Автор: Денис Аветисян
Новый подход позволяет роботам лучше планировать действия, предсказывая развитие событий в окружающем мире.
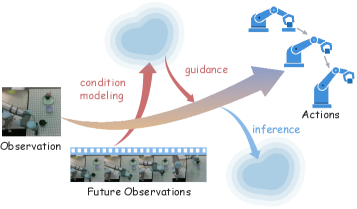
Представлен фреймворк WoG, использующий компактное пространство условий для улучшения генерации действий и обобщения в задачах манипулирования роботами.
Существующие подходы к генерации действий для роботов часто испытывают трудности в одновременном обеспечении эффективности прогнозирования будущего и сохранении достаточной детализации для точного управления. В данной работе, озаглавленной ‘World Guidance: World Modeling in Condition Space for Action Generation’, предлагается новый фреймворк WoG, который отображает будущие наблюдения в компактные условия, внедряя их непосредственно в процесс вывода действий. Такой подход позволяет моделировать мир в пространстве условий, улучшая точность генерации действий и обобщающую способность. Не откроет ли это путь к созданию более гибких и адаптивных робототехнических систем, способных эффективно взаимодействовать со сложными реальными средами?
За пределами реактивного управления: Необходимость прогностического действия
Традиционные системы управления роботами зачастую опираются на реактивные алгоритмы, что существенно ограничивает их способность адаптироваться к сложным и динамичным условиям окружающей среды. Вместо прогнозирования будущих состояний и заблаговременной подготовки к ним, робот реагирует лишь на уже произошедшие изменения. Это приводит к задержкам в принятии решений, неэффективности действий и, как следствие, к снижению надежности в непредсказуемых ситуациях. Например, в условиях плотного движения или при работе с хрупкими объектами, реактивное управление может оказаться недостаточным для обеспечения безопасного и точного выполнения задачи, поскольку робот не способен предвидеть потенциальные препятствия или изменения в окружающей обстановке и оперативно корректировать свои действия.
Для достижения эффективного взаимодействия с окружающей средой робототехническим системам необходимо не просто реагировать на текущие события, но и предвидеть их развитие. Способность прогнозировать будущие состояния позволяет выбирать оптимальные действия, обеспечивая более плавную и адаптивную работу в сложных и динамичных условиях. Эта задача представляет собой ключевой вызов для современной робототехники, поскольку требует интеграции данных сенсоров с алгоритмами моделирования и планирования, способными учитывать неопределенность и изменчивость реального мира. Разработка эффективных методов прогнозирования является критически важной для создания роботов, способных не просто выполнять заданные инструкции, но и самостоятельно принимать решения в условиях, когда заранее невозможно предсказать все возможные сценарии.
Современные роботизированные системы часто сталкиваются с трудностями при интеграции восприятия окружающей среды, прогнозирования ее будущего состояния и генерации надежных действий. Существующие методы, как правило, демонстрируют высокую эффективность лишь на отдельных этапах этого процесса, но испытывают серьезные ограничения при попытке объединить их в единую, слаженно работающую систему. Проблема заключается не только в вычислительной сложности, но и в необходимости разработки алгоритмов, способных эффективно обрабатывать неопределенность и неполноту информации, характерные для реальных условий эксплуатации. Неспособность достоверно предсказывать последствия действий и адаптироваться к изменяющейся обстановке приводит к снижению надежности и эффективности роботов в сложных и динамичных средах, что требует дальнейших исследований в области прогностического управления и разработки новых подходов к интеграции различных модулей роботизированных систем.

Модели «Видение-Язык-Действие»: Рамки для предвидения
Модели «Видение-Язык-Действие» (VLA) представляют собой перспективный подход к интеграции восприятия и действий посредством обучения с предсказанием. В отличие от традиционных систем, VLA модели не ограничиваются реакцией на текущие входные данные, а способны прогнозировать будущие состояния окружающей среды и соответствующие необходимые действия. Этот процесс обучения основан на анализе взаимосвязей между визуальной информацией, лингвистическими описаниями и последовательностями действий, что позволяет модели формировать внутреннее представление о динамике мира и планировать действия на основе предсказаний. Обучение с предсказанием позволяет VLA моделям адаптироваться к новым ситуациям и демонстрировать более гибкое и эффективное поведение в сложных средах.
Модели «Видение-Язык-Действие» (VLA) используют мультимодальные данные — информацию, полученную из различных источников, таких как визуальные изображения, текстовые описания и данные о действиях — для создания единого, интегрированного представления об окружающей среде. Этот процесс включает в себя объединение и сопоставление информации из разных модальностей, что позволяет модели формировать более полное и контекстуально-обоснованное понимание ситуации. В результате, VLA-модели способны прогнозировать вероятные исходы и выбирать оптимальные действия на основе этого объединенного представления, обеспечивая, таким образом, более эффективное и обоснованное принятие решений в различных сценариях.
Модели «Видение-Язык-Действие» (VLA) объединяют преимущества трех различных подходов для решения ограничений традиционных систем управления. В отличие от классических методов, полагающихся на заранее заданные правила или непосредственное управление на основе сенсорных данных, VLA-модели используют визуальную информацию для понимания окружения, языковые модели для интерпретации целей и контекста, и предсказание действий для планирования оптимальных стратегий поведения. Это позволяет им адаптироваться к новым ситуациям, обобщать полученный опыт и принимать решения в условиях неопределенности, что существенно повышает их эффективность и надежность по сравнению с традиционными системами, требующими ручной настройки и адаптации к каждому конкретному сценарию.
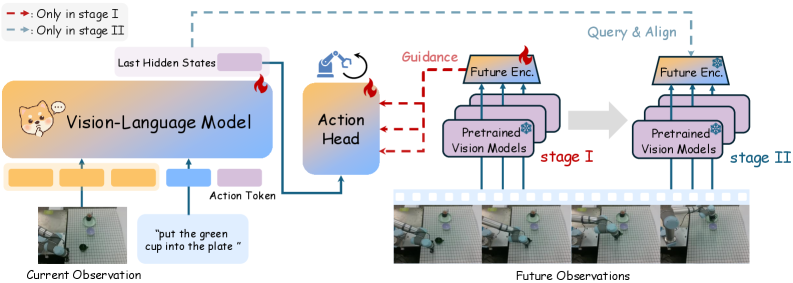
Прогностическое действие с World-of-Gradients и условиями
В основе фреймворка World-of-Gradients (WoG) лежит концепция “пространства условий” (condition space), используемого для управления генерацией действий посредством предсказания будущих наблюдений. Вместо прямого определения действий, WoG моделирует вероятное развитие ситуации после выполнения того или иного действия. Пространство условий служит для кодирования информации о желаемом будущем состоянии, которое и используется для направления процесса генерации действий. По сути, система стремится выбрать действие, которое максимизирует вероятность достижения предсказанного будущего состояния, закодированного в этом пространстве условий. Это позволяет WoG генерировать действия, ориентированные на долгосрочные цели и учитывающие динамику окружающей среды.
В основе World-of-Gradients (WoG) лежит использование предварительно обученных моделей, таких как DINOv2 и Wan VAE, для кодирования визуальной информации об окружении. DINOv2 обеспечивает эффективное извлечение визуальных признаков, а Wan VAE выполняет их сжатие и формирование латентного пространства. Ключевым компонентом является Q-Former, который используется для выделения и сжатия признаков, релевантных для действий агента, и преобразования их в компактное представление, пригодное для планирования и принятия решений. Этот подход позволяет WoG эффективно обрабатывать визуальные данные и фокусироваться на наиболее важных аспектах окружающей среды для выполнения поставленных задач.
В рамках задачи Point-to-Point (P&P) фреймворк World-of-Gradients (WoG) достиг передового результата в 85% успешных выполнений. Это достижение стало возможным благодаря прогнозированию будущих наблюдений, что позволило системе эффективно планировать и выполнять действия в различных условиях. Ключевым аспектом является способность WoG к обобщению, то есть сохранению высокой производительности на новых, ранее не встречавшихся сценариях, что подтверждает эффективность подхода к предсказанию будущих состояний среды для управления агентом.
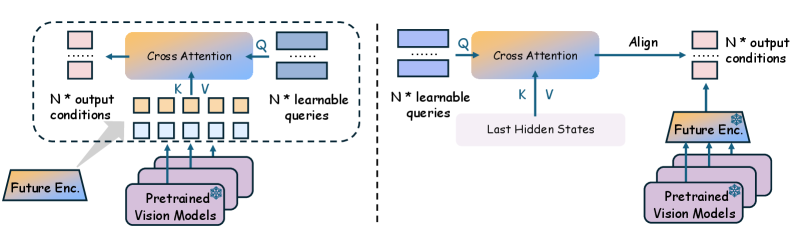
Обобщение и развертывание в реальном мире с открытыми наборами данных
Способность к обобщению, то есть к успешной работе в ситуациях, не встречавшихся ранее в процессе обучения, является определяющим фактором при внедрении визуально-языковых моделей (VLA) в реальные условия. Отсутствие такой способности приводит к непредсказуемым ошибкам и снижает надежность системы в динамичной среде. Для эффективного функционирования в реальном мире, модели должны не просто запоминать примеры, но и понимать общие принципы, позволяющие адаптироваться к новым, неизвестным ситуациям. Именно поэтому исследования в области обобщения являются ключевыми для развития практических приложений VLA, будь то робототехника, автоматизация или взаимодействие человека с компьютером.
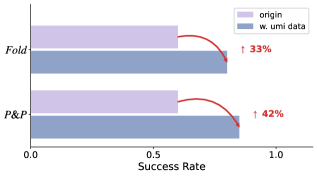
Для эффективной оценки и повышения способности моделей к обобщению, то есть к успешной работе в ранее не встречавшихся ситуациях, ключевое значение имеют специализированные наборы данных. Наборы, такие как OXE Dataset, предоставляют стандартизированную среду для тестирования, а пользовательские мультимодальные данные (UMI Data) отражают разнообразие реальных сценариев взаимодействия человека с объектами. Использование UMI Data позволяет обучать модели, способные адаптироваться к вариациям в освещении, углах обзора и других факторах, что критически важно для надежной работы в реальном мире. Такой подход, как продемонстрировано в рамках WoG framework, позволяет достигать высоких показателей успешности в задачах, требующих манипулирования объектами, и приближает разработку систем, способных эффективно функционировать в непредсказуемой среде.
В рамках разработки гибкой системы управления роботами (WoG) особое внимание уделялось способности к манипулированию сложными объектами. Использование пользовательских мультимодальных данных (UMI Data) позволило достичь впечатляющих результатов: система продемонстрировала 80%-ный показатель успешности при выполнении задачи по складыванию (Fold), а при закрытии микроволновой печи (Close the Microwave) — практически безошибочную работу. Эти результаты свидетельствуют о высокой надежности и адаптивности WoG в контексте взаимодействия с реальными объектами и выполнения разнообразных манипулятивных задач, что открывает перспективы для широкого применения в бытовых и промышленных условиях.
К эффективному и надежному обучению роботов
Модели латентных действий представляют собой перспективный подход к снижению вычислительной нагрузки в робототехнике. Вместо непосредственного управления каждым суставом робота, эти модели сжимают будущие действия в компактное, разреженное латентное пространство. Это достигается путем обучения модели предсказывать будущие наблюдения, основываясь на сжатом представлении действий. Такой подход позволяет значительно уменьшить объем вычислений, необходимых для планирования и управления роботом, поскольку модель работает с гораздо меньшим количеством параметров, чем при непосредственном контроле. Разреженность латентного пространства дополнительно оптимизирует процесс, фокусируясь на наиболее важных аспектах действия и игнорируя несущественные детали, что приводит к повышению эффективности и скорости работы робота.
Модели латентных действий, стремясь к оптимизации управления роботами, используют механизм реконструкции будущих наблюдений для формирования эффективных стратегий. Вместо прямого прогнозирования действий, модель учится предсказывать, что робот увидит в ближайшем будущем, основываясь на текущем состоянии и выбранном действии. Этот процесс заставляет модель создавать компактные представления действий, которые наилучшим образом предсказывают сенсорные данные. Благодаря этому подходу, робот способен быстрее адаптироваться к меняющимся условиям, так как ему не требуется анализировать все возможные варианты действий. Более того, способность модели предвидеть последствия своих действий значительно повышает устойчивость системы к шумам и неточностям, делая управление роботом более надежным и эффективным.
Сочетание способности к прогнозированию будущего и эффективного обучения представлений открывает новые горизонты в области робототехники. Благодаря этому подходу, роботы перестают быть просто исполнителями заранее запрограммированных команд, приобретая способность адаптироваться к изменяющимся условиям и непредсказуемым ситуациям. Способность предсказывать последствия своих действий позволяет им планировать более эффективные и безопасные траектории, а сжатое представление информации — снижает вычислительную нагрузку и повышает скорость реакции. В результате, создаются роботизированные системы, способные к более сложным и гибким операциям, что существенно расширяет сферу их применения — от автоматизации производства до освоения новых территорий и помощи человеку в повседневной жизни.
![Используя стратегию сбора данных о манипуляциях человека, аналогичную [gr3,gr-dexter], мы получаем около 450 траекторий в час с помощью VR-устройств, что значительно превосходит сбор траекторий с телеуправляемого робота, при этом для обучения используется лишь 11% данных с аннотациями действий, а остальные 89% - неразмеченные видео, что более реалистично отражает условия реального мира и позволяет оценить масштабируемость WoG.](https://arxiv.org/html/2602.22010v1/x6.png)
Работа демонстрирует стремление к упрощению сложных процессов, что находит отклик в философии Тим Бернерс-Ли. Он говорил: «Сложность — это тщеславие. Ясность — милосердие». Предложенный подход World Guidance (WoG) направлен на создание компактного пространства для предсказания будущих состояний, что позволяет улучшить генерацию действий для манипуляций роботами. Вместо усложнения системы, авторы стремятся к элегантности, фокусируясь на предсказании ключевых условий. Это отражает принципиальный подход: абстракции стареют, принципы — нет. Через оптимизацию и сжатие информации, система достигает большей эффективности и обобщающей способности, избегая излишней сложности.
Куда Ведет Этот Путь?
Представленная работа, фокусируясь на предсказании будущих состояний в компактном пространстве условий для улучшения генерации действий, неизбежно сталкивается с фундаментальной сложностью: насколько адекватна сама эта «компактность»? Стремление к минимализму, хотя и оправдано с точки зрения вычислительной эффективности, таит в себе опасность потери критически важных нюансов, необходимых для надежного манипулирования в реальном мире. Вопрос не в том, чтобы сжать информацию, а в том, чтобы найти оптимальное соотношение между сжатием и сохранением релевантной детализации.
Очевидным направлением дальнейших исследований представляется разработка методов, позволяющих динамически адаптировать размер пространства условий в зависимости от сложности задачи и доступных данных. Статичное определение этого пространства представляется искусственным ограничением. Более того, необходимо учитывать возможность интеграции моделей предсказания не только с визуальной информацией и языковыми командами, но и с другими сенсорными модальностями, расширяя тем самым «понимание» агентом окружающей среды.
В конечном итоге, успех подобных систем будет определяться не столько способностью к имитации человеческих действий, сколько способностью к надежному решению задач в условиях неопределенности и неполноты информации. И это требует не просто более сложных алгоритмов, а более глубокого понимания принципов, лежащих в основе интеллекта — понимания, которое, возможно, лежит за пределами текущих парадигм машинного обучения. Лишнее — насилие над вниманием.
Оригинал статьи: https://arxiv.org/pdf/2602.22010.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Сияние фотонов: новый уровень точности в предсказаниях столкновений частиц
- Трансформация нейросетей: от плотных моделей к разреженным экспертам без обучения
- Эхо чёрных дыр: как квантовая гравитация меняет гравитационные волны
- Квантовая Физика и Безопасность: Анализ Последних Новостей
- Биосети в руках ИИ: Автоматизация системной фармакологии
- Волшебство по запросу: ИИ создает заклинания в игре
- Марс и магнитное поле: новый взгляд с помощью нейросетей
- Искусственный интеллект и кодер: меняется ли подход к разработке?
- Искусственный интеллект на страже кода: новая оценка качества
- Квантовые смеси: от капель жидкости до сверхтекучих кристаллов
2026-02-26 21:18