Автор: Денис Аветисян
Исследование посвящено оценке надежности цифровых доказательств, обнаруженных с помощью больших языковых моделей, и предлагает новый подход к их валидации.
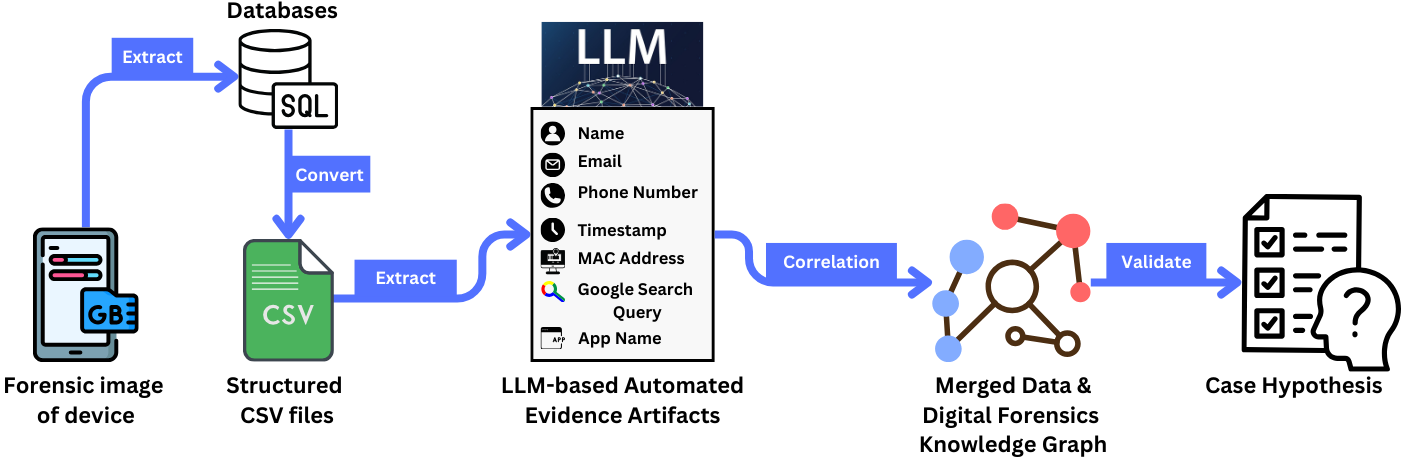
Представлена криминалистическая система, объединяющая большие языковые модели, графы знаний и детерминированные уникальные идентификаторы для автоматизированного обнаружения, извлечения и проверки артефактов.
Несмотря на растущую интеграцию искусственного интеллекта в цифровую криминалистику, вопросы надежности извлекаемых им доказательств остаются критически важными. В данной работе, ‘Evaluating the Reliability of Digital Forensic Evidence Discovered by Large Language Model: A Case Study’, предложен и оценен структурированный подход, сочетающий большие языковые модели (LLM) с графами знаний и детерминированными идентификаторами (UID) для автоматизации обнаружения и валидации артефактов. Полученные результаты демонстрируют высокую точность извлечения доказательств (более 95%), обеспечение цепочки хранения и контекстуальной согласованности, что способствует повышению юридической обоснованности AI-ассистируемой криминалистики. Сможет ли предложенная методология стать стандартом для обеспечения достоверности и допустимости цифровых доказательств, полученных с помощью искусственного интеллекта?
Преодоление границ: вызовы масштабируемости и надежности в цифровой криминалистике
Современные цифровые расследования сталкиваются с беспрецедентным ростом объемов и сложности данных, что создает серьезные препятствия для традиционных методов. Ранее эффективные подходы, основанные на ручном анализе, сегодня зачастую не справляются с потоком информации, приводя к возникновению «узких мест» и задержкам в процессе расследования. Огромные объемы данных, включая логи, сетевой трафик и образы дисков, требуют колоссальных временных затрат на обработку и анализ. В результате, важные улики могут быть упущены из виду, а сроки расследования существенно затянуты. Это особенно актуально в случаях, связанных с киберпреступностью и крупномасштабными утечками данных, где скорость и точность анализа имеют решающее значение. Необходимость в автоматизации и масштабируемых решениях становится все более очевидной для эффективного противодействия современным цифровым угрозам.
Неизменное обеспечение целостности и достоверности цифровых доказательств является первостепенной задачей в процессе цифровой криминалистики. Однако, полагаясь на ручные процедуры, исследователи неизбежно сталкиваются с риском человеческих ошибок и несоответствий. Возможность случайного изменения, повреждения или неправильной интерпретации данных представляет собой серьезную угрозу для юридической значимости полученных результатов. Даже незначительные отклонения в процессе обработки доказательств могут поставить под сомнение всю цепочку хранения и, как следствие, привести к признанию доказательств недопустимыми в суде. Поэтому, разработка и внедрение строгих протоколов, автоматизированных инструментов верификации и постоянный контроль качества становятся критически важными для обеспечения надежности и беспристрастности цифровой криминалистики.
Автоматизация и валидация в рамках криминалистического анализа цифровых данных становятся ключевым требованием современной практики. Ручные процессы, несмотря на свою точность в отдельных случаях, не способны эффективно справляться с экспоненциально растущими объемами информации и сложностью цифровых следов. Внедрение автоматизированных инструментов позволяет существенно ускорить обработку данных, выявлять закономерности и артефакты, которые могут быть упущены при ручном анализе. Однако, автоматизация сама по себе недостаточна; необходима строгая валидация каждого этапа обработки, чтобы гарантировать целостность и достоверность полученных результатов. Системы валидации, включающие контроль хеш-сумм, верификацию алгоритмов и независимую проверку результатов, позволяют минимизировать риски ошибок и фальсификаций, обеспечивая надежность доказательств, представленных в суде. Таким образом, сочетание автоматизации и валидации — это не просто повышение эффективности, а фундаментальное условие для обеспечения справедливости и законности в цифровой эпохе.
Интеллектуальный каркас: LLM-основанная структура для усовершенствования криминалистических артефактов
Предлагаемая LLM-основанная структура для работы с цифровыми доказательствами использует большие языковые модели (LLM) для уточнения и валидации артефактов, выявляя и устраняя несоответствия, а также повышая общее качество данных. LLM применяются для анализа извлеченных данных, проверки их целостности и согласованности, а также для выявления потенциальных ошибок или неточностей, которые могут возникнуть в процессе сбора или обработки. Этот подход позволяет автоматизировать часть рутинной работы аналитиков, снизить вероятность человеческих ошибок и повысить надежность результатов цифровой экспертизы. Валидация артефактов включает в себя проверку соответствия данных известным форматам, выявление аномалий и противоречий, а также сопоставление данных с внешними источниками для подтверждения их достоверности.
Ключевым аспектом предложенной системы является применение стандартизированных методов извлечения данных. Необходимость этого обусловлена тем, что для эффективной обработки и анализа больших объемов криминалистических артефактов моделями LLM требуется единообразный формат представления данных. Различные источники и типы артефактов часто имеют гетерогенные форматы, что затрудняет их интерпретацию и обработку LLM. Стандартизация включает в себя нормализацию временных меток, унификацию текстовых кодировок, и приведение числовых данных к единым единицам измерения. Это обеспечивает совместимость данных и позволяет LLM выполнять точный анализ и выявлять закономерности, которые могли бы быть упущены при работе с несогласованными данными.
В процессе усовершенствования артефактов в рамках предложенной системы, каждому артефакту присваивается уникальный идентификатор (UID) посредством хеширования SHA-256. Использование SHA-256 гарантирует криптографическую стойкость и однозначную идентификацию каждого элемента данных. Этот подход обеспечивает возможность отслеживания происхождения артефакта, подтверждения его целостности и предотвращения несанкционированных изменений, что критически важно для поддержания достоверности результатов цифровой криминалистики. Генерация UID осуществляется на этапе обработки артефакта и сохраняется как неотъемлемая часть метаданных.
Предлагаемый фреймворк не функционирует изолированно, активно используя Граф Знаний Цифровой Судебной Экспертизы (DFKG) для моделирования взаимосвязей между артефактами. DFKG представляет собой структурированное хранилище знаний, которое позволяет устанавливать логические связи между различными цифровыми доказательствами, такими как файлы, записи в реестре и сетевой трафик. Использование DFKG позволяет LLM не просто анализировать отдельные артефакты, но и учитывать контекст их взаимодействия, повышая точность и полноту результатов судебно-технической экспертизы. Моделирование взаимосвязей осуществляется посредством определения и хранения атрибутов, описывающих связи между артефактами, что обеспечивает возможность автоматизированного вывода новых фактов и гипотез.
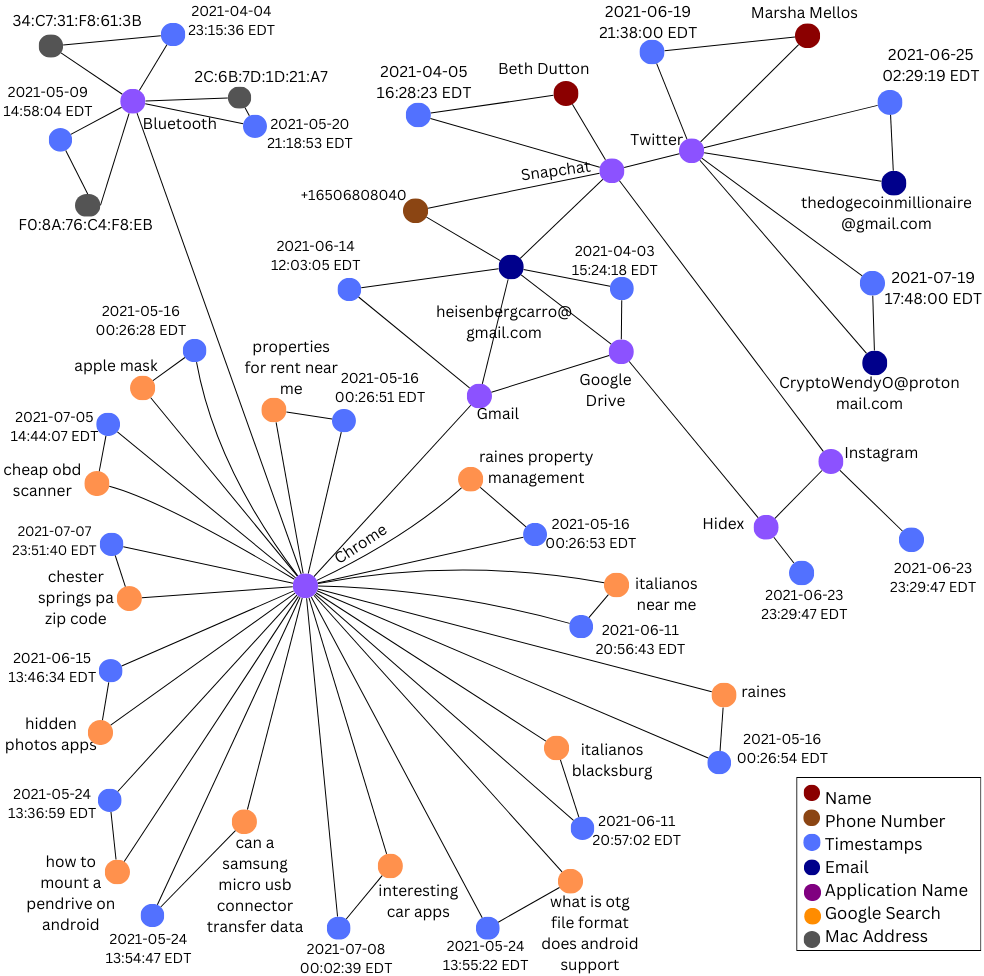
Оценка надежности: ключевые метрики для криминалистической валидации
В рамках разработанной системы для оценки качества проведения криминалистического анализа используется набор метрик, включающий точность извлечения доказательств (EEA) и точность идентификации криминалистических артефактов (FAP). В ходе тестирования была достигнута точность извлечения доказательств (EEA) на уровне 95.24%, что основано на успешном извлечении 40 из 42 потенциальных объектов. Точность идентификации криминалистических артефактов (FAP) также составила 95.24%, что отражает долю корректно классифицированных артефактов от общего числа протестированных.
Метрики Forensic Artifact Recall (FAR) и Knowledge Graph Connectivity Accuracy (KGCA) дополняют друг друга при оценке полноты и целостности связей в графе знаний DFKG. В ходе тестирования достигнут показатель FAR в 100%, что гарантирует обнаружение всей релевантной доказательной информации. KGCA, измеряющий корректность установленных связей между артефактами, составил 94.44%, основанный на 68 правильно установленных связях из общего числа 72. Данные показатели демонстрируют высокую степень охвата и точности представления информации в DFKG.
Обеспечение целостности данных и релевантности на протяжении всего жизненного цикла анализа является критически важным аспектом любой криминалистической экспертизы. В рамках разработанного подхода достигнута 100% применимость принципов соблюдения цепочки хранения (Chain of Custody Adherence, CCA), что гарантирует полную прослеживаемость артефактов от момента сбора до представления результатов. Это означает, что каждый шаг обработки доказательств, включая время, место и исполнителя, задокументирован и верифицирован, исключая возможность несанкционированных изменений или потери данных. Полная прослеживаемость является необходимым условием для обеспечения юридической силы и достоверности криминалистических заключений.
Представленные метрики не являются просто показателями; они служат критически важными ориентирами для подтверждения достоверности результатов криминалистического анализа. Общий показатель F1 для артефактов (FAF1), равный 97.56%, объединяет в себе точность (precision) и полноту (recall), что обеспечивает надежную и всестороннюю оценку производительности системы. Высокий F1-Score указывает на сбалансированную эффективность, минимизируя как ложноположительные, так и ложноотрицательные результаты при идентификации и классификации криминалистических артефактов, что необходимо для обеспечения юридической значимости полученных данных.
Расширение горизонтов: применение и перспективы развития
Разработанный на основе больших языковых моделей (LLM) криминалистический фреймворк демонстрирует высокую применимость в различных сценариях, особенно в сфере мобильной криминалистики. Он позволяет значительно ускорить и повысить точность анализа сложных мобильных устройств, автоматически извлекая, обрабатывая и интерпретируя данные из разнообразных источников. Вместо ручного, трудоемкого поиска релевантной информации, система способна выявлять ключевые артефакты и связи, предоставляя следователям готовые к анализу результаты. Это не только сокращает время расследования, но и минимизирует вероятность человеческой ошибки, повышая надежность полученных доказательств и способствуя более эффективному раскрытию преступлений, связанных с использованием мобильных технологий.
Разработанная система позволяет автоматически формировать стандартизированные отчеты в формате STIX, что значительно упрощает обмен информацией об угрозах и способствует более эффективному взаимодействию между специалистами по информационной безопасности. Использование STIX обеспечивает унифицированное представление данных о кибератаках, включая информацию об используемых инструментах, тактиках злоумышленников и индикаторах компрометации. Это, в свою очередь, позволяет быстро распространять полученные знания между различными организациями и исследовательскими группами, ускоряя процесс выявления и нейтрализации новых угроз, а также повышая общую осведомленность о текущем ландшафте кибербезопасности. Автоматизация процесса создания отчетов в STIX снижает вероятность ошибок, связанных с ручным вводом данных, и обеспечивает более полную и достоверную картину происходящего.
Автоматизация ключевых этапов криминалистического процесса, обеспечиваемая данной системой, позволяет следователям переключить внимание с рутинных операций на более сложные задачи анализа и принятия решений. Вместо того чтобы тратить время на извлечение и первичную обработку данных, специалисты могут сосредоточиться на интерпретации результатов, выявлении закономерностей и построении целостной картины происходящего. Это не только значительно повышает эффективность расследований, но и снижает вероятность ошибок, связанных с человеческим фактором, позволяя более оперативно реагировать на возникающие угрозы и обеспечивать более надежную защиту от киберпреступлений. Такой подход высвобождает ресурсы для стратегического анализа и экспертной оценки, что особенно важно в условиях постоянно растущего объема и сложности цифровых данных.
В дальнейшем планируется расширение возможностей разработанной системы за счет адаптации к новым и постоянно появляющимся форматам данных, что позволит анализировать все более широкий спектр цифровых доказательств. Параллельно с этим, ведется работа над усовершенствованием метрик, используемых для оценки надежности и точности проведенного анализа. Уточнение этих показателей необходимо для обеспечения объективности и бесспорности результатов, предоставляемых системой, а также для повышения доверия к автоматизированным инструментам в сфере цифровой криминалистики. Особое внимание уделяется разработке методов количественной оценки неопределенности, возникающей при анализе неполных или поврежденных данных, что позволит более точно интерпретировать полученные результаты и делать обоснованные выводы.
Исследование демонстрирует стремление к автоматизации процесса обнаружения и валидации цифровых артефактов, что, несомненно, усложняет задачу обеспечения их надёжности. Авторы предлагают интеграцию больших языковых моделей со знаниями, представленными в графах, и использование детерминированных идентификаторов, стремясь к созданию более прозрачного и контролируемого процесса. Это напоминает о словах Дональда Кнута: «Преждевременная оптимизация — корень всех зол». Попытки создать слишком сложные системы, не учитывающие фундаментальную простоту и необходимость верификации каждого шага, могут привести к ещё большим проблемам с юридической допустимостью доказательств. Важность концепции цепочки хранения данных, представленная в работе, подчёркивает необходимость не просто извлечь информацию, но и доказать её целостность на каждом этапе.
Что Дальше?
Представленная работа, хотя и демонстрирует потенциал интеграции больших языковых моделей в цифровую криминалистику, лишь приоткрывает дверь в область, где автоматизация сталкивается с необходимостью абсолютной достоверности. Вопрос не в том, может ли модель обнаружить артефакт, а в том, насколько надежно она может подтвердить его целостность и прослеживаемость. Детерминированные UID, безусловно, являются шагом в правильном направлении, однако истинная сложность заключается в поддержании их однозначности на протяжении всей цепочки хранения, особенно в динамично меняющихся цифровых экосистемах.
Будущие исследования должны сосредоточиться не на увеличении скорости извлечения данных, а на разработке методов верификации, устойчивых к намеренному искажению. Необходимо разработать инструменты, способные не только идентифицировать артефакты, но и оценивать степень их модификации, учитывая контекст и вероятные векторы атаки. Простое обнаружение — это лишь начало; истинная ценность заключается в способности предоставить неопровержимые доказательства.
В конечном счете, успех данной области зависит от признания фундаментальной истины: автоматизация не освобождает от необходимости критического мышления. Иллюзия совершенства, создаваемая алгоритмами, должна быть развеяна. Ясность, а не скорость, является высшей добродетелью. И, возможно, именно в этом парадоксе кроется путь к истинной надежности цифровых доказательств.
Оригинал статьи: https://arxiv.org/pdf/2602.20202.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Ядерный синтез и Искусственный Интеллект: Новый подход к проектированию реакторов
- Карта ошибок: Анатомия сбоев больших языковых моделей
- Надежность ускорителей: от замысла до реализации
- Квантовые нейросети для реалистичной 3D-визуализации
- Мощное моделирование жидкости: новый подход к методу решетчатых уравнений Больцмана
- Нейросеть предсказывает сродство антител к COVID-19
- Память как у живого мозга: новый подход к локальному AI
- Искусственный интеллект на службе материалов: от открытий до инноваций
- Кто несет ответственность за ИИ: новый взгляд на причинно-следственные связи
- Квантовый транспорт в сложных системах: новый подход к моделированию
2026-02-26 02:37