Автор: Денис Аветисян
Новое исследование предлагает подход к генерации длинных аудиодорожек по видео, преодолевая ограничения существующих моделей и открывая путь к более реалистичному и продолжительному мультимедийному контенту.
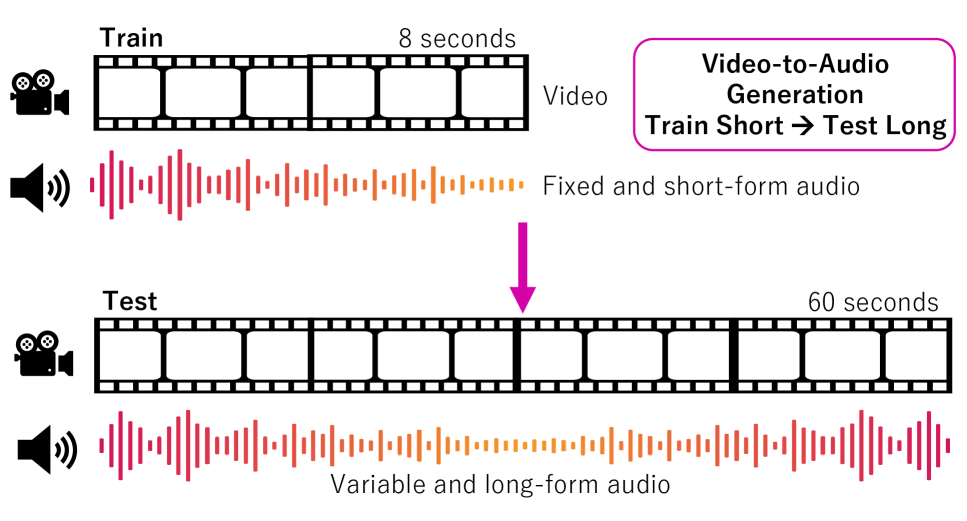
Представлена архитектура MMHNet, использующая некаузальные Mamba-слои и иерархическое моделирование для генерации длинного аудио из видео с улучшенной производительностью и эффективностью.
Несмотря на значительный прогресс в области генерации аудио по видео, масштабирование моделей для обработки длинных последовательностей остается сложной задачей из-за ограниченности данных и расхождений между текстовыми описаниями и видеоинформацией. В данной работе, посвященной исследованию ‘Echoes Over Time: Unlocking Length Generalization in Video-to-Audio Generation Models’, представлена новая архитектура MMHNet, использующая некаузальную модель Mamba и иерархическое моделирование для генерации длинных аудиофрагментов. Предложенный подход позволяет значительно улучшить качество генерации аудио продолжительностью более 5 минут, демонстрируя возможность обучения на коротких видео и обобщения на длинные. Каковы перспективы дальнейшего развития иерархических моделей для решения задач мультимодального синтеза и расширения временного контекста?
Вызов длинных аудиопоследовательностей: Преодоление ограничений
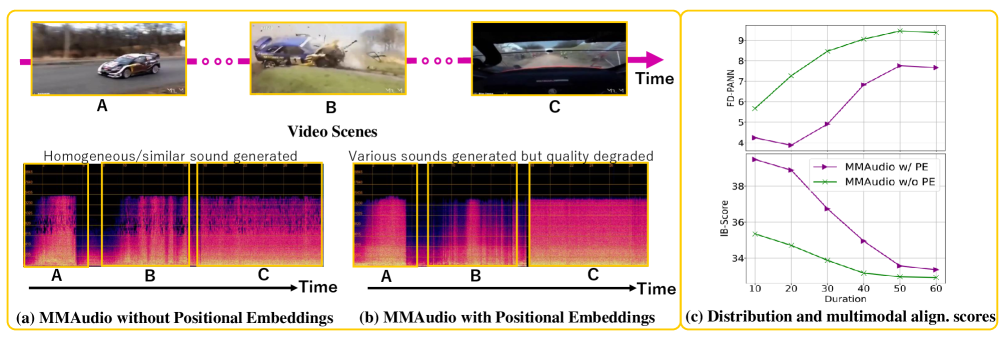
Существующие генеративные модели, особенно основанные на архитектуре Transformer, сталкиваются со значительными трудностями при обработке длинных последовательностей данных. Это ограничение связано с принципом работы позиционных кодировок, которые, несмотря на свою эффективность в улавливании порядка элементов в последовательности, теряют способность точно определять относительное положение элементов на больших расстояниях. В результате, при генерации длинных аудиозаписей, модель испытывает трудности с поддержанием когерентности и реалистичности звучания, что приводит к искажениям и потере информации. Проблема усугубляется экспоненциальным ростом вычислительной сложности при увеличении длины последовательности, что делает обработку длинных аудиофрагментов крайне ресурсоемкой задачей и требует разработки новых, более эффективных методов моделирования последовательностей.
Возникновение трудностей при генерации продолжительных аудиозаписей высокого качества представляет собой серьезную проблему для современных систем искусственного интеллекта. Ограничения существующих моделей, в особенности при работе с длинными последовательностями данных, приводят к тому, что сгенерированные звуковые фрагменты часто лишены реалистичности и внутренней связности. В результате, сложные музыкальные произведения, продолжительные повествования или правдоподобные звуковые ландшафты оказываются недостижимы, поскольку модели не способны поддерживать когерентность и детализацию на протяжении всей длительности аудиозаписи. Эта проблема требует разработки принципиально новых подходов к моделированию последовательностей, способных эффективно обрабатывать длинные временные интервалы и генерировать правдоподобные и связные аудиосигналы.
Современные методы генерации звука часто сталкиваются с необходимостью компромисса между качеством и продолжительностью. Стремление к созданию длинных аудиозаписей нередко приводит к ухудшению их реалистичности и когерентности, в то время как фокусировка на высоком качестве ограничивает максимальную длину генерируемого звука. Это обусловлено сложностями в моделировании долгосрочных зависимостей в аудиоданных, что требует разработки принципиально новых подходов к последовательному моделированию, способных эффективно обрабатывать длинные последовательности и сохранять высокое качество генерируемого звука на протяжении всей записи. Поиск баланса между этими двумя ключевыми характеристиками является одной из главных задач в области генерации звука и стимулирует появление инновационных решений.
MMHNet: Новая архитектура для генерации длинных аудиопоследовательностей
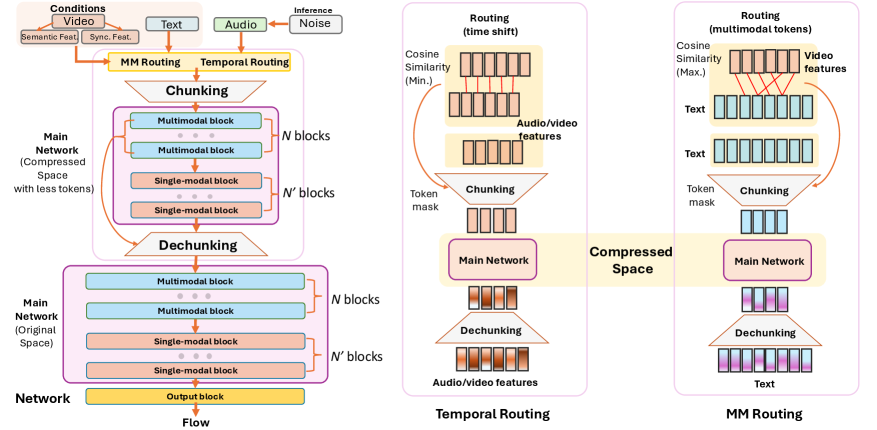
MMHNet представляет собой новую структуру, объединяющую архитектуру Mamba, известную своей эффективной обработкой длинных последовательностей данных, с надежными методами мультимодального выравнивания. Архитектура Mamba обеспечивает высокую производительность при работе с длинными входными последовательностями благодаря своей способности к селективной агрегации информации и линейной сложности по длине последовательности. В MMHNet это сочетается с методами мультимодального выравнивания, позволяющими эффективно интегрировать и сопоставлять информацию из различных источников данных, таких как текст, изображения и аудио, для повышения точности и надежности модели. Такая интеграция позволяет MMHNet эффективно обрабатывать сложные мультимодальные данные и решать задачи, требующие понимания взаимосвязей между различными модальностями.
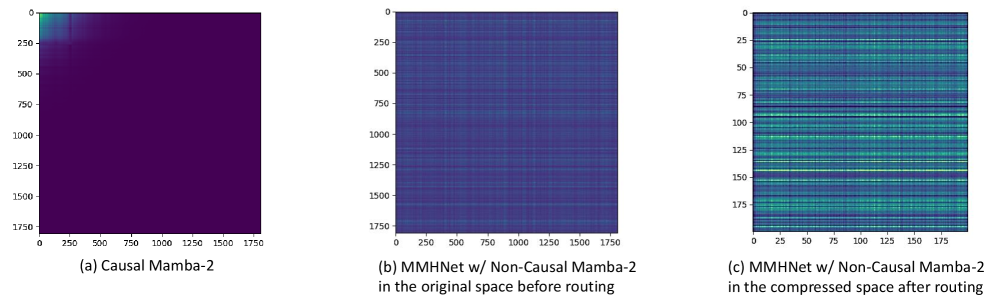
Архитектура MMHNet использует некаузальную обработку (Non-Causal Processing), что позволяет ей учитывать весь входной сигнал одновременно, в отличие от рекуррентных и свёрточных сетей, обрабатывающих данные последовательно или локально. Такой подход устраняет ограничения, связанные с необходимостью последовательной обработки данных и зависимостью от размера окна, характерные для традиционных методов. Некаузальность достигается за счет использования механизмов внимания и контекстного моделирования, позволяющих модели оценивать взаимосвязи между всеми элементами входной последовательности, независимо от их позиции, и эффективно захватывать глобальный контекст.
Иерархическая маршрутизация токенов является ключевой инновацией MMHNet, позволяющей избирательно направлять вычислительные ресурсы на наиболее значимые элементы входной последовательности. Этот механизм функционирует путем многоуровневой оценки релевантности каждого токена, определяя приоритетность обработки на основе иерархической структуры данных. В отличие от традиционных методов, которые обрабатывают все элементы последовательности с одинаковым уровнем внимания, данная система динамически распределяет ресурсы, концентрируясь на тех токенах, которые оказывают наибольшее влияние на конечный результат. Это позволяет значительно повысить эффективность вычислений и снизить потребность в вычислительной мощности, особенно при работе с длинными последовательностями данных.
Оценка MMHNet: Производительность и согласованность
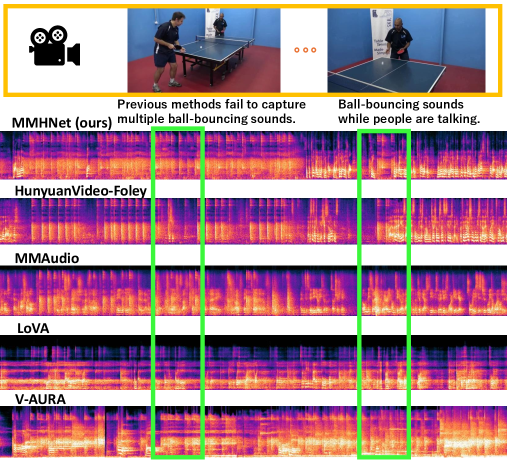
Обучение и оценка MMHNet проводилась на наборе данных VGGSound, что позволило продемонстрировать превосходство над базовыми моделями, такими как MMAudio. В ходе экспериментов было установлено, что MMHNet обеспечивает более высокое качество генерируемого аудио по сравнению с MMAudio, что подтверждается количественными метриками и субъективной оценкой. Использование VGGSound в качестве тренировочного и оценочного набора данных позволило эффективно обучить модель для генерации реалистичного и детализированного звука, превосходящего существующие решения в данной области.
Для оценки качества генерируемого звука MMHNet использовались количественные метрики Fréchet Distance (FD) и Inception Score (IS). Метрика FD измеряет расстояние между распределениями признаков сгенерированного и реального звука, при этом более низкие значения указывают на более высокую схожесть и реалистичность. Inception Score (IS) оценивает как четкость, так и разнообразие генерируемого звука, где более высокие значения соответствуют лучшему качеству. Результаты показали, что MMHNet демонстрирует улучшение по обеим метрикам по сравнению с базовыми моделями, подтверждая повышенную достоверность и реализм генерируемого аудио.
В ходе оценки MMHNet на наборе данных UnAV100, модель продемонстрировала передовые результаты, превзойдя предыдущие методы на 3.9 единиц по показателю IB-Score. Важно отметить, что MMHNet обеспечивает стабильную производительность при обработке видео различной длительности, что подтверждает её надежность и эффективность в задачах генерации аудио для видеоконтента. Это указывает на способность модели адаптироваться к различным временным масштабам и поддерживать высокое качество генерируемого звука независимо от продолжительности видеоряда.
Дополнительная валидация MMHNet показала улучшение показателя DeSync Score на 0.23 балла по результатам тестирования на наборе данных LongVale. Это свидетельствует о более высокой синхронизации сгенерированного звука и визуального контента. Кроме того, MMHNet демонстрирует двукратное увеличение скорости генерации 500 секунд звука по сравнению с моделью MMAudio, что указывает на значительное повышение эффективности обработки данных и снижения времени вычислений.
Для повышения мультимодальной согласованности MMHNet использует модели, такие как CLIP, ImageBind и Synchformer. Эти модели позволяют установить прочную корреляцию между сгенерированным аудио и соответствующими модальностями, такими как визуальный контент. CLIP обеспечивает согласованность между аудио и изображениями, ImageBind расширяет возможности согласования до нескольких модальностей (текст, изображения, аудио, тепловые данные и др.), а Synchformer специализируется на синхронизации аудио и видео, обеспечивая точное соответствие между звуком и визуальными изменениями. Интеграция этих моделей способствует созданию более реалистичного и контекстуально релевантного аудио.
Влияние и перспективы развития MMHNet
Способность MMHNet обрабатывать длительные последовательности данных без потери качества открывает новые горизонты в областях, требующих высокой реалистичности и детализации звука. В частности, это имеет огромное значение для синтеза речи, позволяя создавать голоса, неотличимые от человеческих, а также для генерации музыки и звуковых эффектов, достигающих беспрецедентного уровня натуральности и сложности. Благодаря этой возможности, MMHNet способна моделировать тонкие нюансы и длительные изменения в звуковом потоке, что ранее было недостижимо, и тем самым значительно расширяет творческие возможности в производстве аудиоконтента и интерактивных развлечений.
Архитектура MMHNet разработана с акцентом на модульность, что значительно упрощает её интеграцию с другими сенсорными и информационными потоками. Такая гибкость позволяет создавать системы, способные воспринимать и обрабатывать данные из различных источников — например, визуальную информацию, тактильные ощущения или данные о движении. Представьте себе интерактивную среду, где звук динамически меняется в зависимости от положения пользователя в пространстве, или виртуальную реальность, где тактильные ощущения синхронизированы с генерируемым звуком. Подобные мультимодальные взаимодействия открывают путь к созданию действительно захватывающих и реалистичных пользовательских опытов, выходящих за рамки традиционного аудио- или видео-воспроизведения и позволяющих создавать принципиально новые формы цифрового взаимодействия.
Дальнейшие исследования MMHNet сосредоточены на усовершенствовании методов выравнивания, что позволит добиться ещё более точной и стабильной генерации данных. Особый интерес представляет расширение возможностей данной архитектуры за пределы аудио, в частности, применение к синтезу видео и управлению робототехническими системами. Ученые предполагают, что оптимизированные алгоритмы выравнивания станут ключевым фактором успешной адаптации MMHNet к визуальным данным и сложным задачам управления, открывая перспективы для создания автономных систем, способных к обучению и адаптации в реальном времени. Исследовательская работа направлена на преодоление технических сложностей, связанных с обработкой многомерных данных и обеспечением согласованности между различными модальностями, что позволит создать универсальную платформу для мультимодального искусственного интеллекта.
Исследование, представленное в данной работе, демонстрирует стремление к элегантности в решении сложной задачи генерации длинных аудиопоследовательностей из видео. MMHNet, используя иерархическое моделирование и Non-Causal Mamba, предлагает подход, избегающий громоздкости традиционных трансформаторов. Это не просто технический прогресс, но и свидетельство глубокого понимания принципов эффективной обработки данных. Как однажды заметил Ян Лекун: «Машинное обучение — это прежде всего поиск подходящей структуры для представления данных». И действительно, предложенная архитектура MMHNet, фокусируясь на мультимодальном выравнивании и позиционных вложениях, представляет собой продуманную структуру, способную генерировать последовательные и реалистичные аудиопотоки, подтверждая, что изящность решения — признак глубокого понимания задачи.
Куда ведут эхо?
Представленная работа, несомненно, демонстрирует элегантность подхода к генерации длинных аудиопоследовательностей. Однако, как часто бывает, решение одной задачи обнажает новые грани нерешенных проблем. Проблема выравнивания модальностей, несмотря на достигнутый прогресс, остается тонким искусством, требующим более глубокого понимания взаимосвязи между визуальным и звуковым мирами. В конечном счете, простого увеличения длины сгенерированного фрагмента недостаточно; необходимо обеспечить его когерентность и осмысленность на протяжении всего временного отрезка.
Появление архитектур, таких как Mamba, открывает новые горизонты, но следует помнить, что сама по себе инновация в архитектуре не гарантирует интеллектуального прозрения. Важно исследовать возможности интеграции иерархических моделей с другими подходами, избегая соблазна слепого копирования успешных решений. Следующим шагом видится разработка методов, позволяющих модели не просто «воспроизводить» звук, но и «понимать» контекст и намерения, стоящие за визуальным рядом.
Возможно, истинная красота в этой области проявится не в достижении абсолютной точности, а в создании моделей, способных к импровизации и генерации неожиданных, но гармоничных звуковых ландшафтов. И тогда, возможно, эхо времени зазвучат по-настоящему.
Оригинал статьи: https://arxiv.org/pdf/2602.20981.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Сияние фотонов: новый уровень точности в предсказаниях столкновений частиц
- Эхо чёрных дыр: как квантовая гравитация меняет гравитационные волны
- Распознавание смыслов: новый подход к классификации документов
- Сверхпроводящая логика: управление магнитным полем
- Луна раскрывает свои секреты: Искусственный интеллект восстанавливает древнюю формулу
- Управляемое автодополнение кода: новые вызовы и решения
- Запросы к данным о пространстве и времени: новый язык общения
- Ожившие Истории: Искусственный Интеллект, Создающий и Редактирующий Аудио
- Квантовые смеси: от капель жидкости до сверхтекучих кристаллов
- Укрощение периодических возмущений: новый взгляд на двухуровневые системы
2026-03-01 03:04