Автор: Денис Аветисян
Исследователи предлагают Duo++, инновационную методику, объединяющую принципы диффузионных моделей и эффективное обучение по учебному плану для улучшения качества и скорости генерации дискретных данных.
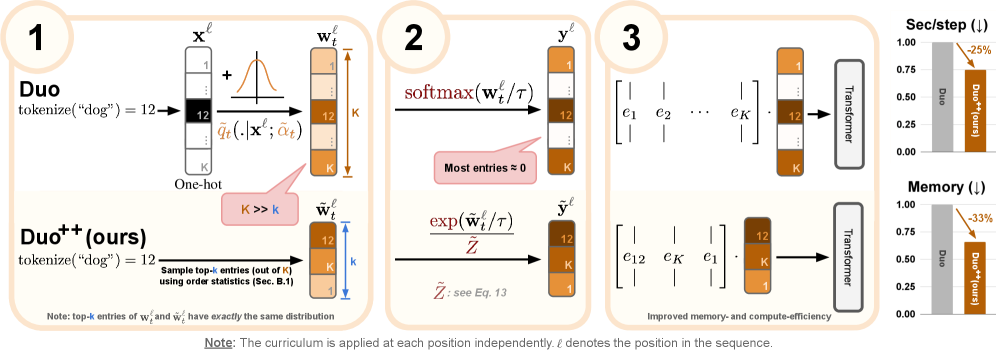
В статье представлен метод Duo++, использующий суперпозицию апостериорных распределений и стратегию эффективного обучения для дискретных диффузионных моделей.
Несмотря на успехи дискретных диффузионных моделей в задачах генерации и управления, их качество часто стагнирует при увеличении числа шагов семплирования. В работе ‘The Diffusion Duality, Chapter II: Ψ-Samplers and Efficient Curriculum’ предложен новый подход, основанный на семействе семплеров Predictor-Corrector (PC) и эффективной стратегии обучения с формированием учебного плана, позволяющий преодолеть эти ограничения. Предложенные методы демонстрируют превосходство над традиционными подходами, улучшая качество генерируемых данных и снижая вычислительные затраты как в языковых, так и в графических задачах. Может ли предложенный подход стать основой для нового поколения дискретных диффузионных моделей, способных эффективно обрабатывать сложные данные и обеспечивать высокую производительность?
Преодолевая Ограничения Марковских Моделей: Вызов Дискретных Данных
Традиционные диффузионные модели демонстрируют впечатляющие результаты при работе с непрерывными данными, такими как аудио или изображения, где изменения происходят плавно и постепенно. Однако, при переходе к дискретным данным, таким как текст или пиксельные изображения, эти модели сталкиваются с существенными трудностями. Причина кроется в природе дискретных данных — каждый элемент представляет собой отдельную, качественно различную единицу, и небольшое изменение может привести к резкому скачку в пространстве состояний. Это создает проблемы при моделировании процесса диффузии, поскольку стандартные методы, основанные на непрерывных изменениях, оказываются неэффективными для захвата сложных зависимостей и структуры, присущих дискретным данным. В результате, генерация когерентных и реалистичных дискретных последовательностей становится значительно более сложной задачей, требующей разработки специализированных подходов.
Ограничение, известное как марковское предположение — идея о том, что будущее состояние системы определяется исключительно её текущим состоянием — существенно затрудняет моделирование дискретных последовательностей, таких как текст или изображения. В отличие от непрерывных данных, где небольшие изменения в настоящем оказывают лишь незначительное влияние на будущее, в дискретных последовательностях связи могут быть нелокальными и охватывать значительные отрезки данных. Предположение о зависимости только от текущего момента игнорирует эти долгосрочные взаимосвязи, что приводит к генерации последовательностей, лишенных связности и логической последовательности. Например, в предложении смысл слова часто зависит от слов, расположенных далеко от него, и марковская модель не способна уловить эту зависимость, что сказывается на качестве генерируемого текста. Преодоление этого ограничения требует разработки новых методов моделирования, способных учитывать долгосрочные зависимости в дискретных данных.
Ограничения, связанные с марковским предположением, существенно влияют на качество генерируемых дискретных данных, таких как текст или изображения. Неспособность улавливать долгосрочные зависимости в последовательностях приводит к фрагментарности и несогласованности результатов. В связи с этим, исследователи активно разрабатывают альтернативные методы моделирования, выходящие за рамки традиционных диффузионных моделей. Эти новые подходы направлены на эффективное кодирование и использование информации о более отдаленных элементах последовательности, что необходимо для создания связных и реалистичных дискретных данных. Особое внимание уделяется архитектурам, способным улавливать контекст и взаимосвязи между элементами, обеспечивая тем самым более высокую степень когерентности и детализации генерируемого контента.
Единые Модели Состояний: Новый Подход к Дискретной Генерации
Мы предлагаем Унифицированные Модели Диффузии Состояний (USDM), расширение традиционных диффузионных моделей, разработанное для дискретных данных. В отличие от стандартных диффузионных моделей, работающих преимущественно с непрерывными пространствами, USDM адаптированы для генерации и обработки данных, представленных в дискретной форме, таких как текст, графы или категориальные признаки. Данная архитектура позволяет применять принципы диффузионного моделирования к задачам, где традиционные подходы оказываются неэффективными из-за специфики дискретных данных и необходимости учета сложных зависимостей между отдельными элементами. USDM обеспечивают гибкость в моделировании распределений вероятностей над дискретными пространствами, открывая возможности для создания более качественных и разнообразных дискретных генеративных моделей.
Модели равномерного диффузионного состояния (USDM) используют немарковские апостериорные распределения, в частности, суперпозиционные апостериорные распределения, для захвата зависимостей на больших расстояниях. Традиционные диффузионные модели, основанные на марковском предположении, рассматривают текущее состояние как зависящее только от предыдущего, что ограничивает их способность моделировать сложные взаимосвязи в данных. В отличие от них, суперпозиционные апостериорные распределения позволяют учитывать информацию из нескольких предыдущих состояний одновременно, что существенно расширяет «окно внимания» модели. Это позволяет USDM эффективно моделировать долгосрочные зависимости, которые критически важны для генерации дискретных данных, таких как текст или изображения, где контекст играет ключевую роль. Использование немарковских апостериорных распределений позволяет моделировать более сложные вероятностные связи и улучшать качество генерируемых образцов.
Использование равномерного априорного распределения в моделях Uniform State Diffusion (USDM) обеспечивает стабильность процесса обучения и способствует самокоррекции на этапах диффузии. В отличие от традиционных диффузионных моделей, где априорные распределения могут вносить нестабильность, равномерный приор позволяет избежать резких изменений в процессе генерации. Это достигается за счет равномерного распределения вероятностей по всем возможным состояниям, что снижает влияние отдельных состояний на общую структуру генерируемых данных. В результате, USDM демонстрируют улучшенное качество сэмплов и повышенную устойчивость к отклонениям в процессе обучения, особенно при работе с дискретными данными.

Duo++: Масштабирование Дискретной Диффузии с Эффективностью
Duo++ является развитием унифицированных детерминированных моделей дискретной диффузии (USDM) и включает в себя ряд ключевых оптимизаций, направленных на повышение масштабируемости и производительности. Данные оптимизации охватывают эффективные алгоритмы предсказатель-корректор для семплирования, использование curriculum learning для ускорения процесса обучения, а также стратегическое применение Classifier-Free Guidance. Внедрение техник TopKSelection и использование операций Softmax дополнительно повышают эффективность процесса семплирования, что позволяет достичь значительных улучшений в скорости и потреблении памяти при обучении и генерации дискретных диффузионных моделей.
Для повышения масштабируемости и производительности Duo++ применяет ряд оптимизаций, включающих эффективные семплеры типа «предиктор-корректор», обучение по принципу учебного плана (curriculum learning) и стратегическое использование Classifier-Free Guidance. Семплеры «предиктор-корректор» позволяют снизить количество шагов, необходимых для генерации, за счет более точного предсказания следующего состояния. Обучение по принципу учебного плана заключается в постепенном увеличении сложности задач в процессе обучения, что ускоряет сходимость модели. Classifier-Free Guidance, в свою очередь, позволяет контролировать процесс генерации без использования дополнительных классификаторов, повышая эффективность и гибкость модели.
Для повышения эффективности процесса дискретной диффузии в Duo++ реализованы методы TopKSelection и использование операций Softmax. TopKSelection позволяет отбирать наиболее вероятные токены на каждом шаге дискретизации, сокращая пространство поиска и вычислительные затраты. Операции Softmax, применяемые для вычисления вероятностей распределения, оптимизированы для снижения требований к памяти и ускорения вычислений. Комбинация этих методов обеспечивает значительное повышение скорости дискретизации при сохранении качества генерируемых данных.
В ходе экспериментов было показано, что Duo++ обеспечивает двукратное ускорение процесса генерации, снижение максимального потребления памяти на 33% и сокращение общего времени обучения моделей диффузии на 25%, при этом сохраняя сопоставимую производительность по сравнению с существующими методами, такими как Duo. Данные улучшения достигаются за счет оптимизаций в алгоритме дискретной диффузии, позволяющих повысить эффективность использования вычислительных ресурсов и снизить требования к памяти без ухудшения качества генерируемых данных.
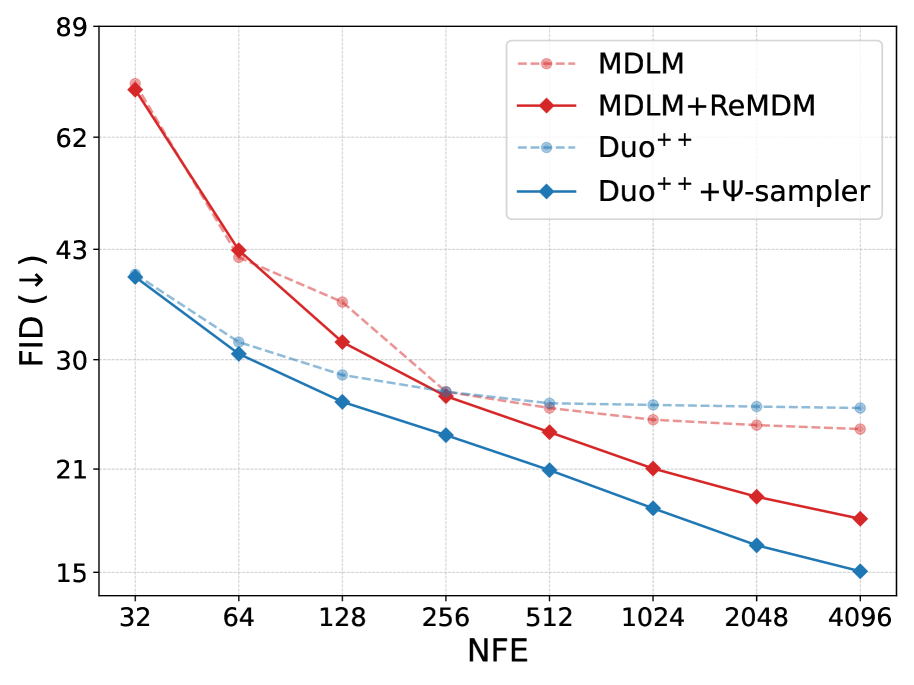
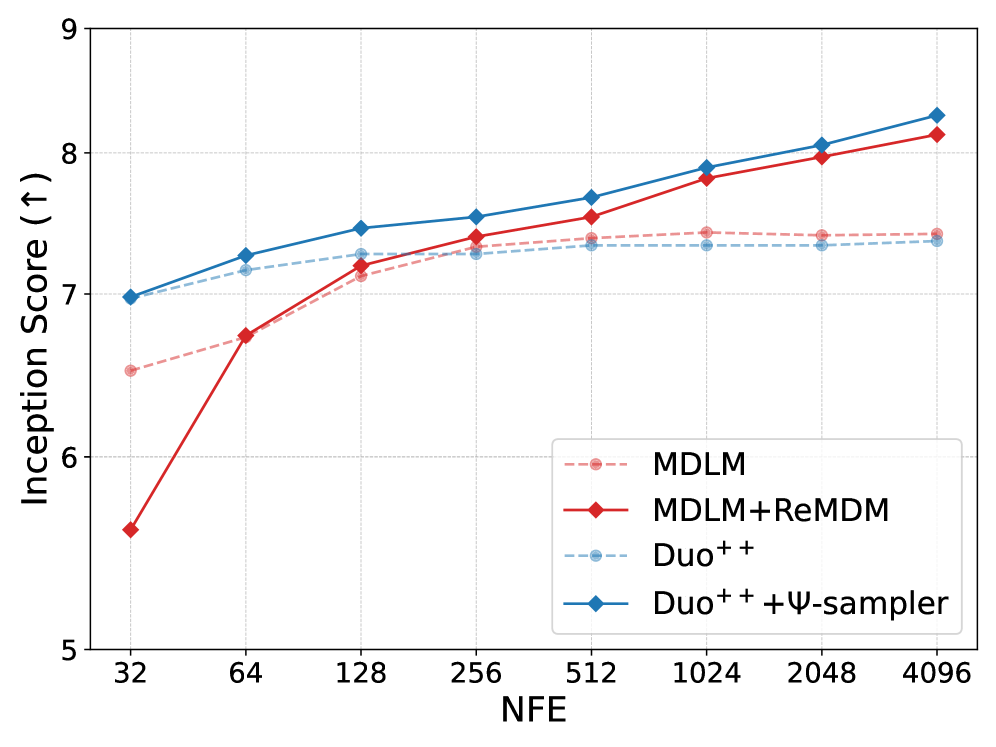
При оценке на датасете CIFAR-10, модель Duo++ демонстрирует улучшенные показатели по метрикам FID (Fréchet Inception Distance) и IS (Inception Score) в сравнении с методами MDLM (Masked Diffusion Language Model) с использованием семплирования на основе предков (ancestral sampling) и ReMDM. Данные результаты подтверждают эффективность предложенных оптимизаций в архитектуре Duo++ для генерации изображений и свидетельствуют о превосходстве над существующими подходами к диффузионным моделям на данном датасете.
В ходе тестирования на бенчмарке GSM8K, модель Duo++ продемонстрировала превосходство над авторегрессионной моделью аналогичного масштаба — 1.7 миллиарда параметров. Это указывает на более высокую способность Duo++ к решению задач, требующих логического вывода и математических навыков, представленных в наборе данных GSM8K, по сравнению с традиционными авторегрессионными подходами.
При оценке на датасете LM1B, модель Duo++ демонстрирует сопоставимые показатели правдоподобия с оригинальной моделью Duo. Это указывает на то, что предложенные оптимизации в архитектуре Duo++ не приводят к ухудшению качества генерации текста, сохраняя при этом улучшения в скорости и эффективности использования памяти. Сохранение сопоставимой производительности на LM1B является важным результатом, подтверждающим, что улучшения в Duo++ не достигаются за счет снижения общей способности модели к моделированию языка.
Влияние и Перспективы Дискретной Генерации
Разработки, представленные в Duo++, имеют значительные последствия для широкого спектра приложений, работающих с дискретными данными. Это касается не только генерации текста, где модель способна создавать более связные и осмысленные фрагменты, но и синтеза изображений, позволяя получать реалистичные визуальные представления. Особый потенциал Duo++ проявляется в области молекулярного дизайна, где алгоритм может быть использован для создания новых молекулярных структур с заданными свойствами. Способность эффективно моделировать дискретные данные открывает возможности для автоматизации процессов в различных областях, от разработки лекарств до создания контента, и способствует развитию искусственного интеллекта, способного решать сложные задачи, требующие креативности и точности.
Эффективное моделирование долгосрочных зависимостей открывает новые горизонты в генерации дискретных данных. Благодаря способности улавливать связи между элементами, разнесенными во времени или пространстве, создаваемые модели способны генерировать более связный, правдоподобный и творческий контент. В частности, это позволяет создавать тексты, где идеи логически связаны и развиваются последовательно, изображения с большей детализацией и реалистичностью, а также молекулярные структуры с заданными свойствами. Улавливая эти тонкие взаимосвязи, системы способны выходить за рамки простого воспроизведения шаблонов и демонстрировать признаки интеллектуального творчества, что существенно расширяет возможности применения в различных областях науки и искусства.
Дальнейшие исследования будут сосредоточены на интеграции разработанных методов с другими генеративными моделями, такими как вариационные автоэнкодеры и генеративно-состязательные сети, для создания гибридных систем, способных к более сложному и креативному синтезу дискретных данных. Особое внимание уделяется изучению потенциала этих интеграций для решения задач, требующих высокого уровня абстракции и детализации, например, в области создания реалистичных виртуальных миров, разработки новых лекарственных препаратов и генерации сложных музыкальных композиций. Перспективным направлением представляется разработка алгоритмов, способных адаптироваться к различным типам дискретных данных и автоматически оптимизировать параметры генерации для достижения наилучших результатов, что позволит расширить область применения данной технологии и создать инструменты для решения широкого спектра практических задач.
Эффективная генерация дискретных данных играет ключевую роль в дальнейшем развитии искусственного интеллекта, открывая новые горизонты для взаимодействия человека и машины. Способность создавать структурированные последовательности, такие как текст, изображения или молекулярные структуры, с высокой точностью и скоростью, позволяет решать задачи, ранее недоступные для автоматизации. Это не только расширяет возможности в областях, требующих творческого подхода, но и обеспечивает основу для создания интеллектуальных систем, способных к адаптации и обучению. Перспективные направления включают разработку более сложных и реалистичных виртуальных сред, автоматизацию научных открытий и создание персонализированных образовательных программ, где генерация дискретных данных становится неотъемлемой частью процесса.
В представленной работе наблюдается стремление к элегантности и эффективности, что находит отражение в подходе к дискретным диффузионным моделям. Авторы, подобно математикам, ищут наиболее лаконичное и строгое решение для задачи генерации данных. Как однажды заметил Клод Шеннон: «Теория коммуникации — это, по сути, математика, применяемая к проблемам передачи информации». Этот принцип применим и здесь: Duo++ стремится к оптимизации процесса дискретизации и обучения, используя суперпозицию апостериорных распределений и эффективную стратегию обучения, чтобы добиться превосходного качества генерируемых данных и масштабируемости. В стремлении к этой математической чистоте, авторы подчеркивают важность доказуемой корректности алгоритма, а не просто его работоспособности на тестовых примерах.
Что Дальше?
Представленная работа, хотя и демонстрирует улучшения в моделировании дискретных данных посредством диффузионных моделей, лишь слегка отодвигает завесу над истинной сложностью задачи. Утверждение о «эффективном» обучении требует тщательной проверки — оптимизация без анализа, как известно, есть самообман и ловушка для неосторожного исследователя. По сути, Duo++ предлагает элегантное решение для определенного класса задач, но вопрос о его обобщающей способности остается открытым. Необходимо установить, насколько хорошо этот подход масштабируется на данные с существенно иным распределением, и каковы пределы его применимости.
Дальнейшие исследования должны быть направлены на формальное доказательство сходимости предлагаемого алгоритма, а не просто на эмпирическое подтверждение его эффективности на ограниченном наборе данных. Интересно было бы изучить связь между используемым методом обучения с учителем и более общими принципами байесовского вывода. В частности, стоит задаться вопросом, можно ли разработать алгоритм, который автоматически адаптирует учебный план в зависимости от характеристик данных, избегая тем самым необходимости ручной настройки гиперпараметров.
В конечном счете, настоящая элегантность алгоритма проявляется в его математической чистоте и доказуемости. Прежде чем говорить о прорыве, необходимо убедиться, что предложенный подход не является лишь очередным эмпирическим успехом, который рухнет при столкновении с реальностью.
Оригинал статьи: https://arxiv.org/pdf/2602.21185.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Ядерный синтез и Искусственный Интеллект: Новый подход к проектированию реакторов
- Карта ошибок: Анатомия сбоев больших языковых моделей
- Надежность ускорителей: от замысла до реализации
- Квантовые нейросети для реалистичной 3D-визуализации
- Мощное моделирование жидкости: новый подход к методу решетчатых уравнений Больцмана
- Нейросеть предсказывает сродство антител к COVID-19
- Память как у живого мозга: новый подход к локальному AI
- Искусственный интеллект на службе материалов: от открытий до инноваций
- Кто несет ответственность за ИИ: новый взгляд на причинно-следственные связи
- Квантовый транспорт в сложных системах: новый подход к моделированию
2026-02-26 04:16