Автор: Денис Аветисян
Представлена онлайн-платформа RoboChallenge, позволяющая оценить способность роботов понимать язык и выполнять действия в реальном мире.

Исследователи создали масштабный бенчмарк Table30 для всесторонней оценки навыков роботов в задачах, требующих взаимодействия с окружающим миром.
Несмотря на прогресс в области обучения с подкреплением и моделей «зрение-язык-действие», оценка этих алгоритмов на реальных роботах остается сложной задачей. В данной работе представлена система ‘RoboChallenge: Large-scale Real-robot Evaluation of Embodied Policies’ – онлайн платформа для масштабного тестирования роботизированных систем, использующих модели VLA. Ключевым результатом является создание эталонного набора из 30 задач (Table30), предназначенного для всесторонней оценки обобщающих способностей роботов. Сможет ли RoboChallenge стать стандартом для объективной оценки и сравнения алгоритмов управления роботами в различных условиях?
Вызовы Роботизированного Разума
Современные роботизированные системы испытывают трудности при выполнении сложных задач, требующих адаптивного мышления и обобщения. Существующие подходы ограничены предварительно запрограммированными поведениями, что снижает их устойчивость в динамичных средах. Ключевым узким местом является интеграция визуальной информации, языка и действий. Отсутствие этой интеграции препятствует созданию гибких систем, способных решать новые задачи. Таким образом, необходимы новые фреймворки для разработки интеллектуальных и универсальных агентов, способных к обучению и адаптации в условиях неопределенности.
Красота алгоритма проявляется в его непротиворечивости и предсказуемости.
RoboChallenge: Платформа для Оценки VLA
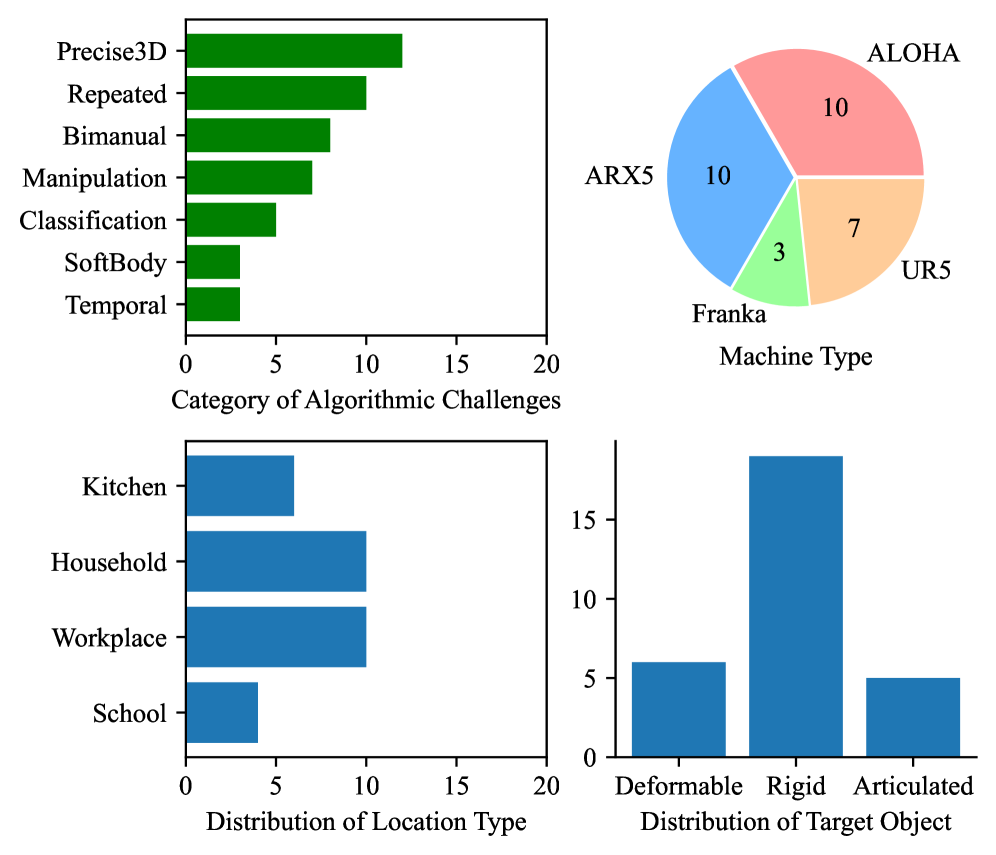
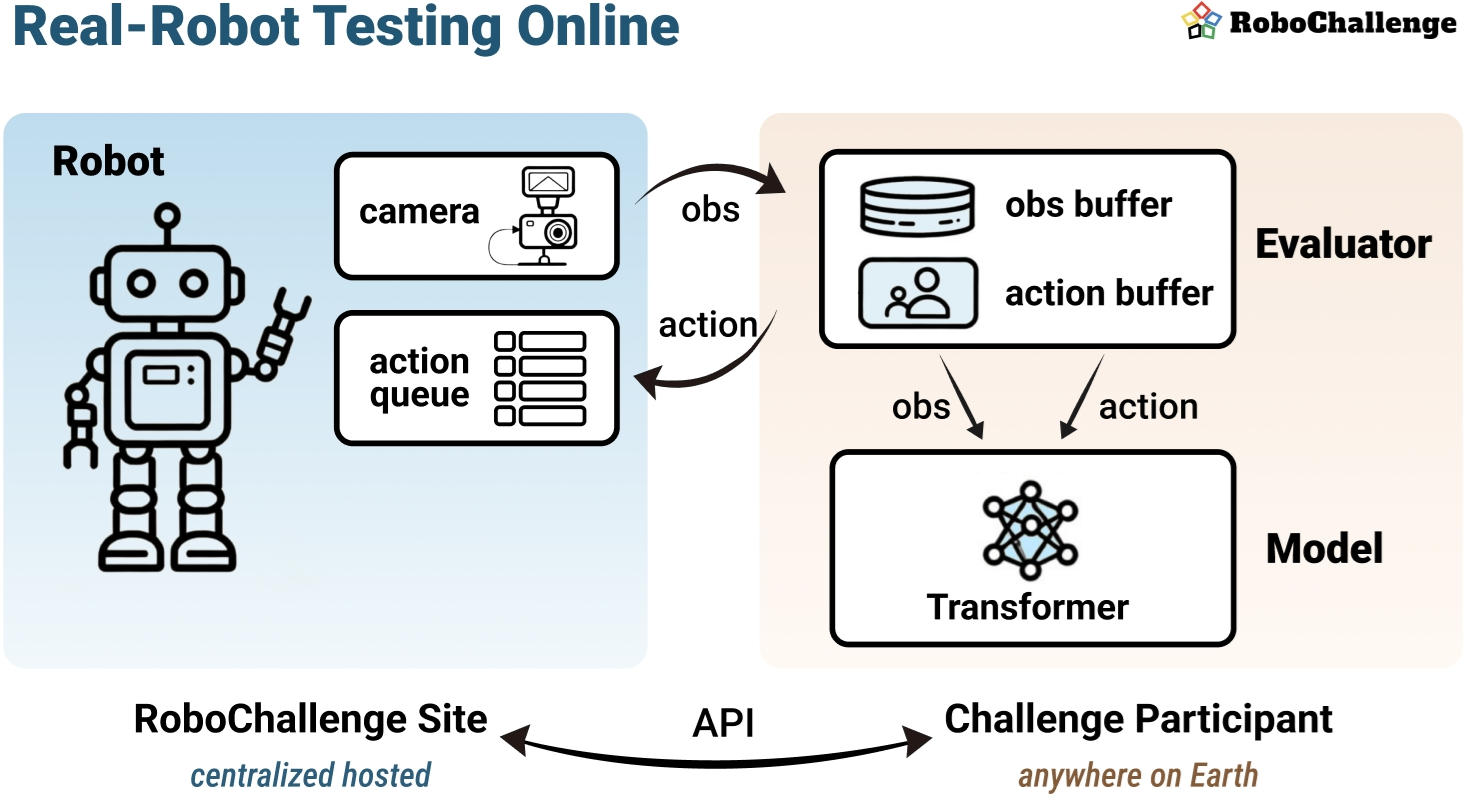
Система RoboChallenge – комплексная платформа для оценки моделей Vision-Language-Action (VLA). Она предоставляет стандартизированную среду для тестирования и сравнения различных подходов в робототехнике и искусственном интеллекте. В состав системы входит парк из десяти роботизированных манипуляторов (UR5, Franka Panda, ARX-5, Cobot Magic Aloha). Разнообразие оборудования обеспечивает более широкую применимость и превосходит по масштабу многие существующие онлайн-системы. Для надежного восприятия окружающей среды используются камеры Realsense RGBD.
Ключевой особенностью RoboChallenge является парадигма Remote Robot, позволяющая исследователям тестировать модели без сложной аппаратной настройки, упрощая разработку и валидацию алгоритмов.
Table30: Строгий Бенчмарк для VLM
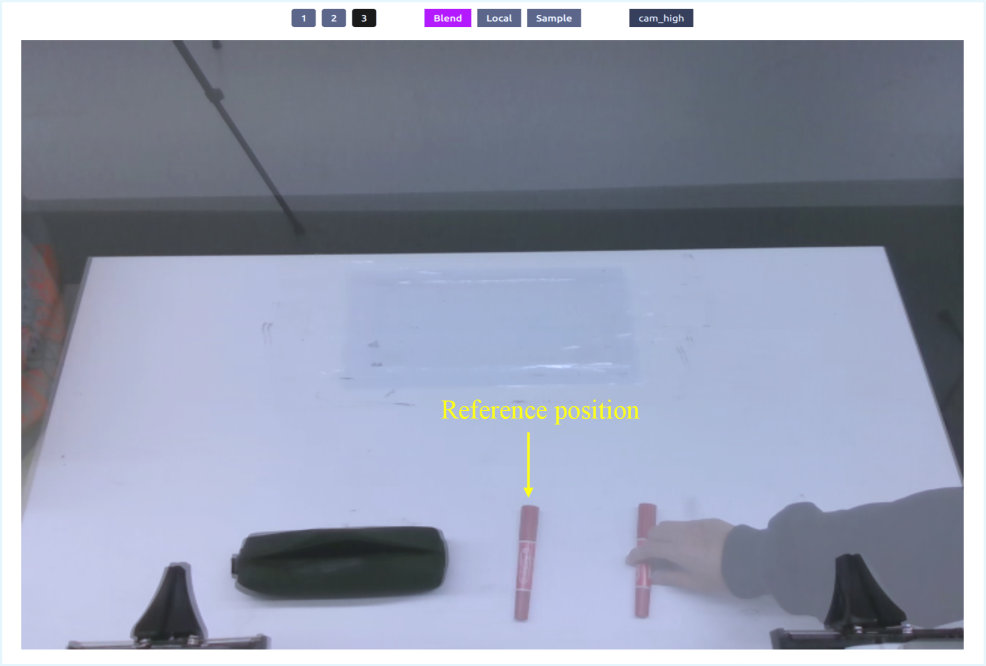
Бенчмарк Table30 состоит из 30 разнообразных задач, выполняемых вокруг стола, и предназначен для оценки возможностей визуальных языковых моделей (VLM) в реалистичном сценарии. Для обеспечения воспроизводимости результатов применяется методика Visual Task Reproduction. Ключевые метрики (Success Rate и Progress Score) количественно оценивают производительность моделей, при этом максимальный Progress Score для каждой задачи равен 10. Бенчмарк поддерживает Task-Specific и Generalist протоколы, позволяя провести всестороннюю оценку моделей. Общий максимальный балл за 10 прогонов составляет 100.
Влияние на Будущее Робототехники
Система RoboChallenge и эталонный набор Table30 ускоряют разработку адаптивных и интеллектуальных роботизированных агентов, стимулируя сотрудничество и инновации. Возможность надежной оценки VLA открывает новые возможности применения в производстве, здравоохранении и других сферах. Стандартизированный подход способствует созданию надежных, универсальных и доступных роботизированных решений.
Строгость и точность оценки определяют истинную ценность алгоритма, а не только его работоспособность.
Представленная работа демонстрирует стремление к созданию надёжных и доказуемых систем искусственного интеллекта, что находит отклик в словах Джона Маккарти: «Всякий интеллект — это способность решать сложные задачи в новых ситуациях.». RoboChallenge, как платформа для оценки политик воплощенного ИИ в реальном мире, ставит перед собой задачу не просто достижения успеха на обучающей выборке, но и проверки обобщающей способности роботов. Разнообразие задач в Table30, охватывающее широкий спектр визуально-языковых команд, подчёркивает важность алгоритмической точности и минимизации неопределённости в принятии решений. Любая неточность в интерпретации команд или выполнении действий потенциально приводит к ошибке, а значит, к несоответствию математической чистоте, к которой стремится истинная элегантность кода.
Что Дальше?
Представленная платформа RoboChallenge и набор задач Table30, безусловно, представляют собой шаг вперед в оценке политик, объединяющих зрение, язык и действие. Однако, пусть N стремится к бесконечности – что останется устойчивым? Очевидно, сама концепция «бенчмарка» в области робототехники таит в себе противоречие. Любой фиксированный набор задач неизбежно становится узким местом, поощряющим оптимизацию под конкретные условия, а не развитие истинной, обобщенной компетентности. Необходимо признать, что успех в Table30 – это успех в решении этих задач, а не гарантия надежной работы в реальном, непредсказуемом мире.
По-настоящему интересным представляется не увеличение количества задач, а разработка метрик, способных оценить не только успешное выполнение, но и эффективность и адаптируемость политик. Насколько быстро и элегантно система реагирует на изменения в окружающей среде? Насколько мало ресурсов требуется для обучения и функционирования? Эти вопросы, по сути, касаются фундаментальных принципов термодинамики и теории информации – аспектов, которые часто упускаются из виду в погоне за высокой точностью на ограниченном наборе данных.
В конечном итоге, истинный прогресс в области робототехники будет заключаться не в создании систем, способных решать все больше и больше задач, а в разработке принципов, позволяющих создавать системы, способные учиться и адаптироваться к любым задачам. Только тогда мы сможем говорить о создании действительно разумных и автономных роботов.
Оригинал статьи: https://arxiv.org/pdf/2510.17950.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Когда мнения расходятся: как модели принимают решения при конфликте данных
- Оптимизация больших языковых моделей: новый подход к снижению требований к ресурсам
- Квантовые вычисления с кубитами высшего порядка: новый подход к моделированию
- Белки-хамелеоны: Пределы предсказания гибкости структуры
- Визуальный интеллект: обучение рассуждению через головоломки
- Динамика в кадре: Как научить ИИ понимать физику видео
- Энергоэффективность сотовой сети: обучение с подкреплением и управление режимами сна
- Первый кадр: Ключ к персонализации видео
- Детализация без компромиссов: новый подход к синтезу видов
- Квантовые вычисления: формальная логика для надежности программ
2025-11-06 01:23