Автор: Денис Аветисян
Единая платформа для упрощения разработки и масштабирования моделей компьютерного зрения.
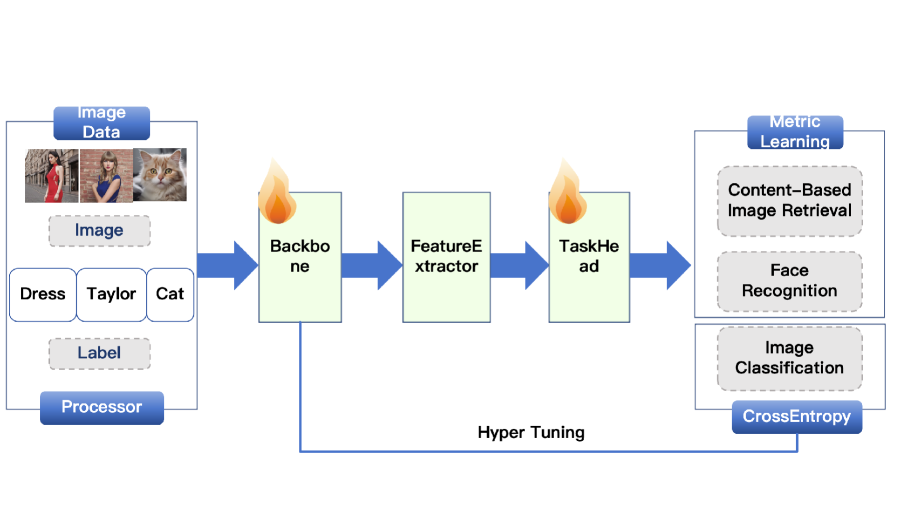
DORAEMON – это PyTorch-фреймворк, предназначенный для унификации и ускорения исследований в области моделирования и обучения представлений визуальных объектов, с поддержкой широкого спектра моделей и инструментов для интерпретации и развертывания.
Несмотря на значительный прогресс в области компьютерного зрения, унификация подходов к моделированию визуальных объектов и обучению представлений остается сложной задачей. В данной работе представлена библиотека ‘DORAEMON: A Unified Library for Visual Object Modeling and Representation Learning at Scale’, разработанная на основе PyTorch, и объединяющая в себе инструменты для классификации, поиска и метрического обучения. DORAEMON предоставляет доступ к более чем 1000 предварительно обученным моделям, модульные функции потерь и аугментации данных, а также возможности распределенного обучения, упрощая процесс экспериментирования и развертывания. Сможет ли эта платформа стать стандартом для ускорения исследований и внедрения передовых технологий в области визуального распознавания?
Архитектуры как Основа Визуального Восприятия
Современные системы компьютерного зрения опираются на надёжные архитектуры для извлечения признаков и решения разнообразных задач. Эти архитектуры обеспечивают первичную обработку визуальной информации, необходимую для последующего анализа. Первые подходы, такие как ResNet, столкнулись с ограничениями в захвате долгосрочных зависимостей. Архитектуры на основе трансформеров, такие как Vision Transformer и Swin Transformer, предложили улучшения, но требуют значительных вычислительных ресурсов. Границы видимого отражают не только пределы сенсоров, но и невидимые связи, формирующие истинное восприятие.
DORAEMON: Унифицированная Платформа для Визуального Моделирования
DORAEMON – библиотека на базе PyTorch, упрощающая и ускоряющая моделирование визуальных объектов в больших масштабах. Она охватывает задачи классификации изображений, распознавания лиц и поиска изображений по содержанию. Библиотека интегрируется с timm, предоставляя доступ к более чем 1000 предварительно обученных моделей в стиле ImageNet. Для повышения обобщающей способности DORAEMON расширяет базовые архитектуры, внедряя динамические методы увеличения данных, такие как MixUp и CutOut, создавая более надёжные и эффективные модели.
Повышение Производительности и Интерпретируемости с DORAEMON
DORAEMON поддерживает передовые алгоритмы оптимизации, такие как Sharpness-Aware Minimization (SAM), создавая модели, менее чувствительные к незначительным изменениям входных данных. Для распознавания лиц библиотека интегрирует функции углового поля потерь, включая ArcFace и CircleLoss, улучшая дискриминационные способности модели. Также библиотека предоставляет инструменты для интерпретации моделей, такие как Grad-CAM, визуализируя области изображения, оказывающие наибольшее влияние на предсказания.
Расширение Горизонтов: Интеграция с Большими Языковыми Моделями
DORAEMON разработан с учетом расширяемости, что позволяет интегрировать его с большими языковыми моделями (LLM) для открытия новых возможностей в визуальном рассуждении и описании. Комбинирование визуальных признаков и семантического понимания LLM позволяет моделям достигать более глубокого понимания сцен и повышать точность распознавания объектов. Поиск изображений по содержанию выигрывает от этой синергии, поскольку модели способны извлекать изображения на основе сложных текстовых запросов и семантической схожести, используя функции потерь, такие как Triplet Loss и Contrastive Loss. Каждое отклонение от ожидаемого результата в визуальном анализе – это возможность раскрыть скрытые закономерности и углубить понимание системы.
Исследование, представленное в данной работе, демонстрирует стремление к созданию универсальной системы для моделирования визуальных объектов. Как однажды заметила Фэй-Фэй Ли: «Искусственный интеллект должен быть ориентирован на человека». Эта фраза находит отражение в стремлении DORAEMON упростить процесс разработки и исследования в области визуального обучения, делая его более доступным и эффективным. Система, объединяя различные модели и техники обучения, позволяет исследователям сосредоточиться на изучении закономерностей в данных, а не на технических деталях реализации. Особенно важно, что DORAEMON предоставляет инструменты для интерпретируемости, что необходимо для понимания принципов работы моделей и обеспечения их надежности. Данный подход способствует развитию более интуитивно понятных и управляемых систем искусственного интеллекта.
Что впереди?
Представленная библиотека DORAEMON, подобно сложному микроскопу, позволяет рассмотреть мир визуальных объектов в новом масштабе. Однако, увеличение разрешения не всегда означает полное понимание. Несмотря на широкие возможности в области моделирования и обучения представлений, фундаментальный вопрос о том, как наилучшим образом связать визуальную информацию с семантическим пониманием, остается открытым. Дальнейшие исследования должны быть направлены на преодоление разрыва между поверхностными признаками и глубинным смыслом, особенно в контексте мультимодальных больших языковых моделей.
Очевидным направлением развития является исследование методов, позволяющих не просто классифицировать объекты, но и понимать их взаимосвязи и контекст. Эффективное использование данных, подобно тщательному выбору образцов для исследования, требует разработки новых стратегий аугментации и передачи обучения. Особое внимание следует уделить интерпретируемости моделей, чтобы понимать, какие именно признаки влияют на принятие решений, и, следовательно, повышать доверие к системам искусственного зрения.
В конечном итоге, прогресс в области визуального моделирования зависит не только от совершенствования алгоритмов, но и от способности задавать правильные вопросы. Подобно любому инструменту, библиотека DORAEMON лишь усиливает возможности исследователя, но не заменяет его критическое мышление и творческий подход. Истинное понимание системы приходит через постоянное исследование её закономерностей, а визуальные данные лишь открывают двери к новым гипотезам.
Оригинал статьи: https://arxiv.org/pdf/2511.04394.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Эхо чёрных дыр: как квантовая гравитация меняет гравитационные волны
- Сияние фотонов: новый уровень точности в предсказаниях столкновений частиц
- Сверхпроводящая логика: управление магнитным полем
- Визуальный интеллект для эмбриона: Искусственный интеллект описывает развитие зародыша
- Квантовый скачок через SPAC: Анализ рынка и физика надежды
- Волшебство по запросу: ИИ создает заклинания в игре
- Нейронные сети: Архитектура как ключ к масштабируемости
- Луна раскрывает свои секреты: Искусственный интеллект восстанавливает древнюю формулу
- Квантовые сети связи: оптимизация расписания для спутниковой передачи
- Квантовый горизонт: взгляд изнутри
2025-11-09 17:29