотез.
Традиционные методы оценки идентифицируемости, основанные исключительно на матрице Фишера F, зачастую оказываются недостаточными, особенно при работе со сложными, многомерными системами и нелинейными моделями. Матрица Фишера, будучи локальным показателем, эффективно определяет идентифицируемость лишь в окрестности конкретной точки параметров, и её применение в глобальном масштабе может приводить к ошибочным выводам. В высокоразмерных пространствах параметров и при наличии сложных взаимосвязей между переменными, эта локальная информация становится нерепрезентативной для всей модели. Нелинейность, в свою очередь, вносит искажения в оценку, поскольку матрица Фишера предполагает линейную зависимость между параметрами и данными. Таким образом, при анализе сложных систем требуется использование более продвинутых методов, учитывающих глобальные свойства модели и нелинейные эффекты, для обеспечения надежности оценки параметров и получения достоверных результатов моделирования.
Ограничения в определении параметров модели, вызванные проблемой идентифицируемости, непосредственно влияют на достоверность прогнозов и возможность извлечения осмысленных выводов из моделей, основанных на данных. Когда параметры модели не могут быть однозначно определены по имеющимся данным, любые предсказания становятся неопределенными и могут значительно отклоняться от реальных значений. Это особенно критично в областях, где принятие решений зависит от точности моделирования, таких как медицина, инженерия и экономика. Невозможность надежно оценивать параметры не только снижает доверие к результатам моделирования, но и затрудняет понимание основных механизмов, лежащих в основе исследуемых явлений, препятствуя тем самым прогрессу в научном познании и практическом применении моделей.
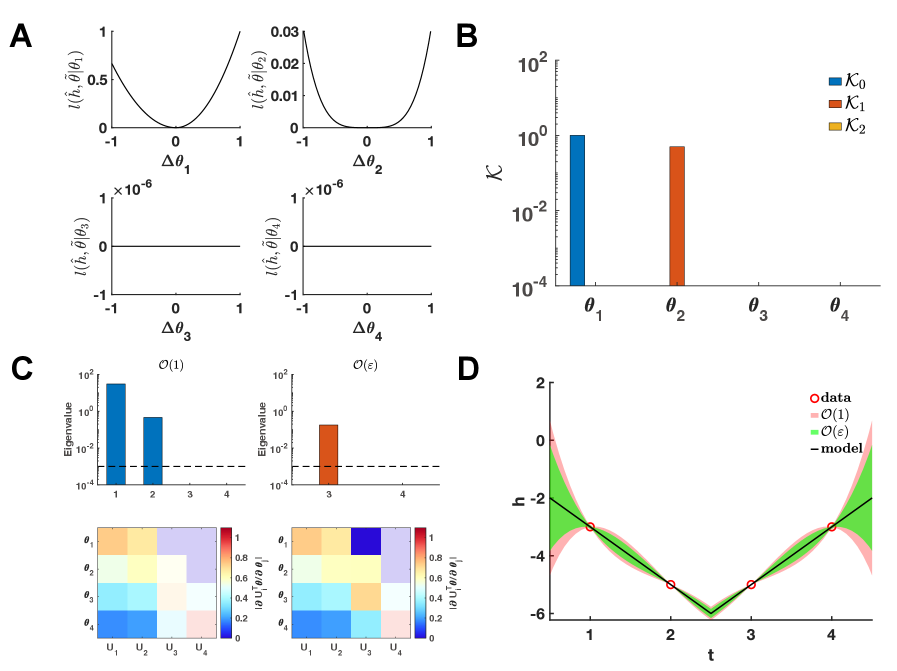
Расширение анализа идентифицируемости методами второго порядка
Матрица Гессе предоставляет более полное представление о кривизне поверхности правдоподобия, чем матрица информационного признака (FIM). В то время как FIM оценивает кривизну только в точке максимума правдоподобия, матрица Гессе учитывает вторые производные функции правдоподобия по всем параметрам модели. Это позволяет оценить локальную чувствительность функции правдоподобия к изменениям параметров во всех направлениях, а не только в направлении, определяемом FIM. \nabla^2 log(L) (Гессиан) содержит информацию о форме поверхности правдоподобия, выявляя как глобальные, так и локальные особенности, такие как седловые точки и области с низкой кривизной, которые не могут быть обнаружены с помощью только FIM. Это особенно важно при анализе сложных моделей, где поверхность правдоподобия может быть невыпуклой или иметь несколько локальных максимумов.
Разложение на собственные значения (EVD) как матрицы Фишера (FIM), так и матрицы Гессе позволяет получить детальную характеристику ландшафта идентифицируемости. Собственные значения матрицы Фишера отражают кривизну функции правдоподобия вдоль соответствующих направлений параметров, а собственные векторы указывают эти направления. Анализ собственных значений и собственных векторов матрицы Гессе предоставляет информацию о локальной чувствительности функции правдоподобия и позволяет выявить направления, в которых параметры плохо идентифицируемы, то есть, небольшие изменения параметров приводят к значительным изменениям в функции правдоподобия. Низкие собственные значения указывают на направления с высокой неопределенностью, в то время как собственные векторы, соответствующие этим значениям, определяют соответствующие параметры, которые сложно оценить точно. Комбинирование EVD для обеих матриц обеспечивает более полное понимание идентифицируемости модели, позволяя выявить как общие, так и специфические направления неопределенности.
Анализ Шура дополнения расширяет возможности анализа идентифицируемости, предоставляя вычислительно эффективный способ определения обратимости соответствующих матриц, что позволяет напрямую количественно оценить идентифицируемость параметров модели. Вместо непосредственного вычисления обратной матрицы, что может быть затратным, анализ Шура дополнения позволяет оценить ее существование на основе блочного детерминанта, вычисляемого для подматрицы исходной матрицы. Это особенно полезно при анализе больших моделей, где прямые методы могут быть непрактичными. Использование Шура дополнения позволяет определить, является ли подпространство параметров идентифицируемым, не вычисляя полные обратные матрицы, тем самым значительно снижая вычислительную сложность и повышая эффективность анализа.
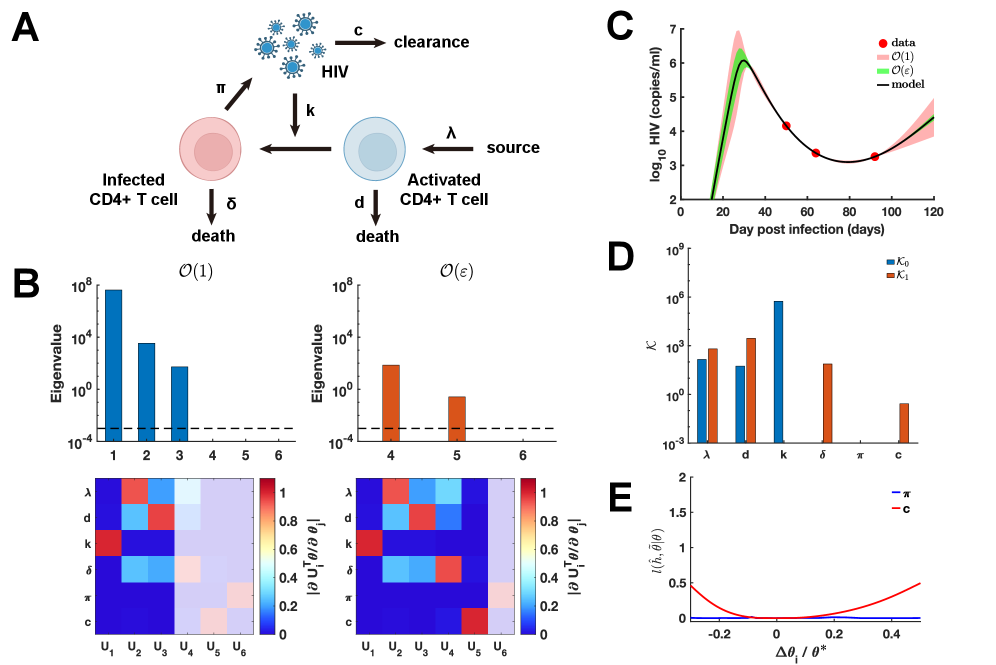
Валидация разработанного подхода на биологических моделях
Модель кинетики ВИЧ используется в качестве общепринятого эталона для оценки параметров, позволяя проверить и уточнить результаты анализа идентифицируемости. Данная модель, широко известная и изученная в области математической биологии, предоставляет возможность сравнения эффективности предложенного метода с существующими подходами. Использование модели ВИЧ гарантирует воспроизводимость результатов и служит отправной точкой для оценки применимости разработанного фреймворка к более сложным биологическим системам. Проверка на этой модели позволяет установить базовый уровень точности и надежности, необходимый для дальнейшей валидации на других, менее изученных моделях.
Применение разработанного фреймворка к модели амилоида β, описывающей распределение β-амилоида в головном мозге, подтверждает его универсальность и применимость к различным биологическим системам. Модель амилоида β, характеризующая динамику образования и распространения амилоидных бляшек, представляет собой сложную нелинейную систему, требующую точной оценки параметров для адекватного моделирования патогенеза болезни Альцгеймера. Успешное применение фреймворка к этой модели демонстрирует его способность к идентификации параметров в контексте различных биологических процессов, отличных от кинетической модели ВИЧ, и расширяет область его потенциального использования в биомедицинских исследованиях.
Метрика Ключевой Идентифицируемости (KI) использует анализ Шура для количественной оценки порядка идентифицируемости параметров модели. Этот подход позволяет классифицировать параметры по иерархическому принципу: «Нулевая», «Первая» и «Неидентифицируемая». В отличие от традиционных методов, основанных на оценке чувствительности или профилях правдоподобия, метрика KI предоставляет более детальную информацию о структуре идентифицируемости, выявляя параметры, которые могут быть не идентифицированы даже при использовании сложных алгоритмов оптимизации. Вычисление KI основано на определителе матрицы Шура, построенной на основе матрицы ковариации параметров, и позволяет оценить степень, в которой изменения параметров влияют на наблюдаемые данные. KI = det(Schur\ Complement) Значение KI близкое к нулю указывает на неидентифицируемость, в то время как более высокие значения соответствуют параметрам, которые могут быть надежно оценены.
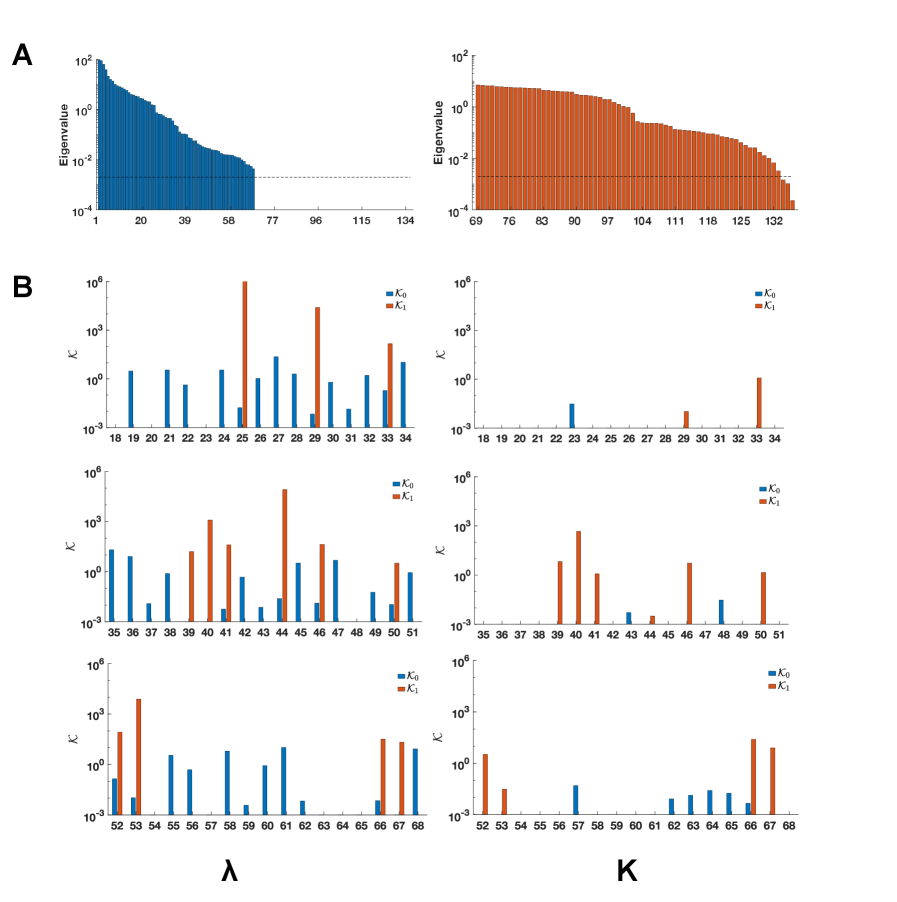
К надежному учету неопределенностей: перспективы и влияние
Законы масштабирования демонстрируют, как изменяется идентифицируемость модели в зависимости от её сложности и объема доступных данных. Исследования показывают, что увеличение числа параметров модели не всегда приводит к повышению точности предсказаний, особенно при ограниченном количестве данных. Более того, существует критический порог сложности, после которого модель становится чрезмерно чувствительной к небольшим изменениям в данных, что приводит к неустойчивым результатам. Эти закономерности позволяют целенаправленно разрабатывать модели оптимальной сложности, избегая переобучения и повышая надежность прогнозов. Планирование экспериментов также выигрывает от этих знаний, поскольку позволяет определить, какой объем данных необходим для адекватной идентификации параметров модели и достижения желаемой точности предсказаний. Таким образом, законы масштабирования представляют собой мощный инструмент для рационального моделирования и эффективного использования экспериментальных данных.
Современные методы количественной оценки неопределенностей (UQ) выходят за рамки простой идентификации параметров, учитывая вклад неидентифицируемых величин в общую предсказательную неопределенность. Данный подход особенно важен при моделировании сложных биологических процессов, таких как динамика ВИЧ-инфекции и распространение белка амилоида-β, где полная идентифицируемость параметров зачастую недостижима. Учитывая влияние неидентифицируемых параметров, эти методы позволяют более точно моделировать переходные фазы этих процессов, повышая надежность прогнозов и позволяя делать более обоснованные выводы, несмотря на ограниченность данных. В отличие от традиционных подходов, фокусирующихся исключительно на хорошо определенных параметрах, усовершенствованные UQ-методики обеспечивают более полное и реалистичное представление о неопределенности модели.
Признание и количественная оценка неопределенностей позволяют создавать более надежные модели и делать обоснованные прогнозы, даже при ограниченном объеме данных. Исследования показывают, что игнорирование неопределенностей в параметрах моделей может привести к значительным ошибкам в предсказаниях, особенно при экстраполяции за пределы экспериментальных данных. Количественная оценка неопределенностей позволяет оценить диапазон возможных значений параметров, что, в свою очередь, позволяет определить границы предсказаний и оценить достоверность полученных результатов. Такой подход особенно важен в областях, где последствия ошибочных предсказаний могут быть серьезными, например, в медицине или экологии. Разработка методов для эффективной оценки и представления неопределенностей является ключевым шагом к созданию более точных и полезных моделей, способных адаптироваться к новым данным и предоставлять надежную информацию даже в условиях неполноты знаний.
Данное исследование демонстрирует, что сложность модели не всегда ведет к большей точности. Авторы предлагают подход, основанный на выявлении масштабируемых закономерностей идентифицируемости параметров, что позволяет упростить модели, сохранив при этом их предсказательную силу. Этот процесс напоминает скульптурную работу: отсечение лишнего для выявления истинного смысла. Как заметил Томас Кун: «Научная революция есть не просто накопление новых знаний, а фундаментальное изменение в способе восприятия мира». В контексте данной работы, это означает переход от сложных, трудноинтерпретируемых моделей к более простым, но при этом точно отражающим биологическую реальность.
Что дальше?
Представленная работа, стремясь к ясности в сложном ландшафте идентификации параметров и оценки неопределенности, неизбежно обнажает новые области для исследования. Настоящая победа не в построении все более изощренных моделей, а в признании пределов их применимости. Очевидно, что асимптотические приближения, хоть и полезные, не всегда отражают реальное поведение систем с сильно выраженными нелинейностями и сложной пространственно-временной динамикой. Ключевым направлением представляется разработка методов, позволяющих оценивать достоверность этих приближений и, при необходимости, отказываться от них.
Попытки масштабировать предложенный подход к моделям, включающим стохастические процессы и нечеткие данные, потребуют не только вычислительных ресурсов, но и философского переосмысления понятия «идентифицируемость». В конечном счете, система, требующая подробных инструкций для интерпретации результатов, уже проиграла. Более элегантным решением видится переход к моделям, способным самосогласованно оценивать свою собственную неопределенность и предоставлять информацию в виде, доступном для непосредственного понимания.
Понятность — это вежливость. Будущие исследования должны сосредоточиться не на увеличении количества параметров, а на их уменьшении, не на усложнении моделей, а на их упрощении. Истинный прогресс заключается в создании инструментов, которые позволяют извлекать максимальную пользу из минимального количества информации, а не наоборот. В противном случае, все усилия по идентификации параметров и оценке неопределенности рискуют превратиться в бессмысленную гонку за иллюзорной точностью.
Оригинал статьи: https://arxiv.org/pdf/2602.20495.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Ядерный синтез и Искусственный Интеллект: Новый подход к проектированию реакторов
- Карта ошибок: Анатомия сбоев больших языковых моделей
- Надежность ускорителей: от замысла до реализации
- Квантовые нейросети для реалистичной 3D-визуализации
- Квантовые схемы: универсальность и сложность
- Понимание видео: новый вызов для искусственного интеллекта
- Вода под микроскопом: как машинное обучение предсказывает таяние льда
- Обучение с подкреплением: новый взгляд на самообучение
- Искуственный интеллект: хрупкость смысла в сложных задачах
- Память как у живого мозга: новый подход к локальному AI
2026-02-25 23:17