Автор: Денис Аветисян
В статье представлен воспроизводимый метод анализа влияния векторизации, многопоточности и двойной буферизации на производительность ИИ-ядер, основанный на использовании MLIR.
Исследование эффективности векторизации, многопоточности и асинхронного DMA в MLIR-компиляторе ИИ-ядер.
Оптимизация исполнения ИИ-ядер на периферийных устройствах требует эффективного использования параллелизма и сокрытия задержек доступа к памяти, что представляет собой сложную задачу. В работе, посвященной ‘Analyzing Latency Hiding and Parallelism in an MLIR-based AI Kernel Compiler’, представлен воспроизводимый методологический подход на базе MLIR для анализа влияния векторизации, многопоточности и двойной буферизации на производительность ядер. Полученные результаты демонстрируют, что векторизация является основой для ядер, чувствительных к пропускной способности, многопоточность обеспечивает значительный прирост при достаточном объеме вычислений, а двойная буферизация позволяет получить дополнительный выигрыш при возможности перекрытия передачи данных и вычислений. Какие новые стратегии оптимизации могут быть разработаны для дальнейшего повышения эффективности ИИ-вычислений на периферийных устройствах?
Оптимизация ядра: путь к максимальной производительности
Для достижения максимальной производительности в современных системах глубокого обучения требуется тщательная оптимизация ядра вычислений, зачастую прибегая к ручному написанию кода. Автоматические инструменты оптимизации, хотя и полезны, не всегда способны учесть все нюансы аппаратной архитектуры и специфики алгоритма. Поэтому, опытные разработчики прибегают к тонкой настройке низкоуровневого кода, анализируя профили производительности и выявляя узкие места. Такой подход позволяет добиться значительного прироста скорости, особенно в критически важных операциях, таких как векторные сложения или матричные умножения, которые являются основой большинства алгоритмов машинного обучения. В результате, оптимизация ядра становится ключевым фактором, определяющим общую эффективность и масштабируемость системы глубокого обучения.
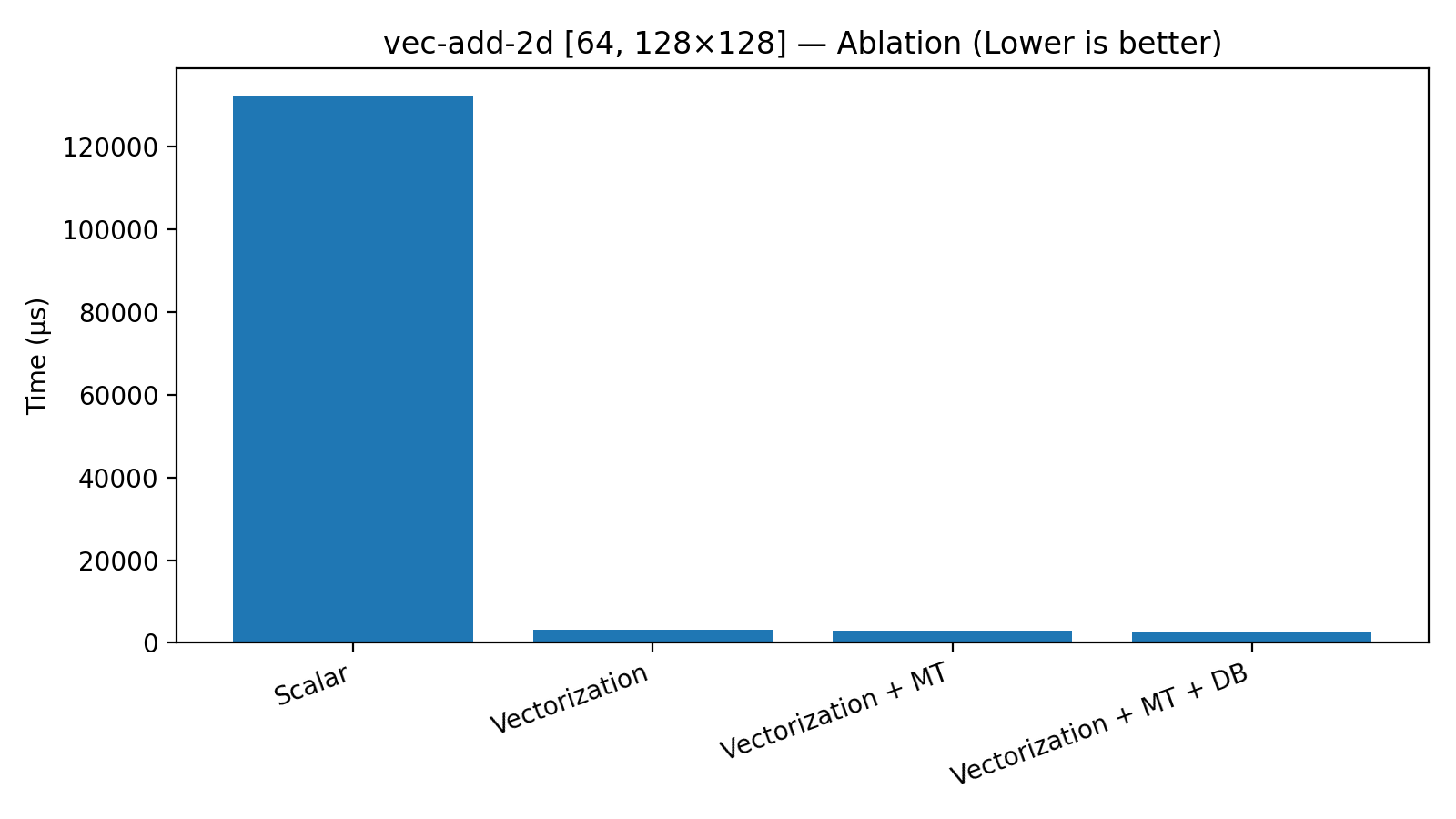
Конфигурация, обозначенная как “Scalar”, представляет собой базовый уровень производительности, служащий отправной точкой для оценки эффективности различных оптимизаций. При данной конфигурации, операция векторного сложения двухмерных векторов (vec-add-2d) демонстрирует задержку в 132 479 микросекунд. Этот показатель, хотя и является отправным, подчеркивает необходимость дальнейшей работы над оптимизацией кода для достижения более высоких скоростей вычислений и, как следствие, повышения общей производительности системы. Именно с этой базовой задержкой сравниваются результаты, полученные после применения различных техник оптимизации, что позволяет точно оценить их вклад в ускорение вычислений.
Несмотря на кажущуюся простоту, добавление оптимизаций в алгоритмы глубокого обучения не всегда приводит к желаемому результату. Улучшение производительности требует тщательного анализа влияния каждой оптимизации в отдельности и их совместного эффекта. Простое суммирование различных подходов может привести к неожиданным негативным последствиям, таким как увеличение времени выполнения или снижение точности. Исследователи подчеркивают необходимость систематического подхода к оценке эффективности оптимизаций, позволяющего выявить наиболее значимые факторы и избежать контрпродуктивных изменений. Только детальный анализ позволяет добиться максимальной производительности и раскрыть потенциал современных вычислительных систем.

Абляция производительности: шаг за шагом к оптимизации
Методология “Ablation Ladder” представляет собой строгий, поэтапный подход к оценке влияния отдельных оптимизаций — векторизации, многопоточности и двойной буферизации — на общую производительность. Суть заключается в последовательном добавлении каждой оптимизации и измерении результирующего изменения в производительности, начиная с базовой, скалярной реализации. Такой подход позволяет точно определить вклад каждой оптимизации, а также выявить возможные синергетические эффекты между ними. Например, сравнение производительности с конфигурациями, включающими только векторизацию, векторизацию и многопоточность, и все три оптимизации, дает количественную оценку улучшения в конкретных ядрах вычислений.
Сравнительный анализ производительности между базовой, скалярной реализацией и конфигурациями, включающими оптимизации, позволяет количественно оценить вклад каждой из них. Например, применительно к ядру vec-add-2d, использование векторизации в отрыве от других оптимизаций привело к снижению задержки до 3210 мкс, что представляет собой примерно 41.3-кратное улучшение по сравнению со скалярной версией. Такой подход позволяет выявить, как каждая оптимизация усиливает эффект от других, способствуя существенному повышению общей производительности.
Анализ показал, что оптимизации не просто суммируются, но и усиливают эффект друг друга в рассматриваемых ядрах. Например, начальное время задержки для vec-add-2d составляло определенное значение, которое было снижено до 3210 мкс за счет векторизации. Последующее добавление многопоточности позволило уменьшить задержку до 3000 мкс, а применение двойной буферизации — до 2689 мкс. Это демонстрирует, что каждый последующий уровень оптимизации использует преимущества предыдущих, приводя к значительному общему улучшению производительности.
Раскрытие параллелизма: векторизация и многопоточность
Векторизация использует принцип параллелизма на уровне данных, позволяя одновременно обрабатывать множественные элементы данных. Вместо последовательного применения операции к каждому элементу, векторизация применяет одну и ту же операцию сразу к нескольким элементам, используя специальные векторные инструкции процессора. Это достигается путем организации данных в векторы и выполнения операций над этими векторами целиком. Эффективность векторизации напрямую зависит от возможности организации данных таким образом, чтобы операции могли выполняться параллельно над соответствующими элементами векторов. \vec{a} + \vec{b} — пример векторной операции, которая может быть выполнена параллельно над элементами векторов \vec{a} и \vec{b} .
Многопоточность позволяет использовать параллелизм на уровне циклов и областей вычислений, разбивая задачу на независимые блоки данных (тайлы) и распределяя их обработку между различными аппаратными контекстами. Эффективная реализация требует координации этих потоков, которая часто осуществляется с помощью модели «Разделяй и Объединяй» (Fork-Join). В этой модели, основная задача разделяется на подзадачи, которые выполняются параллельно, а затем результаты объединяются для получения конечного результата. Успех многопоточности напрямую зависит от эффективного управления разделением задач и объединением результатов, чтобы минимизировать накладные расходы и максимизировать степень параллелизма.
Эффективная многопоточность требует внимательного управления накладными расходами на синхронизацию для предотвращения узких мест. Эти расходы возникают из-за необходимости координации работы нескольких потоков, включая операции ожидания и уведомления, взаимного исключения и обмена данными. Чрезмерная синхронизация может свести на нет преимущества параллельного выполнения, так как время, затрачиваемое на координацию, становится сопоставимым или даже превышает время обработки данных. Минимизация синхронизации достигается за счет использования алгоритмов и структур данных, снижающих потребность в блокировках и обеспечивающих эффективный доступ к общим ресурсам, а также за счет оптимизации гранулярности параллелизма — баланса между количеством потоков и объемом работы, выполняемой каждым потоком.
Наложение вычислений и памяти: сила двойной буферизации
Двойная буферизация позволяет снизить время простоя за счет наложения операций передачи данных из памяти и вычислений, используя такие методы, как асинхронный прямой доступ к памяти (DMA). В традиционных системах процессор ожидает завершения передачи данных перед началом вычислений, что приводит к задержкам. Асинхронный DMA позволяет процессору инициировать передачу данных и продолжать выполнение других задач, в то время как передача происходит в фоновом режиме. При использовании двойной буферизации, пока процессор выполняет вычисления с одним буфером данных, второй буфер заполняется или освобождается, что обеспечивает непрерывный поток данных и минимизирует время ожидания. Это особенно эффективно для задач, интенсивно использующих память, где скорость передачи данных является узким местом.
Эффективное наложение вычислений и передачи данных достигается за счет использования конвейерного (pipelined) расписания. В данном подходе, передача данных и выполнение вычислений организуются как последовательные этапы конвейера, что позволяет начать передачу новых данных до завершения вычислений над предыдущими. Максимизация степени наложения передачи данных и вычислений (Transfer/Compute Overlap) достигается путем оптимизации длительности каждого этапа и минимизации времени простоя между ними. Конвейерное расписание требует тщательной синхронизации и управления ресурсами, но позволяет существенно повысить общую производительность системы, особенно в задачах, где операции ввода-вывода являются узким местом.
Эффективность двойной буферизации особенно заметна в задачах, относящихся к категории “Bandwidth-Centric Kernel”, где производительность напрямую ограничена пропускной способностью памяти. В таких задачах, вычислительная мощность процессора не является узким местом, а основным фактором, влияющим на скорость выполнения, является скорость передачи данных между памятью и вычислительными блоками. Двойная буферизация позволяет перекрывать операции передачи данных с вычислениями, эффективно используя время ожидания и минимизируя простои, вызванные задержками доступа к памяти. Это приводит к значительному увеличению общей производительности, поскольку процессор может продолжать выполнять вычисления, пока данные для следующей итерации передаются в память.
MLIR: инфраструктура компилятора для оптимизации
Инфраструктура компилятора MLIR функционирует как промежуточное представление, позволяющее реализовать многопоточность и двойную буферизацию посредством специальных проходов, таких как ‘Form-Virtual-Threads’ и ‘Form-Async-Threads’. Эти проходы преобразуют исходный код ядра в явно параллельную форму, что способствует эффективному выполнению на современном аппаратном обеспечении. Благодаря этому подходу, MLIR предоставляет возможность оптимизации вычислений за счет распараллеливания задач и более эффективного использования ресурсов процессора, что особенно важно для ресурсоемких приложений и алгоритмов машинного обучения.
Преобразование ядра программы в явно параллельную форму посредством специальных проходов компиляции является ключевым аспектом повышения производительности на современных аппаратных платформах. Этот подход позволяет эффективно использовать многоядерные процессоры и другие параллельные вычислительные ресурсы. Вместо последовательного выполнения операций, ядро разбивается на независимые задачи, которые могут выполняться одновременно. Такой подход особенно важен для ресурсоемких вычислений, например, при обработке больших объемов данных или выполнении сложных математических операций. В результате достигается значительное ускорение выполнения программы, что делает ее более эффективной и отзывчивой.
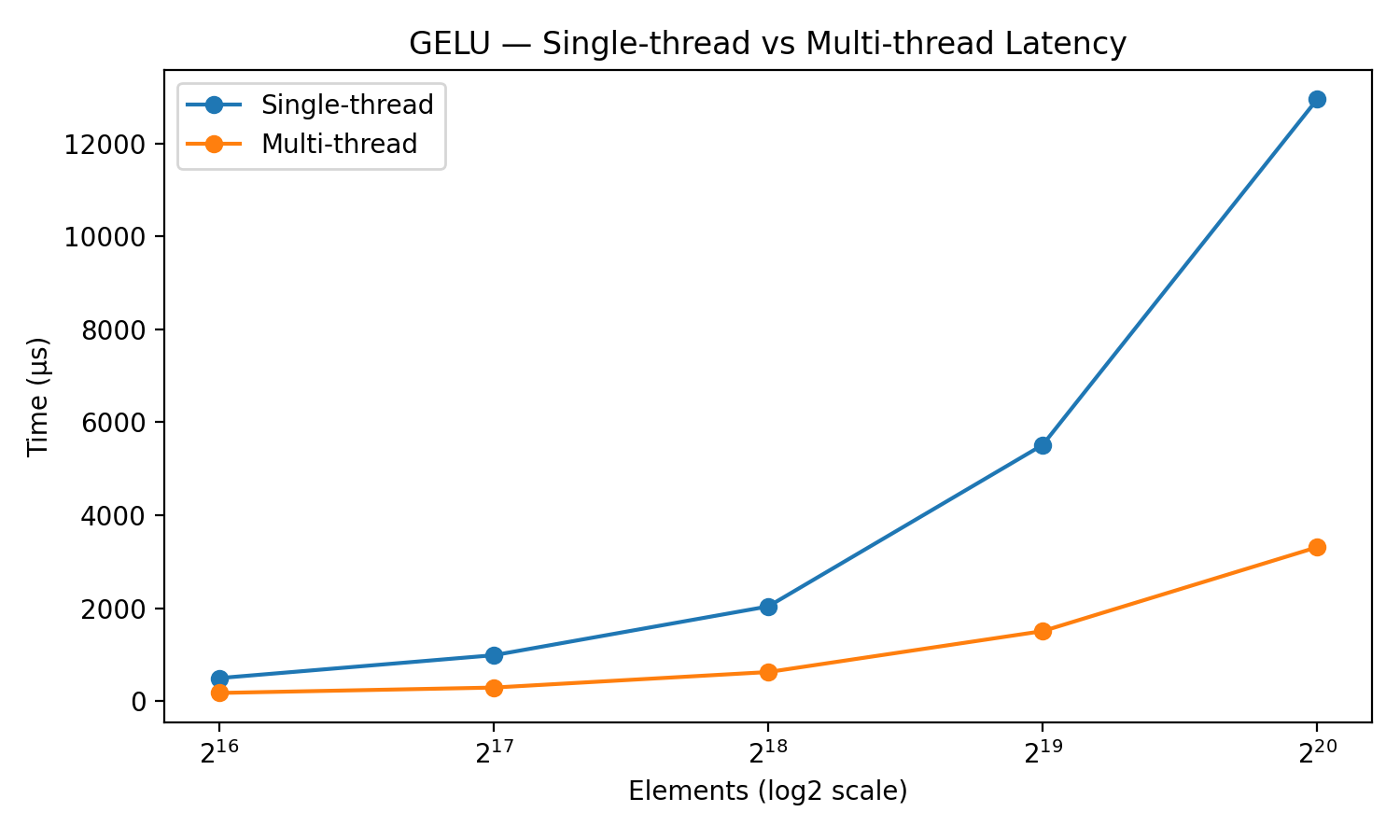
Исследования показали значительное ускорение при использовании многопоточности в вычислениях GELU. В частности, при обработке массивов данных, состоящих из 1 048 576 элементов, удалось добиться увеличения производительности в 3.91 раза. Однопоточный вариант выполнения занял 12 947 микросекунд, в то время как многопоточная реализация справилась с задачей всего за 3 313 микросекунд. Данный результат наглядно демонстрирует эффективность предложенных оптимизаций и их потенциал для значительного ускорения вычислений в задачах машинного обучения и других областях, требующих интенсивных вычислений.
Исследование, представленное в работе, демонстрирует, что оптимизация производительности вычислительных ядер требует комплексного подхода, учитывающего взаимодействие векторизации, многопоточности и двойной буферизации. Особое внимание уделяется тому, что векторизация является фундаментальным строительным блоком, а многопоточность приносит значительные улучшения при наличии достаточного объема работы. Как однажды заметил Бертран Рассел: «Всякое упрощение имеет свою цену в будущем». Этот принцип применим и к оптимизации ядер: упрощение модели вычислений ради немедленной выгоды может привести к снижению эффективности в долгосрочной перспективе, особенно при изменении характеристик данных или архитектуры аппаратного обеспечения. Двойная буферизация, хотя и приносит прирост производительности, требует тщательной оценки накладных расходов и преимуществ, поскольку ее эффективность зависит от степени перекрытия операций передачи и вычислений.
Что впереди?
Представленная работа, анализируя возможности сокрытия задержек и параллелизма в контексте MLIR-компилятора, неизбежно наталкивается на вопрос не о скорости, а о времени как среде. Векторизация, как показано, является фундаментом, но достаточно ли этого для систем, стремящихся к долговечности? Многопоточность даёт прирост, но требует достаточного объёма работы — что, по сути, является признаком временной ограниченности. Двойная буферизация приносит лишь инкрементальную пользу, когда перенос и вычисления пересекаются, что напоминает редкую фазу гармонии во времени.
Очевидным направлением дальнейших исследований является изучение взаимодействия этих техник с более сложными моделями памяти и иерархиями кэша. Однако, истинный вызов заключается в разработке систем, способных адаптироваться к меняющимся условиям, предвидеть узкие места и эффективно использовать доступные ресурсы. В конце концов, инфраструктура подобна естественным циклам: технический долг — это как эрозия, а стабильная работа — лишь временное затишье.
Более того, необходимо переосмыслить метрики производительности. Пропускная способность и задержка важны, но они не отражают общей устойчивости системы к нагрузкам и изменениям. Будущие исследования должны сосредоточиться на разработке метрик, которые учитывают не только скорость, но и долговечность, адаптивность и способность системы к самовосстановлению — всё в контексте неумолимого течения времени.
Оригинал статьи: https://arxiv.org/pdf/2602.20204.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Ядерный синтез и Искусственный Интеллект: Новый подход к проектированию реакторов
- Карта ошибок: Анатомия сбоев больших языковых моделей
- Надежность ускорителей: от замысла до реализации
- Квантовые нейросети для реалистичной 3D-визуализации
- Квантовые схемы: универсальность и сложность
- Искусственный интеллект на службе материалов: от открытий до инноваций
- Кто несет ответственность за ИИ: новый взгляд на причинно-следственные связи
- Квантовый транспорт в сложных системах: новый подход к моделированию
- Искусственный интеллект в науке: на пути к прозрачности
- Знания в графах: как улучшить ответы больших языковых моделей
2026-02-26 04:20