Автор: Денис Аветисян
Новая система позволяет автоматически переводить наборы данных и тесты для оценки языковых моделей на разных языках, повышая надежность и эффективность анализа.
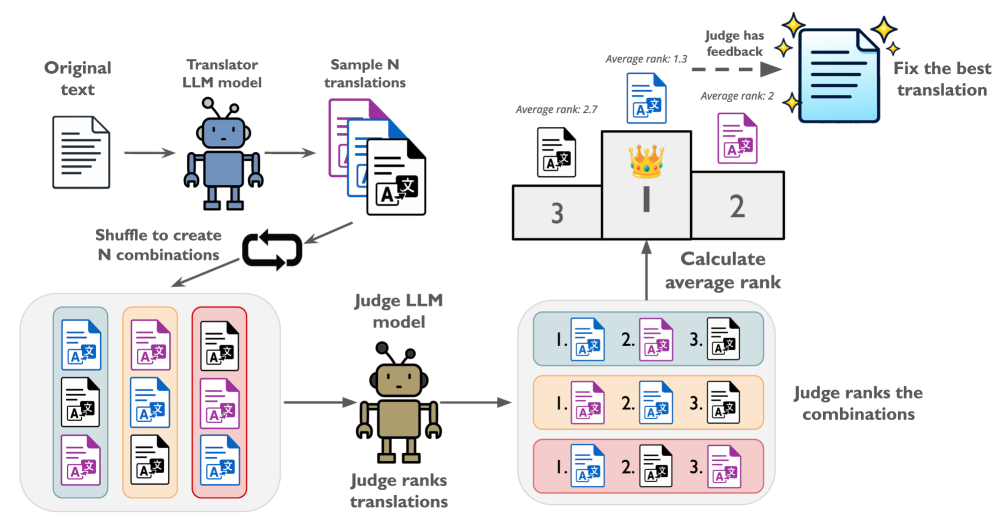
Представлен эффективный конвейер автоматического перевода бенчмарков и наборов данных с акцентом на качество и масштабируемость.
Надежность многоязычной оценки больших языковых моделей (LLM) зачастую страдает из-за непостоянного качества перевода эталонных наборов данных. В статье ‘Recovered in Translation: Efficient Pipeline for Automated Translation of Benchmarks and Datasets’ представлен автоматизированный подход к решению этой проблемы, обеспечивающий масштабируемый и высококачественный перевод эталонов и наборов данных. Применение стратегий масштабирования вычислений во время тестирования, включая Universal Self-Improvement и разработанный авторами метод T-RANK, позволило значительно повысить качество перевода. Сможет ли предложенный фреймворк стать стандартом для создания надежных и воспроизводимых многоязычных систем оценки LLM?
Многоязычный Вызов: Границы Автоматического Перевода
Несмотря на впечатляющие возможности больших языковых моделей в области перевода, всестороннее и достоверное оценивание их работы на различных языках остается сложной задачей. Модели демонстрируют успехи в переводе между наиболее распространенными языками, однако их производительность существенно снижается при работе с языками, для которых существует ограниченное количество обучающих данных. Проблема усугубляется сложностью лингвистических структур, вариативностью значений и культурными нюансами, которые зачастую игнорируются при автоматическом переводе. В результате, даже кажущийся адекватным перевод может содержать неточности или искажения, что ставит под сомнение надежность и универсальность этих моделей в многоязычной среде. Необходимы более сложные метрики и методы оценки, учитывающие не только лексическую точность, но и семантическую корректность и стилистическую уместность перевода.
Существующие многоязычные бенчмарки, предназначенные для оценки возможностей больших языковых моделей, часто демонстрируют недостатки в качестве перевода и недостаточное покрытие языков с ограниченными ресурсами. Особенно остро эта проблема проявляется в отношении языков со сложной грамматикой, где нюансы и исключения могут существенно искажаться при автоматическом переводе. Это приводит к тому, что оценка производительности моделей на таких языках становится неточной и не отражает реальные возможности системы. Недостаток качественных данных для обучения и тестирования, а также сложность учета лингвистических особенностей, обуславливают необходимость разработки новых, более совершенных бенчмарков, способных адекватно оценивать производительность моделей в отношении всех языков, независимо от их сложности и распространенности.
Создание и поддержание многоязычных эталонов оценки, необходимых для объективного тестирования больших языковых моделей, требует значительных ресурсов — как финансовых, так и человеческих. В то время как усилия по сбору и аннотации языковых данных активно финансируются и поддерживаются, разработка качественных эталонов зачастую остается в тени. Это связано с тем, что создание эталона требует не только больших объемов данных, но и экспертизы в лингвистике, кросс-лингвистической валидации и обеспечении репрезентативности для различных языков и диалектов. В результате, появляется дисбаланс: модели обучаются на обширных корпусах, но оцениваются по эталонам, которые могут быть недостаточно полными, актуальными или справедливыми для всех языков, что снижает надежность и объективность оценки их реальных возможностей.
Автоматизированный Перевод: Архитектура Самообучения
Представленный Автоматизированный Фреймворк Перевода предназначен для эффективной обработки наборов данных и эталонных тестов с минимальным вмешательством человека. Фреймворк автоматизирует процесс перевода, снижая потребность в ручной проверке и корректировке результатов. Это достигается за счет использования алгоритмов, способных самостоятельно оценивать качество перевода и вносить необходимые улучшения, что позволяет значительно ускорить процесс локализации и адаптации данных для различных языковых сред. Основной акцент сделан на масштабируемость и возможность обработки больших объемов информации без существенного снижения точности.
Для повышения точности и устойчивости автоматизированного перевода, фреймворк использует методы самопроверки перевода (Self-Check Translation) и выборки лучших из N вариантов (Best-of-N Sampling). Самопроверка перевода предполагает генерацию нескольких вариантов перевода, после чего модель самостоятельно оценивает их качество и выбирает наиболее вероятный. Best-of-N Sampling подразумевает генерацию N различных переводов, из которых система выбирает перевод с наивысшим рейтингом, основываясь на внутренних метриках оценки качества. Комбинирование этих подходов позволяет снизить вероятность ошибок и повысить общую надежность результатов автоматического перевода, особенно в сложных или неоднозначных случаях.
В рамках автоматизированной системы перевода используются методы Universal Self-Improvement (USI) и Translation Ranking (T-RANK) для систематической доработки переводов и выявления потенциальных ошибок. USI предполагает, что модель самостоятельно генерирует альтернативные варианты перевода и оценивает их качество, используя внутренние критерии и обратную связь. T-RANK ранжирует полученные переводы на основе различных метрик, включая вероятность, согласованность и соответствие исходному тексту. Комбинирование USI и T-RANK позволяет автоматически улучшать качество перевода, выявлять неточности и предлагать более предпочтительные варианты, минимизируя необходимость ручной проверки и корректировки.

Повышение Надежности: Инструменты Адаптации и Согласованности
Для повышения производительности, наша платформа использует методы адаптивной few-shot подсказки и TEaR (Training data selection with Error Reduction). Адаптивная few-shot подсказка динамически подбирает примеры из небольшого набора данных, оптимизируя процесс обучения модели для конкретной задачи. TEaR, в свою очередь, позволяет осуществлять отбор обучающих данных с целью минимизации ошибок и улучшения обобщающей способности модели. Оба подхода обеспечивают динамическую оптимизацию и самосовершенствование системы, позволяя ей адаптироваться к изменяющимся требованиям и повышать точность переводов.
Универсальная самосогласованность (Universal Self-Consistency) представляет собой метод, направленный на повышение надежности машинного перевода путем проверки соответствия выбранного варианта перевода множеству различных перспектив и интерпретаций исходного текста. Этот подход предполагает генерацию нескольких возможных переводов и последующую оценку их согласованности друг с другом и с исходным текстом. В случае расхождений, система стремится к выявлению и устранению противоречий, выбирая перевод, наиболее устойчивый и логичный с точки зрения различных интерпретаций. Использование данного метода позволяет минимизировать вероятность ошибок, вызванных неоднозначностью исходного текста или неточностями в процессе перевода, обеспечивая более точные и надежные результаты.
Метод Fusion-of-N обеспечивает синтез информации из нескольких вариантов перевода, что приводит к более полным и точным результатам. Данная техника предполагает генерацию N различных кандидатов перевода для исходного текста. Затем, эти кандидаты анализируются и объединяются, используя алгоритмы взвешенного усреднения или более сложные модели, чтобы создать итоговый перевод, который учитывает различные интерпретации и нюансы исходного текста. Это позволяет снизить вероятность ошибок и повысить общую достоверность перевода, особенно в случаях неоднозначности или сложности исходного материала.
Проверка и Расширение Горизонтов: Влияние на Мультиязыковое Обучение
Применение разработанной системы к стандартным наборам данных для машинного перевода, таким как WMT24++ и FLORES, позволило добиться существенного улучшения качества перевода. Объективная оценка, проведенная с использованием метрики COMET, продемонстрировала значительный прирост баллов по сравнению с существующими подходами. Данный результат указывает на эффективность предложенного фреймворка в решении сложных задач машинного перевода и открывает возможности для дальнейшей оптимизации и адаптации к различным языковым парам. Повышение качества перевода, подтвержденное количественными показателями, является важным шагом к созданию более точных и надежных систем автоматического перевода.
Автоматизированный подход позволил расширить известные бенчмарки, такие как MMLU, до многоязычной среды, что привело к созданию Global-MMLU — платформы для оценки кросс-лингвального рассуждения. Исследования показали, что предложенный метод демонстрирует превосходные результаты при переводе MMLU по сравнению с существующими переводами, обеспечивая более точную и надежную оценку способностей моделей к рассуждению на различных языках. Это расширение открывает новые возможности для разработки и оценки мультиязычных моделей искусственного интеллекта, позволяя более эффективно оценивать их способность понимать и обрабатывать информацию на разных языковых уровнях.
Разработанный MuBench, расширенный для многоязыковой оценки, предоставляет ценный ресурс для совершенствования моделей обработки естественного языка. Платформы, такие как Okapi, могут использовать эту расширенную базу данных для более точной настройки многоязыковой обучаемости. Результаты демонстрируют улучшение оценочных показателей моделей в украинском, румынском, словацком, литовском, болгарском, турецком, греческом и эстонском языках. Этот подход позволяет не только повысить качество перевода и понимания, но и создать более надежные и универсальные языковые модели, способные эффективно функционировать в различных лингвистических контекстах.
В представленной работе акцент сделан на автоматизацию процесса перевода эталонных наборов данных, что позволяет повысить надежность многоязычной оценки языковых моделей. Это напоминает о взглядах Джона Маккарти, который однажды заметил: «Системы должны быть спроектированы так, чтобы быть устойчивыми к ошибкам, а не просто избегать их.». Действительно, подход, предложенный в статье, не просто устраняет языковые барьеры, но и создает основу для более гибких и адаптивных систем оценки. Автоматизация перевода — это не статичное решение, а скорее, эволюционирующая экосистема, способная к самокоррекции и масштабированию, что соответствует принципам устойчивости, подчеркиваемым Маккарти. По сути, представленный фреймворк — это попытка создать систему, способную предвидеть и адаптироваться к неизбежным ошибкам перевода, а не просто их избегать.
Что Дальше?
Представленный подход к автоматизированному переводу эталонных наборов данных, несомненно, облегчает задачу многоязычной оценки языковых моделей. Однако, иллюзия контроля над сложностью не должна заслонять истину: система лишь переносит проблему с одной области в другую. Перевод — это не нейтральное преобразование, а интерпретация, и каждая автоматизированная интерпретация несет в себе отпечаток предубеждений и ограничений используемой модели.
Улучшение качества перевода — это лишь отсрочка неизбежного. Распределенная система, разделенная на микросервисы перевода, лишь множит потенциальные точки отказа. В конечном счете, всё связанное когда-нибудь рухнет синхронно, и даже самая тщательная валидация перевода не сможет предотвратить каскад ошибок, когда система столкнется с неожиданными входными данными. Вместо того чтобы стремиться к идеальному переводу, возможно, стоит сосредоточиться на разработке моделей, устойчивых к неточностям и неоднозначностям.
Настоящим вызовом является не создание идеального инструмента, а взращивание экосистемы, в которой ошибки рассматриваются не как провалы, а как неизбежные шаги на пути к пониманию. Попытка контролировать сложность — это иллюзия. Системы не строятся, они растут, и их эволюцию невозможно предсказать.
Оригинал статьи: https://arxiv.org/pdf/2602.22207.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Эхо чёрных дыр: как квантовая гравитация меняет гравитационные волны
- Распознавание смыслов: новый подход к классификации документов
- Сверхпроводящая логика: управление магнитным полем
- Сияние фотонов: новый уровень точности в предсказаниях столкновений частиц
- Интеллектуальные агенты: как воплотить опыт экспертов в искусственный интеллект
- Глубинное зрение роботов: новый подход к обучению восприятию
- Квантовые вычисления: Честность и Прогресс
- Воссоздавая интерьеры: новый подход к 3D-реконструкции
- Финансовый интеллект машин: новый тест на прочность
- Искусственный интеллект и кодер: меняется ли подход к разработке?
2026-03-03 05:26