Автор: Денис Аветисян
Новая платформа делает интерпретацию сложных нейросетей более доступной благодаря интерактивным визуализациям и объяснениям на естественном языке.
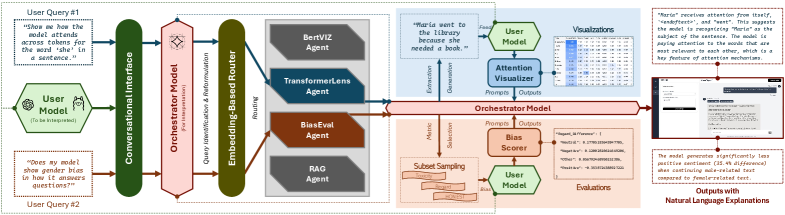
В статье представлена система KnowThyself, многоагентный инструмент, объединяющий различные методы интерпретируемости для упрощения анализа больших языковых моделей и выявления потенциальных смещений.
Несмотря на растущую мощь больших языковых моделей (LLM), их интерпретируемость остается сложной задачей, требующей значительных технических навыков. В данной работе представлена система ‘KnowThyself: An Agentic Assistant for LLM Interpretability’, объединяющая разрозненные инструменты анализа LLM в удобный чат-интерфейс. Ключевой особенностью является архитектура, основанная на многоагентной системе, обеспечивающей интерактивные визуализации и понятные объяснения поведения моделей. Сможет ли подобный подход значительно упростить процесс инспекции LLM и открыть новые возможности для оценки предвзятости и понимания механизмов внимания?
Непрозрачность Больших Языковых Моделей: Вызов для Интерпретируемости
Большие языковые модели (LLM), такие как Gemma3-27B и LLaMA2-13B, демонстрируют впечатляющие результаты в задачах обработки естественного языка. Однако, их внутренние механизмы остаются непрозрачными, затрудняя построение доверия и контроль над предсказаниями. Недостаток интерпретируемости представляет серьезную проблему, особенно в критически важных приложениях, где необходимо понимать почему модель пришла к определенному выводу. Существующие методы фрагментированы и лишены единой теоретической базы. Необходим целостный подход к интерпретации LLM, выходящий за рамки простого определения влияния признаков, стремясь к глубокому, механистическому пониманию обработки информации и формирования выводов. Что останется устойчивым в бесконечности параметров, что определит суть интеллекта, рожденного кодом?
KnowThyself: Многоагентская Платформа для Интерпретируемости
KnowThyself использует модульную архитектуру, инкапсулирующую методы интерпретируемости в независимые агенты, обеспечивая масштабируемость и расширяемость системы. В основе лежит LangGraph, моделирующий систему как ориентированный граф агентов, организуя согласованные задачи интерпретации, где каждый агент выполняет свою роль. Взаимодействие между агентами осуществляется через четко определенные каналы, обеспечивая когерентность. Multi-Agent Orchestration Framework гарантирует получение связных объяснений и унифицированных выводов, объединяя результаты работы агентов. Ollama предоставляет платформу для хостинга моделей встраивания и оркестровки, упрощая развертывание и управление.
Проникновение в Поведение LLM: Специализированные Агенты
KnowThyself использует агентов, таких как BertViz и TransformerLens, для визуализации паттернов внимания и внутренних активаций, предоставляя детальное понимание процесса рассуждений модели. RAG Explainer использует FAISS для эффективного поиска сходства, обосновывая ответы LLM на основе литературы и повышая фактическую точность, предоставляя подтверждение для каждого утверждения. Agent Router использует nomic-embed-text для интеллектуальной маршрутизации запросов к наиболее релевантному агенту, максимизируя эффективность. Оркестратор LLM, работающий на базе Gemma3-27B, управляет взаимодействием с пользователем, перефразирует запросы и синтезирует объяснения, обеспечивая когерентный и понятный ответ на сложные вопросы.
Оценка Безопасности и Справедливости в LLM: Обнаружение Скрытых Смещений
KnowThyself включает агента BiasEval для оценки выходных данных LLM на предмет токсичности, предвзятости и демографических дисбалансов, выявляя потенциальные источники несправедливости. BiasEval использует Toxicity Prompts, систему оценки HONEST и набор данных BOLD для всесторонней оценки справедливости. Выявление и смягчение предвзятостей способствует разработке более ответственных и справедливых систем искусственного интеллекта. Интерактивный интерфейс визуализации представляет результаты оценки с пояснениями на естественном языке, снижая порог входа для анализа моделей и повышая уровень доверия. В хаосе данных спасает только математическая дисциплина.
Представленная работа демонстрирует стремление к созданию системы, способной не просто функционировать, но и раскрывать внутренние механизмы принятия решений. Подобный подход к интерпретируемости больших языковых моделей требует математической строгости и доказательности. Клод Шеннон однажды сказал: “Информация – это не просто данные, а мера уменьшения неопределенности.” Эта фраза находит отражение в KnowThyself, где платформа стремится уменьшить неопределенность в работе LLM, предоставляя пользователю инструменты для анализа и понимания процессов, лежащих в основе генерации ответов. Особое внимание к визуализации и объяснению на естественном языке позволяет не просто наблюдать за работой модели, но и формировать доказательную базу для оценки ее корректности и выявления потенциальных смещений, что соответствует принципам математической чистоты и доказательности.
Что впереди?
Представленная работа, несмотря на кажущуюся практическую направленность, лишь подчеркивает глубинную проблему. Автоматизация интерпретации больших языковых моделей – это, по сути, попытка формализовать неформальное. Инструменты, интегрированные в платформу KnowThyself, предоставляют количественные оценки, но истинное понимание, как известно, не сводится к числам. Необходимо признать, что любой алгоритм интерпретации, каким бы элегантным он ни был, является лишь приближением к истине, и неизбежно содержит в себе субъективные предположения.
В дальнейшем, усилия следует направить не столько на увеличение количества метрик, сколько на разработку формальных моделей, позволяющих доказывать свойства моделей, а не просто наблюдать их поведение. Особый интерес представляет возможность создания систем, способных выявлять не только предвзятость, но и принципиальную недетерминированность в процессе принятия решений языковой моделью. Очевидно, что задача не в создании «объяснимого ИИ«, а в построении ИИ, чье поведение можно предсказать и верифицировать.
В конечном итоге, ценность подобных платформ, как KnowThyself, заключается не в автоматизации интерпретации, а в том, что они заставляют исследователей задавать правильные вопросы. Пока же, остается констатировать, что красота алгоритма не зависит от языка реализации, важна только непротиворечивость. А ее, как показывает практика, достичь крайне сложно.
Оригинал статьи: https://arxiv.org/pdf/2511.03878.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Сияние фотонов: новый уровень точности в предсказаниях столкновений частиц
- Эхо чёрных дыр: как квантовая гравитация меняет гравитационные волны
- Сверхпроводящая логика: управление магнитным полем
- Квантовые смеси: от капель жидкости до сверхтекучих кристаллов
- Квантовый взрыв: Разговор о голосах и перспективах
- Визуальный интеллект для эмбриона: Искусственный интеллект описывает развитие зародыша
- Квантовый скачок через SPAC: Анализ рынка и физика надежды
- Волшебство по запросу: ИИ создает заклинания в игре
- Нейронные сети: Архитектура как ключ к масштабируемости
- Луна раскрывает свои секреты: Искусственный интеллект восстанавливает древнюю формулу
2025-11-08 20:08