Автор: Денис Аветисян
Новое исследование показывает, как предварительное обучение модели декодирования речи на данных одного испытуемого значительно улучшает ее производительность и способность к обобщению на другие задачи даже при ограниченном количестве данных от новых участников.
В статье демонстрируется эффективность переноса обучения на основе МЭГ-сигналов для декодирования речи и определения границ речи/тишины с использованием ограниченных данных.
Несмотря на значительный прогресс в нейрокомпьютерных интерфейсах, эффективное декодирование речи при ограниченном объеме данных остается сложной задачей. В работе ‘MEG-to-MEG Transfer Learning and Cross-Task Speech/Silence Detection with Limited Data’ продемонстрировано, что предварительное обучение модели на данных одного испытуемого и последующая тонкая настройка на небольшом количестве данных новых участников значительно повышает точность декодирования речи и возможность переноса знаний между задачами восприятия и производства. Полученные результаты свидетельствуют о том, что предварительное обучение способствует формированию общих нейронных представлений, позволяя модели успешно декодировать пассивное прослушивание на основе данных о речевом производстве. Какие еще стратегии предварительного обучения могут быть использованы для улучшения обобщающей способности моделей декодирования речи на основе МЭГ?
Раскрытие Речи: Вызовы Нейронных Сетей
Современные методы декодирования речи, несмотря на значительные достижения, сталкиваются с трудностями при обработке естественной сложности языка, что требует огромных объемов обучающих данных. Нейронные сети, стремясь уловить тонкости произношения и семантики, часто нуждаются в миллионах примеров для достижения приемлемой точности. Эта зависимость от больших данных не только ограничивает применение таких систем в условиях дефицита размеченных записей, но и создает вычислительные проблемы, поскольку обучение и развертывание моделей становятся ресурсоемкими. Проблема усугубляется вариативностью речи — акцентами, скоростью произношения, эмоциональной окраской — каждая из которых добавляет новые слои сложности, требующие еще больше данных для адекватного моделирования. В результате, создание универсальной системы декодирования речи, способной эффективно работать в реальных условиях, остается сложной задачей, требующей инновационных подходов к обучению и архитектуре нейронных сетей.
Одной из главных сложностей в декодировании речи является эффективная обработка временной информации, присущей звучащей речи. Традиционные нейронные сети часто испытывают трудности с улавливанием тонких изменений во времени, которые критически важны для понимания смысла. Поэтому исследователи обращаются к более биологически правдоподобным архитектурам, вдохновленным устройством человеческого мозга. Эти модели стремятся имитировать способы, которыми мозг обрабатывает звуки во времени, используя рекуррентные нейронные сети и временные сверточные сети для более точного захвата динамики речи. Разработка таких систем не только улучшит точность декодирования, но и позволит создавать более эффективные и энергосберегающие алгоритмы, приближая нас к созданию искусственного интеллекта, способного понимать речь так же, как человек.
Успешное декодирование речи напрямую зависит от точного определения наличия речевого сигнала, задачи, известной как обнаружение речи. Этот начальный этап критически важен, поскольку шум, фоновые звуки и даже неверная сегментация аудиопотока могут существенно снизить эффективность последующего анализа. Современные алгоритмы обнаружения речи стремятся отделить речевые фрагменты от неречевых, используя сложные методы обработки сигналов и машинного обучения. Особенно актуальна задача обнаружения речи в условиях переменной акустической среды и при наличии нескольких говорящих. Достижение высокой точности на этом этапе является основой для создания надежных систем распознавания и синтеза речи, а также для улучшения качества коммуникации в различных приложениях, начиная от голосовых помощников и заканчивая системами автоматического транскрибирования.
Двойная потоковая модель обработки речи предполагает существование отдельных нейронных путей, отвечающих за восприятие и воспроизведение звуков. Данная концепция, вдохновленная устройством человеческого мозга, указывает на необходимость разработки более тонких алгоритмов декодирования речи. Традиционные подходы часто объединяют эти два процесса, что может приводить к потере важной информации. Исследования показывают, что разделение обработки на отдельные потоки — один, отвечающий за понимание услышанного, и другой — за планирование и артикуляцию речи — позволяет создавать системы, более эффективно распознающие и интерпретирующие сложные речевые паттерны, а также более точно восстанавливать исходный смысл сказанного. Такая архитектура открывает перспективы для создания продвинутых интерфейсов «мозг-компьютер» и систем помощи людям с нарушениями речи.
MEGConformer: Компактное Решение для Декодирования Речи
Модель MEGConformer представляет собой оптимизированный подход к обработке данных магнитоэнцефалографии (МЭГ) во временной области. Основываясь на архитектуре Conformer, известной своей эффективностью в задачах последовательной обработки, MEGConformer адаптирована для анализа сложных МЭГ-сигналов. Использование Conformer позволяет модели эффективно извлекать и обрабатывать временные зависимости в данных МЭГ, обеспечивая высокую точность при одновременном снижении вычислительной нагрузки по сравнению с более сложными архитектурами. Такая оптимизация особенно важна для обработки больших объемов данных МЭГ, что делает MEGConformer практичным решением для широкого спектра нейрокогнитивных исследований.
Компактная архитектура MEGConformer обеспечивает эффективную обработку данных МЭГ с пониженными вычислительными требованиями, не жертвуя при этом точностью. Это достигается за счет оптимизации количества параметров и использования эффективных операций, что позволяет снизить потребление памяти и время вычислений. Модель разработана для работы на ресурсах с ограниченной мощностью, сохраняя при этом конкурентоспособную производительность по сравнению с более сложными моделями. Такой подход делает MEGConformer подходящим для широкого спектра применений, включая портативные устройства и системы реального времени.
Эффективность MEGConformer значительно повышается за счет использования трансферного обучения, которое позволяет переносить знания, полученные на больших объемах данных, на решение конкретных задач. Применение данного подхода демонстрирует улучшения в ключевых метриках на 1-6%. Трансферное обучение позволяет модели эффективно извлекать признаки и адаптироваться к индивидуальным данным, что особенно важно при анализе электроэнцефалограмм (МЭГ) с учетом специфики каждого испытуемого.
Модель MEGConformer использует датасет LibriBrain для предварительного обучения, что позволяет получить надежные признаки перед адаптацией к данным конкретного субъекта. LibriBrain, содержащий большое количество аудиозаписей и соответствующих данных о мозговой активности, служит основой для обучения модели извлекать релевантные характеристики из MEG-сигналов. Этот этап предварительного обучения значительно улучшает обобщающую способность модели и снижает потребность в больших объемах данных для последующей индивидуальной настройки, обеспечивая более эффективное обучение и повышение точности декодирования.
Усиление Надежности с Помощью Временной Аугментации
Для повышения обобщающей способности и устойчивости модели к вариациям в речи были реализованы методы темпоральной аугментации. Данный подход предполагает внесение незначительных изменений во временные характеристики входных данных, что эффективно увеличивает разнообразие обучающей выборки. Использование темпоральной аугментации позволяет модели лучше адаптироваться к реальным условиям, в которых характеристики речи могут отличаться от тех, что представлены в исходном наборе данных. Это позволяет улучшить способность модели к обобщению и снизить вероятность переобучения, повышая ее надежность в различных сценариях использования.
Для повышения разнообразия обучающей выборки и улучшения обобщающей способности модели были применены методы временной аугментации. Суть подхода заключается в незначительных изменениях временных характеристик входных данных, таких как небольшое растяжение или сжатие во времени, добавление шума или смещение по времени. Эти преобразования создают искусственно расширенный набор данных, представляющий различные вариации входного сигнала, что позволяет модели более эффективно обучаться и адаптироваться к реальным условиям, включая различные скорости речи, задержки и другие искажения, встречающиеся в практических приложениях.
Для повышения устойчивости модели MEGConformer к вариациям в реальных речевых данных была применена методика временной аугментации, в частности, RollAugment. RollAugment предполагает циклический сдвиг временной шкалы аудиосигнала, создавая искусственные вариации в продолжительности и фазе звуковых событий. Этот метод позволяет модели научиться игнорировать незначительные временные искажения, часто встречающиеся в реальных условиях, такие как изменения скорости речи или задержки в передаче сигнала. В результате, модель становится менее чувствительной к таким вариациям и демонстрирует повышенную точность распознавания речи в различных акустических условиях.
Использование временной аугментации в сочетании с предварительно обученной моделью MEGConformer демонстрирует значительное повышение точности распознавания речи. В ходе экспериментов, применительно к задаче прослушивания, наблюдалось увеличение показателя Accuracy на 3.7% и F1-меры на 2.6%. Данные улучшения были достигнуты за счет применения трансферного обучения, что подтверждает эффективность комбинированного подхода для повышения устойчивости и обобщающей способности модели в реальных условиях.
Влияние на Понимание Речевых Процессов
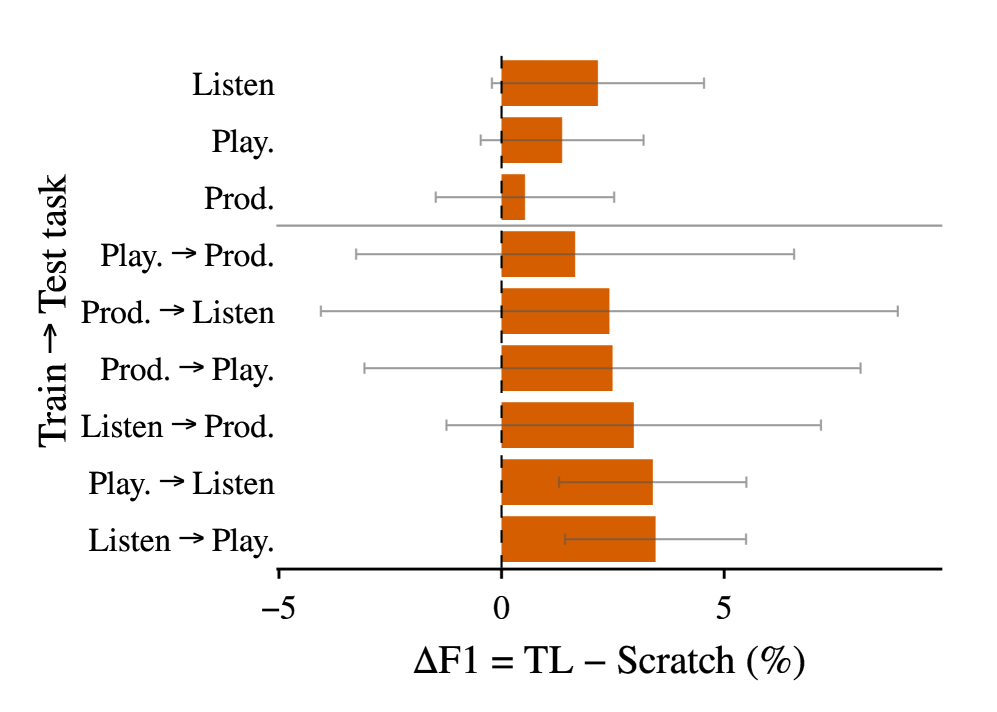
Исследования показали высокую эффективность объединения компактной архитектуры Conformer с методами переноса обучения и временной аугментации для надежного декодирования речи. Данный подход позволил добиться значительных улучшений в точности распознавания речевых сигналов, особенно в условиях, когда данные ограничены или зашумлены. Использование переноса обучения, когда модель, обученная на одной задаче, адаптируется к другой, продемонстрировало прирост точности до 6,1% и увеличение показателя F1 до 4,2% в различных сценариях, включая задачи прослушивания с последующим воспроизведением и наоборот. Такой синергетический эффект подтверждает, что комбинация современных архитектур глубокого обучения и продвинутых методов обучения позволяет создавать более устойчивые и эффективные системы декодирования речи, способные успешно функционировать в сложных акустических условиях.
Разработанный подход, позволяющий точно декодировать речевые сигналы из данных магнитоэнцефалографии (МЭГ), представляет собой мощный инструмент для изучения нейронных механизмов, лежащих в основе обработки речи. Возможность неинвазивного и точного считывания речевой информации непосредственно из мозговой активности открывает новые перспективы для исследования того, как мозг воспринимает, понимает и воспроизводит речь. Такой метод позволяет исследовать динамику нейронных процессов, связанных с различными аспектами речевого сигнала, такими как фонемы, слоги и слова, а также изучать индивидуальные различия в организации речевой системы мозга. В перспективе, данная технология может быть использована для разработки нейропротезов речи, помощи пациентам с нарушениями речи и углубленного понимания когнитивных процессов, связанных с языком.
Данная работа значительно расширяет устоявшуюся дуальную модель обработки речи, предоставляя вычислительную основу для декодирования как перцептивных, так и продуктивных аспектов речевой деятельности. Традиционно, эти два процесса рассматривались как отдельные звенья, однако предложенный подход позволяет одновременно анализировать сигналы, связанные с восприятием речи и ее воспроизведением. Это достигается за счет интеграции двух потоков информации — одного, отражающего акустические характеристики воспринимаемого сигнала, и другого — моделирующего процессы артикуляции и формирования речи. Такой комплексный анализ позволяет более глубоко понять нейронные механизмы, лежащие в основе речевого общения, и открывает новые возможности для изучения нарушений речи и разработки эффективных методов реабилитации.
Исследования показали, что применение трансферного обучения значительно повышает точность декодирования речи. В различных кросс-задачах, включающих распознавание речи и её воспроизведение, наблюдалось увеличение показателя точности до 6,1% и F1-меры до 4,2%. Данные результаты демонстрируют высокую обобщающую способность разработанной модели, позволяя ей эффективно адаптироваться к различным условиям и задачам, связанным с обработкой речи. Способность к трансферному обучению указывает на то, что модель способна извлекать и применять общие закономерности из данных, что существенно повышает её практическую ценность и потенциал для дальнейших исследований в области нейролингвистики и обработки сигналов.
Исследование, представленное в статье, демонстрирует, что предварительное обучение модели на большом объеме данных, полученных от одного испытуемого, значительно улучшает ее производительность и способность к обобщению на новые задачи, даже при ограниченном количестве данных от других испытуемых. Это подчеркивает важность формирования надежной основы для дальнейшего развития системы. Как однажды заметила Ада Лавлейс: «То, что может быть выражено в форме алгоритма, может быть сделано». Этот принцип применим и здесь: тщательно разработанный алгоритм предварительного обучения позволяет системе адаптироваться и преуспевать в новых условиях, несмотря на ограниченные ресурсы. Истинная устойчивость системы начинается там, где кончается уверенность в идеальности входных данных — система должна быть способна к адаптации и обучению даже в условиях неопределенности, что и демонстрирует данная работа.
Что дальше?
Представленные результаты, хотя и обнадеживающие, лишь слегка отодвигают завесу над истинной сложностью нейронных систем. Утверждение о возможности переноса обучения между задачами, пусть и в рамках декодирования речи, напоминает попытку привить яблоню на грушу — да, приживается, но плоды всегда будут компромиссом. Иллюзия “универсальной” нейронной репрезентации, выстроенной на данных одного субъекта, неизбежно столкнется с жестокой реальностью индивидуальных различий. Архитектура — это не структура, а компромисс, застывший во времени.
Вместо того чтобы стремиться к созданию всеобъемлющей модели, представляется более плодотворным признание фундаментальной непредсказуемости мозга. Попытки «вырастить» нейронные системы, адаптирующиеся к конкретному субъекту и конкретной задаче, представляются более реалистичными, чем навязчивое стремление к созданию универсальных алгоритмов. Технологии сменяются, зависимости остаются. Вопрос не в том, как построить лучшую модель, а в том, как смириться с неизбежной неточностью.
Будущие исследования, вероятно, сосредоточатся на разработке методов адаптации моделей к новым субъектам с минимальным количеством данных, а также на изучении механизмов, лежащих в основе индивидуальных различий в нейронных репрезентациях. Это не поиск идеальной модели, а, скорее, попытка предсказать, где и когда система неизбежно даст сбой.
Оригинал статьи: https://arxiv.org/pdf/2602.18253.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Эхо чёрных дыр: как квантовая гравитация меняет гравитационные волны
- Распознавание смыслов: новый подход к классификации документов
- Сверхпроводящая логика: управление магнитным полем
- Сияние фотонов: новый уровень точности в предсказаниях столкновений частиц
- Интеллектуальные агенты: как воплотить опыт экспертов в искусственный интеллект
- Глубинное зрение роботов: новый подход к обучению восприятию
- Квантовые вычисления: Честность и Прогресс
- Воссоздавая интерьеры: новый подход к 3D-реконструкции
- Финансовый интеллект машин: новый тест на прочность
- Искусственный интеллект и кодер: меняется ли подход к разработке?
2026-03-01 01:07