Автор: Денис Аветисян
Разработка системы, предсказывающей время выполнения задач глубокого обучения в распределенных системах, для повышения эффективности и масштабируемости.
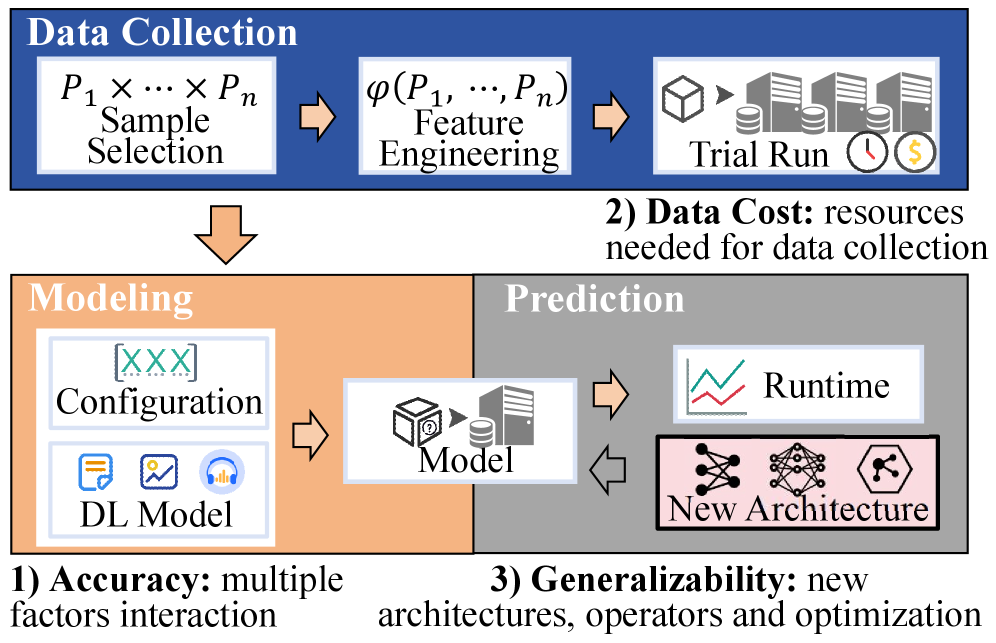
В статье представлена ScaleDL – инновационная платформа, использующая графовые нейронные сети и методы интеллектуальной выборки для точного прогнозирования времени выполнения распределенных задач глубокого обучения.
В условиях экспоненциального роста сложности моделей глубокого обучения, точное предсказание времени выполнения распределенных вычислений становится критически важной, но сложной задачей. В данной работе, ‘ScaleDL: Towards Scalable and Efficient Runtime Prediction for Distributed Deep Learning Workloads’, предлагается новый фреймворк ScaleDL, сочетающий нелинейное послойное моделирование с механизмом межслойного взаимодействия на основе графовых нейронных сетей и оптимизацией сбора данных методом D-optimal. Предложенный подход демонстрирует значительное повышение точности и обобщающей способности предсказания времени выполнения, превосходя существующие методы в несколько раз. Способен ли ScaleDL стать основой для автоматической оптимизации распределенных вычислений и эффективного использования ресурсов в эпоху масштабных моделей ИИ?
Неуловимое Время Вычислений: Проблема Прогнозирования DNN
Глубокие нейронные сети (DNN) лежат в основе современного искусственного интеллекта, однако их непредсказуемость в производительности создает серьезные трудности для оптимизации систем. Неточное предсказание времени выполнения DNN затрудняет эффективное распределение ресурсов, особенно в динамичных облачных средах. Традиционные методы, основанные на подсчете операций с плавающей точкой (FLOPs), оказываются недостаточными. Это несоответствие приводит к узким местам, ограничивая масштабируемость и эффективность систем. В результате, стабильная работа DNN в реальных условиях становится сложной задачей. Неспособность точно предсказать время выполнения приводит к неэффективному использованию ресурсов и увеличению задержек, что требует новых подходов к моделированию и прогнозированию поведения DNN.
Поиск новых подходов к моделированию и прогнозированию поведения DNN становится критически важной задачей для развития искусственного интеллекта.
ScaleDL: Послойный Анализ Времени Вычислений
ScaleDL использует стратегию послойного моделирования, разлагая DNN на отдельные слои для снижения требований к объему данных и повышения точности прогнозирования. В сочетании с D-оптимальной выборкой, ScaleDL обеспечивает сбор информативных выборок для обучения модели, максимизируя информацию и улучшая обобщающую способность. ScaleDL превосходит традиционные методы, такие как MLP-ACC, Random Forest и BiRNN, в задачах прогнозирования и анализа DNN, подтверждая повышенную эффективность и точность.
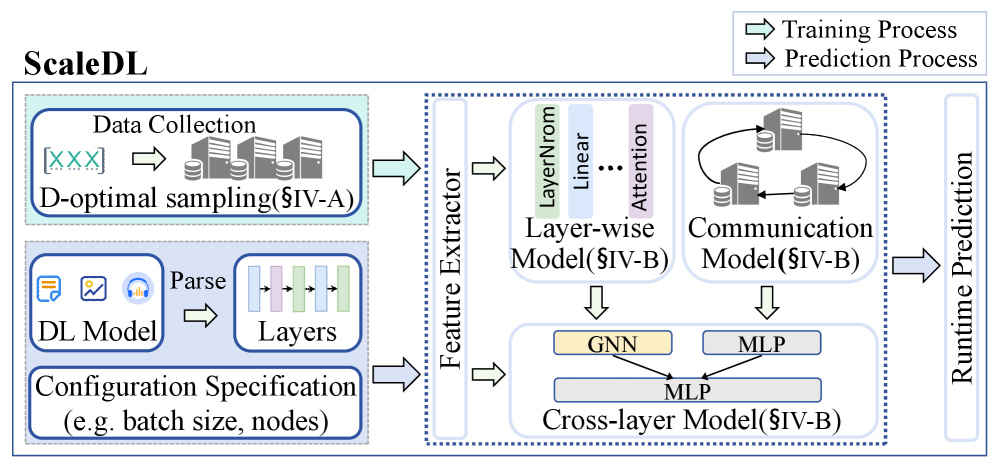
Благодаря фокусировке на поведении каждого слоя, ScaleDL демонстрирует превосходство над традиционными методами.
Зависимости Между Слоями: Графовые Нейронные Сети в Анализе DNN
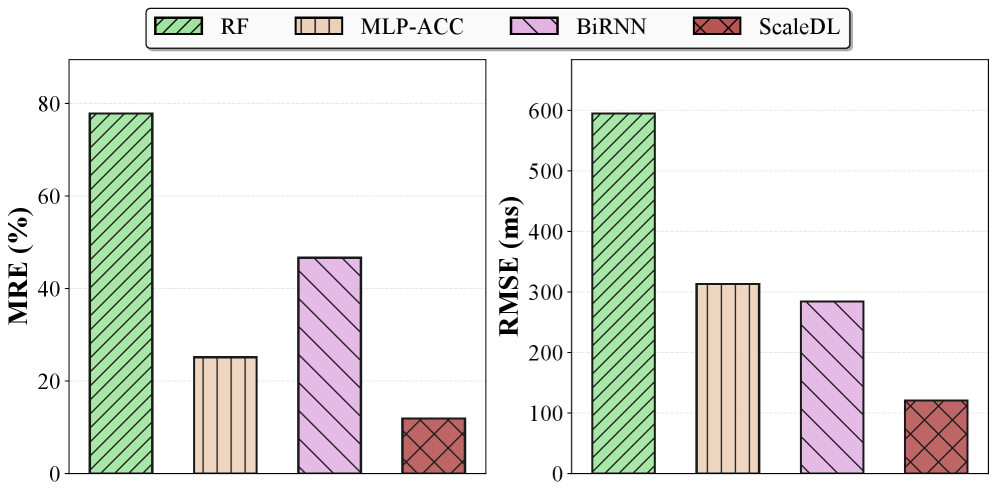
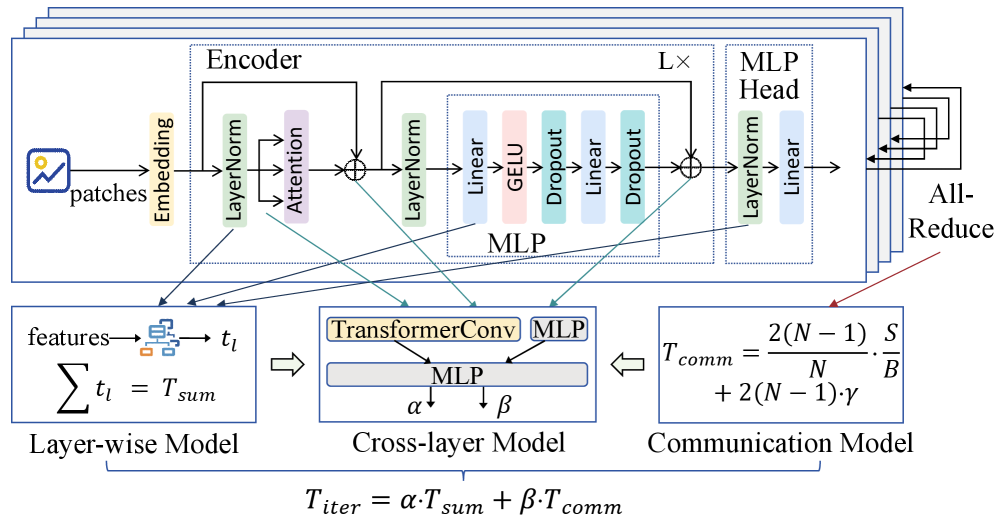
В рамках исследования предложена методология ScaleDL, использующая графовые нейронные сети (GNN) и моделирование взаимодействия между слоями для анализа зависимостей в DNN, таких как перекрытие вычислений и повторное использование памяти. Данный подход позволяет более точно моделировать поток информации, учитывая накладные расходы и влияние операций All-Reduce. Эмпирические результаты демонстрируют, что ScaleDL обеспечивает шестикратное снижение средней относительной ошибки (MRE) и пятикратное снижение среднеквадратичной ошибки (RMSE). В частности, MRE составляет 9.39%, а RMSE – 43.66 мс, что свидетельствует о значительном улучшении точности прогнозирования.
Эти результаты демонстрируют значительное улучшение точности прогнозирования времени выполнения DNN.
Динамическое Масштабирование: Влияние ScaleDL на Производительность и Эффективность
ScaleDL обеспечивает точные предсказания времени выполнения, что позволяет реализовать динамическое масштабирование облачной инфраструктуры и адаптировать ресурсы к потребностям рабочей нагрузки. Это приводит к улучшению использования ресурсов и снижению затрат, особенно при обслуживании больших нейронных сетей. ScaleDL поддерживает совместную оптимизацию модели и аппаратной платформы (Model-Device Co-optimization), настраивая производительность модели для целевого оборудования. Вне домена тестовых данных, ScaleDL демонстрирует MRE 11.88% и RMSE 120.5 мс, что на 6 и 5 порядков меньше, чем у базовой модели Random Forest (RF), которая показывает MRE 77.81% и RMSE 594.7 мс. Каждая система, как и любое живое существо, неминуемо приближается к своему завершению, но истинная ценность заключается в том, как достойно она справляется с этим течением времени.
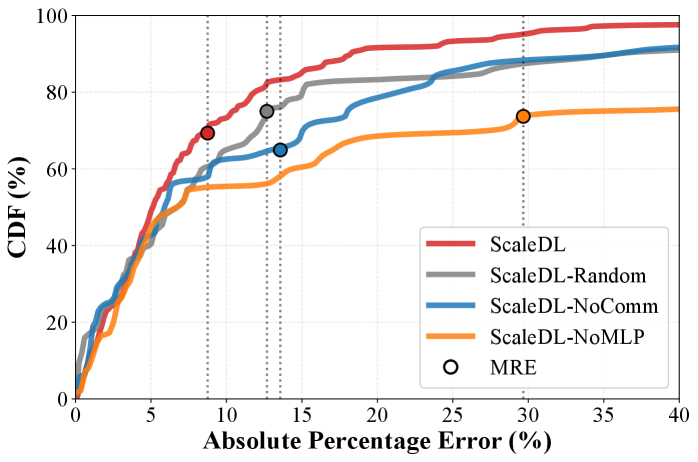
Вне домена тестовых данных, ScaleDL демонстрирует значительное превосходство над базовыми моделями.
Исследование, представленное в данной работе, фокусируется на предсказании времени выполнения распределенных задач глубокого обучения, что представляет собой сложную проблему, требующую учета множества взаимосвязанных факторов. В этом контексте, слова Джона Маккарти, одного из пионеров искусственного интеллекта, приобретают особое значение: «Всякая глупость заключается в том, что человек делает что-то ненужное». ScaleDL, предлагаемый в статье, стремится к оптимизации процесса предсказания, устраняя излишние вычислительные затраты и повышая эффективность. Особое внимание уделяется масштабируемости и точности предсказаний, что напрямую связано с концепцией D-optimal sampling, позволяющей сократить количество необходимых выборок без потери качества. Таким образом, представленный подход демонстрирует стремление к разумному и эффективному использованию ресурсов, избегая ненужных сложностей и затрат.
Что впереди?
Представленная работа, стремясь предсказать время выполнения распределенных вычислений глубокого обучения, лишь запечатлела мимолетную тень более фундаментальной проблемы. Версионирование моделей, как форма памяти, неизбежно приводит к накоплению артефактов – устаревших оптимизаций, специфичных для аппаратных конфигураций, которые уже канули в лету. Стрела времени всегда указывает на необходимость рефакторинга, и даже самые точные предсказания становятся не более чем историческими зарисовками, когда ландшафт вычислительных ресурсов претерпевает изменения.
Ограничения существующих подходов в обработке коммуникационных издержек, несомненно, останутся актуальными. Графовые нейронные сети, хотя и продемонстрировали свою эффективность, пока не способны полностью учесть динамику сетевых взаимодействий и непредсказуемость задержек. Будущие исследования, вероятно, сосредоточатся на разработке адаптивных моделей, способных к самообучению и коррекции в реальном времени, подобно тому, как живые системы приспосабливаются к меняющимся условиям среды.
В конечном счете, погоня за идеально точным предсказанием времени выполнения представляется несколько тщетной. Все системы стареют – вопрос лишь в том, делают ли они это достойно. Возможно, более продуктивным направлением исследований станет разработка систем, которые не столько предсказывают будущее, сколько эффективно реагируют на его неопределенность, обеспечивая устойчивость и отказоустойчивость в условиях постоянных изменений.
Оригинал статьи: https://arxiv.org/pdf/2511.04162.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Эхо чёрных дыр: как квантовая гравитация меняет гравитационные волны
- Сияние фотонов: новый уровень точности в предсказаниях столкновений частиц
- Сверхпроводящая логика: управление магнитным полем
- Трансформация нейросетей: от плотных моделей к разреженным экспертам без обучения
- Биосети в руках ИИ: Автоматизация системной фармакологии
- Квантовые сети связи: оптимизация расписания для спутниковой передачи
- Квантовый горизонт: взгляд изнутри
- Глубокий поиск: новый взгляд на мультимодальные исследования
- Квантовый поиск гравитационных волн: новый алгоритм для повышения точности
- Квантовые вычисления: Честность и Прогресс
2025-11-08 11:40