Автор: Денис Аветисян
Новый подход позволяет создавать персонализированные видео и аудио, сохраняя уникальные черты человека и реагируя на текстовые запросы.

Представлен метод ID-LoRA для унифицированной персонализации аудио-видео контента с использованием адаптеров LoRA и кросс-модального внимания, превосходящий существующие каскадные решения.
Существующие методы персонализации видео часто рассматривают визуальные и аудио компоненты раздельно, что затрудняет синхронизацию звука с происходящим на экране и контроль над стилем речи. В данной работе представлена новая методика ‘ID-LoRA: Identity-Driven Audio-Video Personalization with In-Context LoRA’, позволяющая одновременно генерировать облик и голос объекта, сохраняя его идентичность и реагируя на текстовые запросы для обеих модальностей. Предложенный подход, использующий адаптацию модели LTX-2 с помощью In-Context LoRA, демонстрирует превосходство над каскадными методами, обеспечивая более высокую схожесть голоса и стиля речи. Способна ли эта технология открыть новые горизонты в создании реалистичного и персонализированного мультимедийного контента?
Синхронизация аудио и видео: вызов современной искусственного интеллекта
Создание реалистичного и синхронизированного аудиовизуального контента остается сложной задачей для современных систем искусственного интеллекта. Несмотря на значительный прогресс в генеративных моделях, достижение полной согласованности между визуальными и звуковыми элементами представляет собой серьезную проблему. Искусственный интеллект часто испытывает трудности в обеспечении того, чтобы движения губ персонажа соответствовали произносимым словам, или чтобы звуковые эффекты органично сочетались с происходящими на экране событиями. Это несоответствие может приводить к эффекту «зловещей долины», когда создаваемый контент кажется неестественным и вызывает дискомфорт у зрителя. Достижение бесшовной интеграции аудио и видео требует разработки сложных алгоритмов, способных учитывать тончайшие нюансы человеческого восприятия и обеспечивать максимальную реалистичность генерируемого контента.
Существующие методы генерации аудиовизуального контента зачастую сталкиваются с проблемой поддержания согласованности между звуком и изображением, что приводит к неестественным результатам. Несмотря на значительные успехи в отдельных областях, таких как генерация реалистичных изображений или синтез речи, объединение этих процессов в единую, когерентную систему остается сложной задачей. Часто наблюдается рассинхронизация, когда движения губ на сгенерированном видео не соответствуют произносимым словам, или когда звуковые эффекты не согласуются с происходящими на экране событиями. Данные несоответствия, даже незначительные, способны существенно снизить восприятие реалистичности и вызвать эффект “зловещей долины”, когда созданный контент вызывает дискомфорт у зрителя. Разработка алгоритмов, способных учитывать сложные взаимосвязи между аудио- и визуальными данными, и обеспечивающих их синхронное и правдоподобное воспроизведение, является ключевым направлением современных исследований в области искусственного интеллекта.
Растущий спрос на высококачественный контент, созданный искусственным интеллектом, стимулирует поиск инновационных подходов к решению существующих ограничений. В различных сферах, от развлечений и образования до маркетинга и научных исследований, появляется потребность в реалистичных и синхронизированных аудиовизуальных материалах. Эта потребность подталкивает исследователей к разработке новых алгоритмов и моделей, способных генерировать контент, который не только визуально привлекателен, но и звучит естественно и убедительно. Особенно актуальна задача обеспечения согласованности между аудио и видеопотоками, поскольку несоответствие может существенно снизить качество и восприятие созданного контента. Таким образом, потребность в улучшении качества и реалистичности AI-генерируемого контента становится ключевым фактором, определяющим направление развития исследований в данной области.

Диффузионные модели: новый подход к персонализации аудиовизуального контента
Диффузионные модели зарекомендовали себя как эффективный инструмент для генерации высококачественных изображений и видеоматериалов. В основе их работы лежит процесс постепенного добавления шума к данным до тех пор, пока не будет получен случайный шум, а затем — обратный процесс, в ходе которого модель обучается восстанавливать исходные данные из шума. Этот подход позволяет создавать реалистичные и детализированные изображения и видео, превосходящие по качеству результаты, полученные с помощью других генеративных моделей, таких как генеративно-состязательные сети (GAN). Особенностью диффузионных моделей является их способность генерировать разнообразный контент, сохраняя при этом высокую степень согласованности и реализма.
Адаптация диффузионных моделей для аудиовизуальной персонализации требует внедрения информации об идентичности без ухудшения качества генерируемого контента. Этот процесс представляет собой сложную задачу, поскольку прямое добавление данных об идентичности может привести к искажению или снижению реалистичности результатов. Эффективные методы персонализации стремятся сохранить высокую степень детализации и естественности, одновременно точно передавая желаемые характеристики идентичности, такие как тембр голоса или черты лица. Достижение оптимального баланса между сохранением качества и внедрением идентичности является ключевым фактором успеха в данной области.
Методы, такие как ID-LoRA и InstantID, обеспечивают эффективную передачу характеристик идентичности в генерируемый контент, повышая реалистичность и контроль. В ходе тестирования на наборе данных CelebV-HQ hard split, эти методы достигли оценки схожести голосов 0.477, что на 8.6% превышает показатели существующих базовых моделей. Данный подход позволяет добиться более точной персонализации аудиовизуального контента без значительных вычислительных затрат, сохраняя при этом высокое качество генерируемого материала.
Эффективный перенос идентичности: техники и архитектуры
ID-LoRA использует методы LoRA (Low-Rank Adaptation) и In-Context LoRA для эффективной адаптации базовой диффузионной модели для переноса идентичности. LoRA позволяет обучать лишь небольшое количество параметров, добавляемых к существующей модели, значительно снижая вычислительные затраты и требования к памяти. In-Context LoRA дополнительно оптимизирует этот процесс, позволяя адаптировать модель к конкретной идентичности непосредственно во время генерации, используя лишь несколько примеров. Такой подход обеспечивает быструю адаптацию и генерацию контента с сохранением целевой идентичности при минимальном потреблении ресурсов.
Для обеспечения точного и последовательного представления идентичности в задачах переноса, используются методы Negative Temporal Positions и Identity Guidance. Negative Temporal Positions позволяют модели игнорировать временные смещения в данных, что улучшает стабильность переноса идентичности во времени. Identity Guidance, в свою очередь, использует градиенты, направленные на сохранение ключевых характеристик исходной идентичности в процессе генерации, минимизируя искажения и обеспечивая сохранение уникальных черт. Комбинация этих техник позволяет добиться более реалистичного и правдоподобного переноса идентичности в мультимодальных данных.
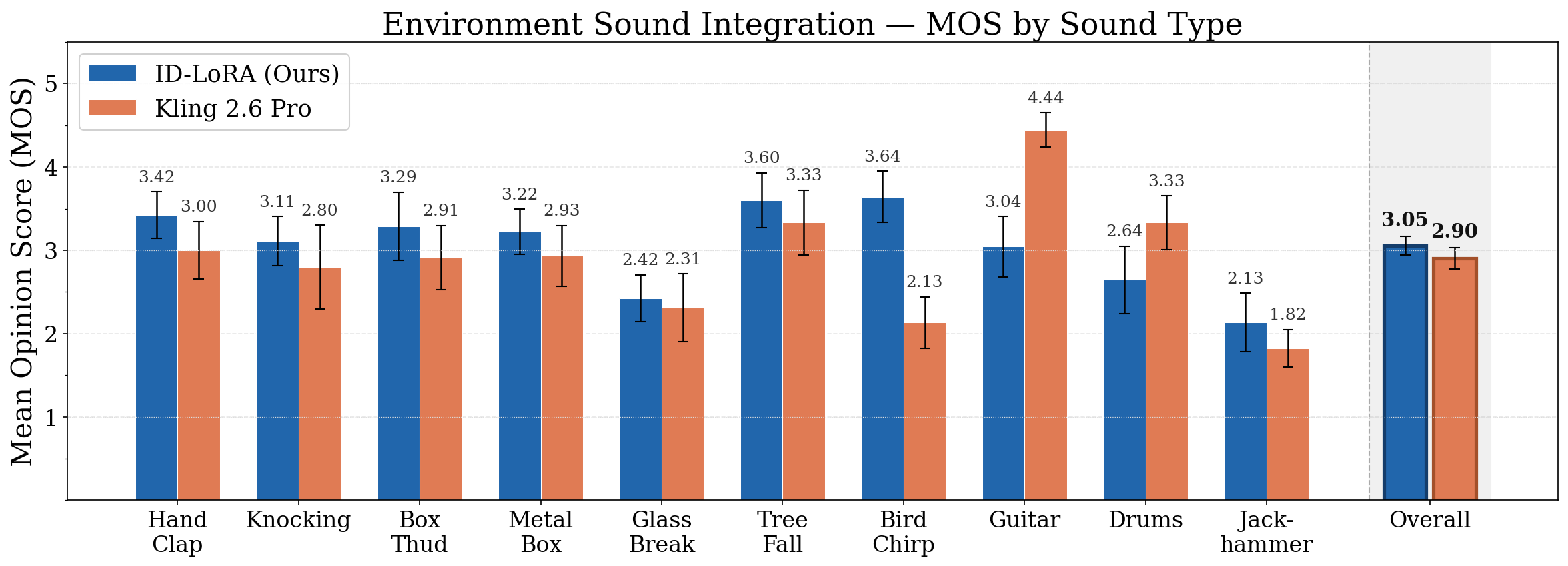
Архитектура DiT, в сочетании с видео- и аудио-VAE, обеспечивает надежную основу для обработки и генерации синхронизированного аудиовизуального контента. В ходе тестирования на сценариях, имитирующих физическое взаимодействие, система продемонстрировала среднюю оценку качества (MOS) в 3.05 балла. Это превосходит показатель, полученный системой Kling 2.6 Pro, который составил 2.90 балла при аналогичных условиях.
Расширение области применения: приложения и будущие направления
Персонализация видеоконтента, осуществляемая посредством таких методов, как EditYourself и Just-Dub-It, открывает принципиально новые горизонты в создании и редактировании видеоматериалов. Эти технологии позволяют адаптировать видео не только по содержанию, но и по голосу, стилю повествования, а также окружению, что значительно повышает вовлеченность зрителя. Возможность легко изменять отдельные элементы видео, заменяя голоса или звуки, позволяет создавать уникальные версии контента, ориентированные на конкретную аудиторию или даже на индивидуальные предпочтения пользователя. Такая гибкость особенно ценна для создателей контента, стремящихся к максимальной персонализации и интерактивности, а также для платформ, желающих предоставить пользователям более индивидуализированный опыт.
Интеграция моделей клонирования голоса, работающих по принципу «zero-shot», таких как CosyVoice 3.0, ElevenLabs и VoiceCraft, значительно расширяет возможности персонализации и реалистичности мультимедийного контента. Эти модели, способные воспроизводить голос на основе минимального количества данных или даже без них, позволяют создавать видеоролики и аудиозаписи с индивидуальным озвучиванием, адаптированным под конкретного пользователя или ситуацию. Такой подход открывает новые перспективы в области создания обучающих материалов, развлекательного контента и интерактивных приложений, где требуется динамическое изменение голоса или создание уникальных персонажей. Способность к мгновенному клонированию голоса и адаптации к различным эмоциональным окраскам позволяет достичь беспрецедентного уровня погружения и вовлеченности аудитории.
Исследования показали значительное превосходство модели ID-LoRA над существующими аналогами в задачах персонализированного аудиосопровождения. В ходе A/B тестирования ID-LoRA продемонстрировала предпочтение в 80,7% случаев при оценке схожести голоса, что существенно выше показателя в 17,5% для комбинации ElevenLabs и WAN2.2. Аналогичная тенденция наблюдается и в отношении реалистичности окружающих звуков: ID-LoRA достигла 68,7% предпочтения, в то время как ElevenLabs + WAN2.2 — лишь 5,6%. Эти результаты указывают на потенциал ID-LoRA в качестве ключевой технологии для создания более реалистичного и привлекательного аудиовизуального контента, открывая новые возможности для приложений в сфере развлечений, образования и коммуникаций.

К универсальному аудиовизуальному созданию
Единые модели, такие как Apollo и VACE, знаменуют собой важный прорыв в создании аудиовизуального контента, объединяя процессы генерации видео и звука в рамках одной нейронной сети. В отличие от традиционных подходов, требующих раздельной обработки и последующей синхронизации, эти модели способны генерировать согласованные аудио- и видеоматериалы одновременно, что существенно упрощает рабочий процесс и открывает новые возможности для творчества. Это позволяет создавать более реалистичные и захватывающие медиа, а также автоматизировать задачи, ранее требовавшие значительных усилий и профессиональных навыков. Такое решение не только повышает эффективность, но и способствует развитию новых форм искусства и развлечений, где звук и изображение неразрывно связаны.
Постоянное совершенствование методов эффективной дообучения, таких как LoRA и IC-LoRA, в сочетании с разработкой надежных архитектур, является ключевым фактором для дальнейшего прогресса в области универсального аудиовизуального контента. Эти техники позволяют значительно снизить вычислительные затраты и объемы необходимых данных для адаптации моделей к новым задачам, не жертвуя при этом качеством генерируемого контента. Исследования в этом направлении направлены на создание более гибких и доступных инструментов для создания мультимедийных материалов, открывая возможности для более широкого круга пользователей и приложений, от автоматизированного производства контента до персонализированных мультимедийных впечатлений.
Исследования показали, что метод ID-LoRA демонстрирует впечатляющие результаты в области аудиовизуального синтеза, достигая 73.1% предпочтения в ходе комплексных оценок, проведенных людьми. Этот показатель существенно превосходит результат, полученный с помощью Kling 2.6 Pro, который набрал лишь 20.0%. Такое значительное превосходство указывает на потенциал ID-LoRA в качестве ключевой технологии для создания более реалистичного и привлекательного аудиовизуального контента, открывая новые возможности для автоматизации и улучшения процессов в данной сфере. Высокий процент предпочтения, зафиксированный в ходе оценок, подтверждает эффективность подхода и его способность генерировать материалы, более соответствующие человеческому восприятию и эстетическим предпочтениям.

Представленная работа демонстрирует стремление к элегантности в решении сложной задачи персонализированной аудиовизуальной генерации. Авторы, подобно математикам, стремящимся к доказательству теоремы, фокусируются на сохранении идентичности субъекта в генерируемом контенте. Метод ID-LoRA, объединяя видео и аудио в едином процессе, избегает каскадных подходов, что соответствует принципу минимизации сложности и повышения масштабируемости. Как заметил Винтон Серф: «Интернет — это не просто технология, это способ мышления». Этот подход отражает и в исследовании — устремление к единому, согласованному решению, где каждый элемент — будь то визуальный или акустический — подчинен общей цели сохранения идентичности и ответа на текстовые запросы.
Что Дальше?
Представленный подход, безусловно, демонстрирует элегантность совместного генерирования аудио и видео с сохранением идентичности. Однако, если решение кажется магией — значит, не раскрыт инвариант. Истинная проверка метода заключается не в качественных примерах, а в формальном доказательстве его устойчивости к вариациям входных данных и параметрам генерации. Необходимо более строгое определение метрик сохранения идентичности, выходящих за рамки субъективной оценки, и формализация понятия «акустической идентичности», столь же строгой, как и для визуальной составляющей.
Очевидным направлением развития является исследование возможности обобщения ID-LoRA на более широкий спектр модальностей — от добавления управления позами до генерации видео с учетом не только текста, но и более сложных сценариев взаимодействия. Важно также исследовать пределы применимости LoRA — является ли она действительно оптимальным выбором для тонкой настройки, или существуют более эффективные методы, способные обеспечить лучшую производительность и обобщающую способность.
В конечном счете, вопрос не в том, насколько хорошо система генерирует реалистичные видео, а в том, насколько хорошо она понимает лежащие в основе принципы представления и манипулирования информацией. Истинная элегантность алгоритма проявляется не в его способности имитировать реальность, а в его способности её формально описывать.
Оригинал статьи: https://arxiv.org/pdf/2603.10256.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Трансформация нейросетей: от плотных моделей к разреженным экспертам без обучения
- Эхо чёрных дыр: как квантовая гравитация меняет гравитационные волны
- Сияние фотонов: новый уровень точности в предсказаниях столкновений частиц
- Сверхпроводящая логика: управление магнитным полем
- Волшебство по запросу: ИИ создает заклинания в игре
- Визуальный интеллект для эмбриона: Искусственный интеллект описывает развитие зародыша
- Квантовый скачок через SPAC: Анализ рынка и физика надежды
- Луна раскрывает свои секреты: Искусственный интеллект восстанавливает древнюю формулу
- Нейронные сети: Архитектура как ключ к масштабируемости
- Квантовые сети связи: оптимизация расписания для спутниковой передачи
2026-03-12 23:21