Автор: Денис Аветисян
Новая модель искусственного интеллекта демонстрирует впечатляющую производительность, охватывая множество языков и уделяя особое внимание редким и малоресурсным из них.

Исследование представляет семейство эффективных открытых многоязычных моделей Tiny Aya, обеспечивающих сбалансированное языковое покрытие и сокращающих различия в производительности для языков с ограниченными ресурсами благодаря тщательному отбору данных, дизайну обучения и оценке.
Традиционное масштабирование многоязыковых моделей зачастую требует огромных вычислительных ресурсов, усугубляя неравенство в доступе к технологиям обработки естественного языка. В данной работе, представленной под названием ‘Tiny Aya: Bridging Scale and Multilingual Depth’, описывается семейство компактных, но эффективных многоязыковых моделей, достигающих конкурентоспособных результатов при значительно меньшем количестве параметров. Ключевым достижением является сбалансированная производительность по широкому спектру языков, включая менее обеспеченные ресурсами, благодаря тщательному подбору данных и специализированным техникам обучения. Возможно ли создать действительно инклюзивную систему искусственного интеллекта, способную понимать и генерировать текст на всех языках мира с минимальными затратами?
Равноправие языков: Преодоление дисбаланса в мире искусственного интеллекта
Существующие многоязычные модели зачастую демонстрируют явный перекос в сторону языков с богатыми ресурсами, таких как английский, китайский и испанский. Это приводит к тому, что языки с ограниченными данными, используемые миллионами людей по всему миру, остаются недостаточно представленными и демонстрируют значительно худшие результаты в задачах обработки естественного языка. Например, модели могут отлично справляться с переводом с английского на немецкий, но испытывать серьезные трудности при работе с языками Африки или коренными языками Америки. Данное неравенство не только ограничивает доступ к информации для носителей этих языков, но и препятствует развитию инклюзивных технологий, способных обслуживать все мировое сообщество. Проблема усугубляется тем, что для обучения моделей требуется огромное количество данных, которых просто не существует для многих языков, создавая порочный круг недостаточной представленности и низкого качества работы.
Несбалансированность существующих многоязычных моделей препятствует подлинной глобальной коммуникации и равноправному доступу к информации. Преобладание высокоресурсных языков в обучающих данных приводит к тому, что модели демонстрируют значительно худшие результаты для языков, представленных в меньшей степени. Это создает цифровой разрыв, ограничивая возможности для людей, говорящих на этих языках, в сферах образования, здравоохранения и участия в общественной жизни. Необходимость в моделях, которые уделяют приоритетное внимание справедливому представлению всех языков, продиктована стремлением к инклюзивности и обеспечению равных возможностей для всех пользователей, независимо от их языковой принадлежности. Такой подход позволяет преодолеть существующие барьеры и раскрыть потенциал многоязычного искусственного интеллекта для решения глобальных задач.
Современные подходы к созданию многоязычных моделей сталкиваются со значительными вычислительными сложностями при масштабировании на большое количество языков. Попытки охватить широкий спектр лингвистических систем часто приводят к снижению производительности, поскольку ресурсы распределяются неравномерно. Увеличение числа поддерживаемых языков требует экспоненциального роста параметров модели и объёма обучающих данных, что делает такие модели чрезвычайно затратными и недоступными для многих исследователей и разработчиков. Данное ограничение создает серьезный барьер на пути к созданию действительно инклюзивного искусственного интеллекта, способного обеспечить равный доступ к информации и технологиям для пользователей по всему миру, независимо от их родного языка.
Необходимость в новом поколении языковых моделей обусловлена стремлением к равноправному представлению различных языков и преодолению дисбаланса, характерного для существующих систем. Традиционно, разработка концентрируется на доминирующих языках, оставляя малоресурсные языки за бортом прогресса. Модель TinyAya демонстрирует принципиально иной подход, охватывая 70 языков и акцентируя внимание на сбалансированной производительности для каждого из них. Это позволяет не только расширить доступ к информации для большего числа людей, но и способствует развитию искусственного интеллекта, способного понимать и обрабатывать запросы на самых разных языках, открывая новые горизонты для глобального общения и сотрудничества.

TinyAya: Основа равноправного многоязычного искусственного интеллекта
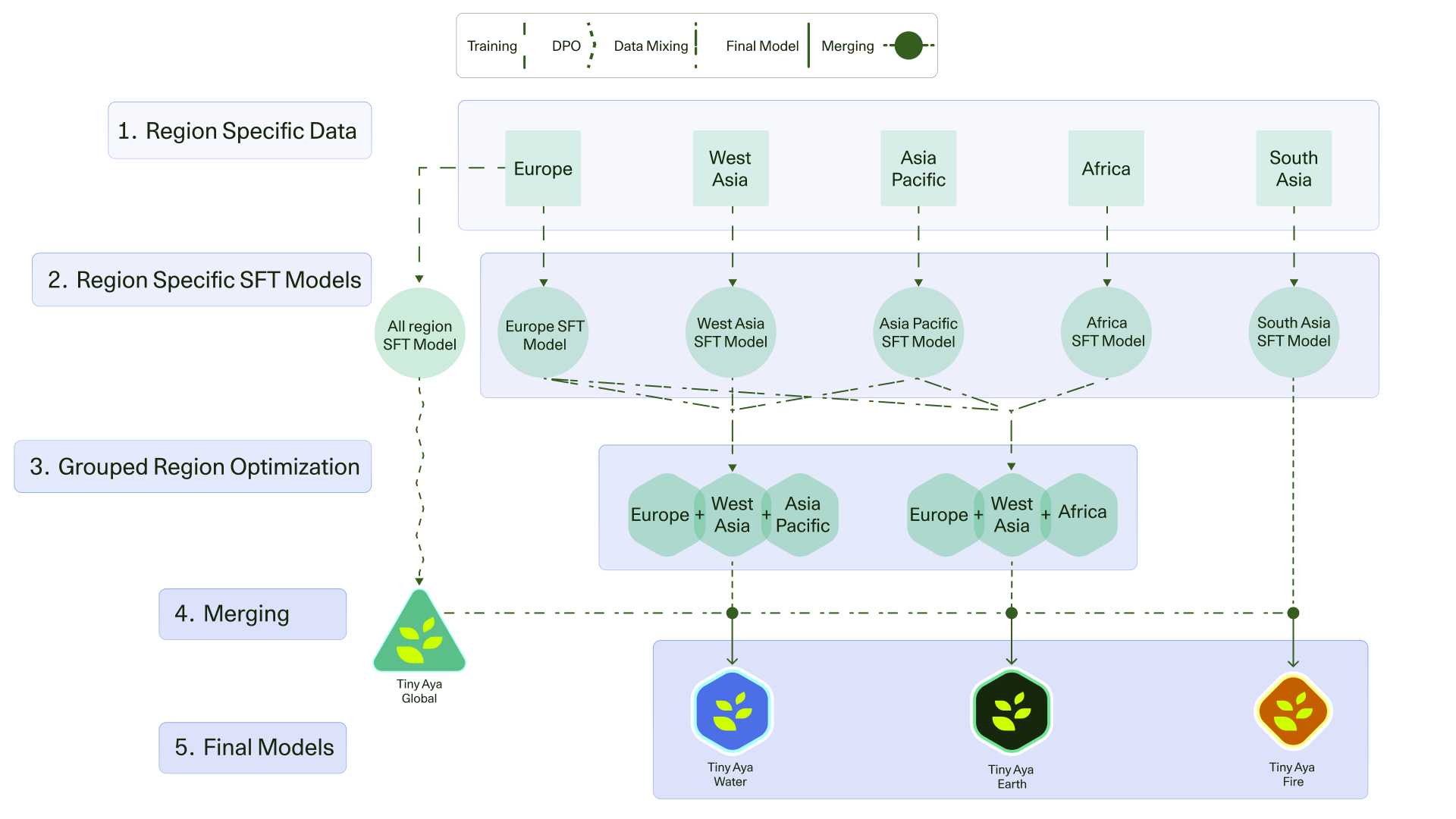
TinyAya представляет собой семейство эффективных многоязычных моделей с открытыми весами, разработанных для обеспечения сбалансированной производительности на широком спектре языков. В отличие от многих существующих моделей, склонных к доминированию высокоресурсных языков, TinyAya стремится к равномерному представлению и качеству обработки как распространенных, так и малоресурсных языков. Это достигается за счет тщательно подобранного набора данных и стратегий обучения, ориентированных на поддержание баланса и предотвращение смещения в сторону языков с большим объемом доступных данных. Модели семейства TinyAya предназначены для использования в различных задачах обработки естественного языка, включая машинный перевод, анализ тональности и ответы на вопросы, обеспечивая доступность и эффективность для широкого круга пользователей и разработчиков.
В основе TinyAya лежит модель TinyAyaBase, предварительно обученная модель с 3,35 миллиардами параметров, охватывающая 70 языков. Данная модель служит надежным фундаментом для дальнейшей разработки и адаптации в различных задачах обработки естественного языка. Предварительное обучение на многоязычном корпусе позволяет TinyAyaBase эффективно переносить знания между языками и демонстрировать сбалансированные показатели производительности, что особенно важно для языков с ограниченными ресурсами. Архитектура модели и процесс обучения были оптимизированы для достижения высокой эффективности и возможности масштабирования.
Эффективная курация данных и стратегическое смешивание (DataMixture) являются критически важными для обеспечения сбалансированного обучения TinyAya. Для предотвращения доминирования высокоресурсных языков, которые обычно представлены в больших объемах в общедоступных корпусах, применяются методы тщательного отбора и взвешивания данных. Это включает в себя ручную проверку и фильтрацию данных, а также разработку стратегий семплирования, обеспечивающих пропорциональное представление языков с различным количеством доступных ресурсов. Особое внимание уделяется минимизации смещения в данных, что достигается путем удаления дубликатов, исправления ошибок и нормализации текстов. Стратегическое смешивание данных позволяет создать обучающий набор, в котором каждый язык имеет достаточную представленность для эффективного обучения модели, независимо от общего объема доступных данных для этого языка.
Для повышения производительности модели TinyAya, особенно в отношении языков с ограниченными ресурсами, применяется генерация синтетических данных. Этот процесс включает в себя создание искусственных обучающих примеров, дополняющих существующие наборы данных. Синтетические данные генерируются с использованием различных методов, включая обратный перевод и методы, основанные на правилах, что позволяет увеличить объем обучающей информации для языков, где доступность данных ограничена. Использование сгенерированных данных позволяет улучшить обобщающую способность модели и повысить точность ее работы для широкого спектра языков, компенсируя дисбаланс в объеме доступных данных.
Уточнение производительности: Постобучение и инструктивное обучение
После предварительного обучения модель подвергается процессу постобучения, который заключается в её дообучении на конкретных задачах. Этот этап позволяет значительно повысить производительность и адаптируемость модели к различным сценариям использования. Постобучение включает в себя настройку параметров модели на специализированных наборах данных, что позволяет ей более эффективно решать поставленные задачи и достигать лучших результатов в целевых областях. В процессе постобучения происходит оптимизация весов модели для конкретных типов входных данных и выходных форматов, что существенно улучшает её общую производительность и точность.
Обучение с подкреплением на основе инструкций является ключевым этапом оптимизации языковой модели, направленным на повышение ее способности точно интерпретировать и выполнять пользовательские запросы. Этот процесс включает в себя тонкую настройку модели на наборе данных, состоящем из инструкций и соответствующих ожидаемых ответов, что позволяет ей более эффективно сопоставлять входные данные с желаемым результатом. В результате модель становится более универсальной и удобной в использовании, так как способна адаптироваться к различным типам задач и форматам инструкций, обеспечивая предсказуемое и релевантное поведение.
Модель TinyAyaGlobal демонстрирует стабильную многоязычную производительность на широком спектре языков, превосходя показатели многих сопоставимых моделей. Результаты тестирования показывают, что модель обеспечивает высокую точность и согласованность при обработке различных лингвистических данных, включая языки с ограниченными ресурсами. Превосходство TinyAyaGlobal подтверждено сравнительными анализами с другими моделями аналогичного размера и архитектуры, в ходе которых были оценены такие параметры, как BLEU score, perplexity и точность перевода. Это делает TinyAyaGlobal эффективным решением для задач, требующих многоязыковой обработки, таких как машинный перевод, анализ тональности и ответы на вопросы.
Модель TinyAyaGlobal использует специализированный метод токенизации, разработанный для обеспечения равноправного представления всех языков при обработке текста. В отличие от стандартных токенизаторов, которые могут отдавать предпочтение языкам с большим объемом обучающих данных, данный метод стремится к сбалансированному представлению каждого языка в процессе разбиения текста на токены. Это достигается за счет применения алгоритмов, учитывающих лингвистические особенности различных языков и предотвращающих доминирование одного языка над другими. Такой подход позволяет модели эффективно обрабатывать и генерировать текст на различных языках, избегая предвзятости и обеспечивая более справедливую и точную обработку данных.

Строгая оценка: Бенчмарки многоязычного совершенства
Разработанная оценочная платформа представляет собой всесторонний набор критериев для анализа эффективности модели в различных языковых средах и при решении разнообразных задач. Этот комплексный подход включает в себя не только традиционные тесты на качество перевода, такие как Flores и WMT24++, но и оценку способностей к математическому мышлению с помощью GlobalMGSM. Важно отметить, что платформа охватывает и аспекты безопасности, используя MultilingualSafetyEvaluation и MultiJail для обеспечения ответственной разработки искусственного интеллекта. Такое многогранное тестирование позволяет получить объективную картину возможностей модели и ее способности адаптироваться к сложным лингвистическим вызовам, что является ключевым фактором для создания надежных и универсальных систем искусственного интеллекта.
Для всесторонней оценки возможностей модели используются специализированные бенчмарки, позволяющие проверить её навыки в различных областях. В частности, качество машинного перевода измеряется при помощи тестов `Flores` и `WMT24++`, которые анализируют точность и естественность переведённого текста на разных языках. Параллельно, способность к математическому мышлению оценивается с помощью `GlobalMGSM` — комплекса задач, требующих решения математических примеров и логических головоломок. Использование этих и других тестов позволяет получить объективную картину сильных и слабых сторон модели, а также сравнить её производительность с другими передовыми системами искусственного интеллекта.
Особое внимание уделяется безопасности разрабатываемой модели, что подтверждается использованием специализированных бенчмарков, таких как MultilingualSafetyEvaluation и MultiJail. Эти инструменты позволяют всесторонне оценить способность модели генерировать безопасные и этически приемлемые ответы на различных языках, предотвращая создание потенциально вредоносного или оскорбительного контента. Проверка на устойчивость к «jailbreak»-запросам, осуществляемая с помощью MultiJail, играет ключевую роль в обеспечении ответственной разработки искусственного интеллекта и минимизации рисков, связанных с неправомерным использованием технологий. Такой подход гарантирует, что модель не только демонстрирует высокие показатели производительности, но и соответствует самым строгим стандартам безопасности и этики.
Комплексная оценка по ряду бенчмарков последовательно демонстрирует выдающиеся результаты TinyAya и её способность к обобщению в различных языковых средах и задачах. Модель достигла 91.1% показателя безопасных ответов в тесте MultiJail, что является наивысшим результатом среди всех протестированных моделей. Особенно впечатляющие результаты были показаны в математическом рассуждении, где TinyAya продемонстрировала точность в 39.2% при решении задач на африканских языках, значительно превзойдя такие модели, как Gemma3-4B (17.6%) и Qwen3-4B (6.25%). Данные результаты подтверждают высокую эффективность и универсальность TinyAya в обработке и понимании информации на разных языках и в различных контекстах.

Исследование, представленное в данной работе, стремится к созданию не просто эффективной, но и справедливой модели обработки языка. Подобно тому, как скульптор удаляет лишнее, чтобы выявить суть, авторы Tiny Aya тщательно отбирают данные и оптимизируют процесс обучения, чтобы добиться сбалансированного представления различных языков. Как заметил Андрей Колмогоров: «Математика — это искусство видеть невидимое». В данном случае, “невидимое” — это потенциал языков с ограниченными ресурсами, который раскрывается благодаря продуманному подходу к построению модели и уменьшению дисбаланса в данных. В результате, Tiny Aya демонстрирует, что истинное совершенство достигается не за счет добавления сложности, а благодаря утонченной простоте и ясности в реализации основной идеи — обеспечении равного доступа к возможностям искусственного интеллекта для всех языков.
Куда же дальше?
Представленная работа, хоть и демонстрирует определенный прогресс в области многоязычных моделей, лишь приоткрывает завесу над истинной сложностью задачи. Упор на сбалансированное представление языков — шаг верный, но иллюзия полного равенства в цифровом пространстве таит в себе опасность упрощения. Недостаточно просто смешать данные; необходимо понимать, что сам язык — это не статичная сущность, а живой организм, меняющийся под влиянием культуры и контекста.
Будущие исследования должны быть направлены не на увеличение масштаба моделей, а на их углубленное понимание мира. Важно отбросить излишнюю детализацию и сосредоточиться на фундаментальных принципах, лежащих в основе языковой коммуникации. Эффективность — это не количество параметров, а способность к обобщению и адаптации.
Истинным прорывом станет не создание «универсального» языка, а разработка инструментов, позволяющих каждому языку сохранить свою уникальность и самобытность в эпоху цифровизации. Совершенство заключается не в том, чтобы воссоздать интеллект, а в том, чтобы позволить интеллекту проявиться во всей его многогранности.
Оригинал статьи: https://arxiv.org/pdf/2603.11510.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Эхо чёрных дыр: как квантовая гравитация меняет гравитационные волны
- Сияние фотонов: новый уровень точности в предсказаниях столкновений частиц
- Сверхпроводящая логика: управление магнитным полем
- Трансформация нейросетей: от плотных моделей к разреженным экспертам без обучения
- Квантовый скачок в многомасштабном моделировании
- Батарея под контролем: Искусственный интеллект на страже долговечности
- Искусственный интеллект и кодер: меняется ли подход к разработке?
- Джозефсоновские переходы на квантовых материалах: новые горизонты сверхпроводимости
- Искусственный интеллект проектирует белки: новый горизонт биоинженерии
- Квантовый взрыв: Разговор о голосах и перспективах
2026-03-13 12:56