Автор: Денис Аветисян
Исследователи предлагают метод динамической подстройки генеративных моделей распознавания речи к изменяющимся акустическим условиям без переобучения.
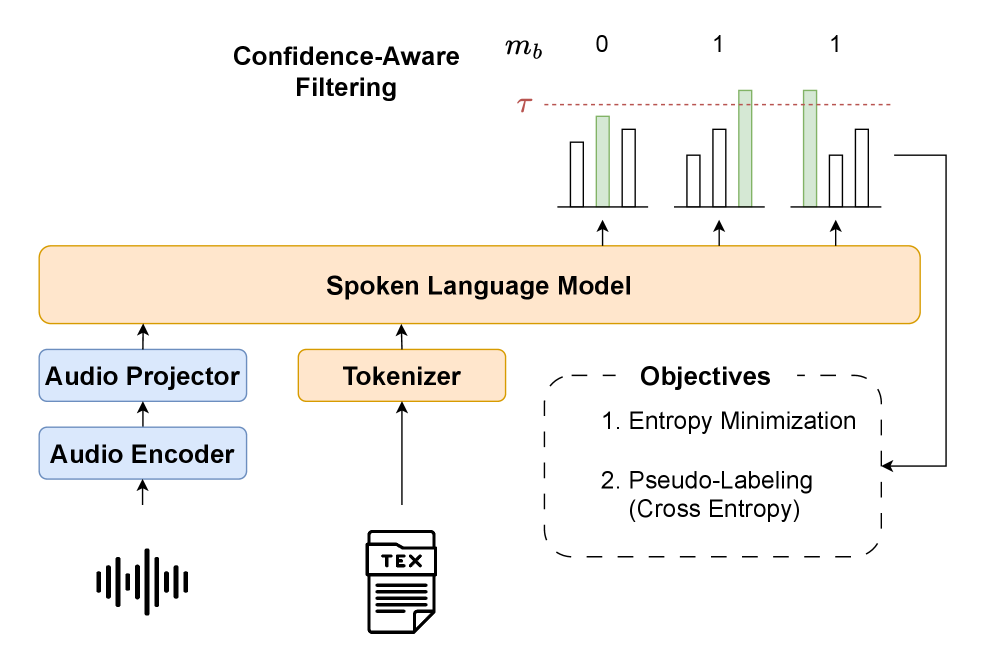
Предложенная схема SLM-TTA использует минимизацию энтропии или псевдоразметку с фильтрацией по уверенности для адаптации лишь небольшой части параметров модели.
Современные модели обработки речи, несмотря на успехи, демонстрируют снижение производительности в условиях реального акустического окружения. В данной работе, ‘SLM-TTA: A Framework for Test-Time Adaptation of Generative Spoken Language Models’, предложен новый подход к адаптации генеративных моделей речи во время работы, позволяющий повысить их устойчивость к шумам и изменениям в характеристиках звука. Разработанный фреймворк SLM-TTA динамически корректирует лишь небольшую часть параметров модели, используя данные текущего входного сигнала, что обеспечивает эффективную и экономичную адаптацию. Сможет ли предложенный метод стать основой для создания более надежных и универсальных систем распознавания и понимания речи в различных условиях?
Распознавание речи в реальном мире: вызов системе
В настоящее время системы распознавания речи, известные как модели распознавания речи (SLM), становятся всё более распространёнными в различных приложениях — от голосовых помощников до систем автоматической транскрипции. Однако, их точность существенно снижается при работе в реальных условиях, отличающихся от лабораторных. Проблемой являются акустические вариации: фоновый шум, эхо, различные акценты и тембры речи, а также качество записи. Эти факторы приводят к значительным ошибкам в распознавании, что ограничивает практическое применение SLM в шумных помещениях, на улице или в других неидеальных акустических средах. Разработка алгоритмов, устойчивых к подобным помехам, представляет собой ключевую задачу в области обработки речи и искусственного интеллекта.
Традиционные методы адаптации моделей распознавания речи, такие как оффлайн-адаптация, требуют наличия размеченных данных для каждой новой акустической среды, что создает серьезные препятствия для масштабируемости. Этот процесс предполагает сбор и аннотацию большого объема аудиоданных, отражающих конкретные характеристики шума, реверберации и акцентов, характерных для каждого нового окружения. Подобная потребность в размеченных данных не только требует значительных временных и финансовых затрат, но и ограничивает возможность быстрого развертывания моделей в новых, ранее не встречавшихся условиях. В результате, широкое внедрение систем распознавания речи в динамично меняющихся средах, таких как общественный транспорт, уличные пространства или различные производственные объекты, становится затруднительным из-за необходимости постоянного сбора и обработки размеченных данных для каждой новой локации.
Акустические изменения, включающие в себя шум и реверберацию, представляют собой фундаментальную проблему для надежного использования моделей распознавания речи в различных условиях. Эти факторы искажают звуковой сигнал, приводя к снижению точности распознавания даже в современных моделях, обученных на больших объемах данных. Проблема усугубляется тем, что акустическая среда постоянно меняется: от тихой комнаты до шумной улицы, от небольшого помещения до большого концертного зала. Поэтому, для успешного развертывания систем распознавания речи в реальном мире, необходимо разработать методы, устойчивые к этим изменениям и способные адаптироваться к новым акустическим условиям без необходимости переобучения или использования большого количества размеченных данных. Решение данной задачи является ключевым шагом к созданию по-настоящему универсальных и надежных систем распознавания речи.
SLM-TTA: Адаптация в реальном времени
Представляем SLM-TTA — новый, параметрически эффективный фреймворк адаптации во время работы (Test-Time Adaptation), предназначенный для смягчения акустического расхождения (acoustic mismatch) без использования размеченных данных. В отличие от традиционных методов, требующих предварительной тренировки на целевых данных, SLM-TTA осуществляет адаптацию непосредственно во время обработки входного аудиопотока. Параметрическая эффективность достигается за счет адаптации лишь небольшой части параметров модели, что снижает вычислительные затраты и потребность в памяти. Данный подход позволяет модели автоматически корректировать свою работу в зависимости от характеристик входящего сигнала, обеспечивая более высокую точность распознавания речи в различных акустических условиях.
Механизм SLM-TTA использует методы минимизации энтропии и псевдо-разметки для обучения непосредственно на входящем аудиопотоке. Минимизация энтропии направлена на снижение неопределенности в предсказаниях модели, заставляя ее генерировать более уверенные и согласованные результаты. Псевдо-разметка заключается в автоматическом присвоении меток неразмеченным данным на основе предсказаний модели, которые затем используются для дальнейшего обучения. Этот процесс позволяет модели адаптироваться к изменяющимся акустическим условиям без необходимости в размеченных данных, эффективно используя информацию, содержащуюся в самом аудиосигнале для улучшения производительности.
Для повышения устойчивости и предотвращения катастрофического забывания, SLM-TTA использует фильтрацию на основе уверенности (Confidence-Aware Filtering). Данный механизм позволяет модели сосредотачивать адаптацию исключительно на надежных сигналах, отбрасывая данные с низкой уверенностью в предсказаниях. Это достигается путем оценки достоверности прогнозов и применения весового коэффициента, который снижает влияние неуверенных данных на процесс адаптации. Таким образом, модель учится на наиболее качественных примерах, что минимизирует риск искажения уже полученных знаний и обеспечивает более стабильную работу в условиях изменяющейся акустической обстановки.
В отличие от традиционных методов адаптации, выполняемых в автономном режиме и требующих предварительной обработки и переобучения модели для каждого нового акустического окружения, SLM-TTA предлагает динамическое решение, адаптирующееся непосредственно во время работы с поступающим аудиопотоком. Такой подход позволяет избежать затрат времени и ресурсов, связанных с переобучением, и обеспечивает масштабируемость за счет возможности адаптации к изменяющимся акустическим условиям в режиме реального времени без использования размеченных данных. В то время как офлайн-методы требуют статического набора данных для адаптации, SLM-TTA непрерывно учится на текущем аудио, обеспечивая более гибкое и эффективное решение для борьбы с акустическими вариациями.
Эмпирическая проверка и результаты
Эксперименты в области автоматического распознавания речи, проведенные на наборе данных LibriSpeech, демонстрируют значительное повышение точности при использовании SLM-TTA в различных шумовых условиях. В частности, в реверберационных средах зафиксировано снижение относительной частоты ошибок (Word Error Rate, WER) до 6.41% по сравнению с базовыми моделями. Данный результат указывает на эффективность SLM-TTA в улучшении качества распознавания речи в сложных акустических условиях, где реверберация является распространенной проблемой.
При оценке на наборе данных CoVoST 2, SLM-TTA демонстрирует стабильное превосходство над базовыми моделями в задачах речевого перевода. В частности, зафиксировано улучшение до 2.71 пункта BLEU даже в условиях реверберации. Это указывает на повышенную устойчивость SLM-TTA к акустическим искажениям, что является критически важным для практического применения систем речевого перевода в реальных условиях.
В ходе тестирования на бенчмарке AIR-Bench система SLM-TTA продемонстрировала высокую способность к обобщению при решении различных задач обработки аудио. В частности, при решении задач вопросно-ответной системы (QA) в условиях реверберации зафиксировано улучшение точности на 0.79%. Это свидетельствует о том, что SLM-TTA эффективно работает с разнообразными аудиоданными и сохраняет производительность даже в сложных акустических условиях, что подтверждает ее универсальность и применимость к широкому спектру задач.
В основе разработанной системы лежит модель Phi-4-Multimodal, демонстрирующая, что эффективная адаптация и достижение высоких результатов в задачах обработки речи и перевода возможно даже при использовании относительно небольших по размеру моделей. Это подтверждается результатами экспериментов на различных датасетах, включая LibriSpeech, CoVoST 2 и AIR-Bench, где система, основанная на Phi-4-Multimodal, показывает значительное улучшение метрик качества — снижение Word Error Rate (WER) до 6.41% и увеличение BLEU score до 2.71 — при различных уровнях зашумленности и реверберации. Использование компактной модели позволяет снизить вычислительные затраты и упростить развертывание системы без существенной потери в производительности.
Влияние и перспективы развития
Предложенный метод SLM-TTA представляет собой практичное решение для внедрения моделей распознавания речи (SLM) в реальные условия эксплуатации, избегая дорогостоящего и трудоемкого сбора больших объемов размеченных данных. Вместо традиционного подхода, требующего обширных датасетов для обучения, SLM-TTA использует технику адаптации моделей, позволяющую эффективно настраивать предварительно обученную модель к новым акустическим условиям, используя лишь небольшое количество неразмеченных данных. Это значительно снижает затраты и упрощает процесс развертывания SLM в различных средах, делая технологию более доступной для широкого круга приложений, включая устройства с ограниченными ресурсами и системы, работающие на периферии сети.
Разработанная структура SLM-TTA отличается высокой эффективностью использования параметров, что делает её особенно привлекательной для применения на устройствах с ограниченными вычислительными ресурсами и в сценариях граничных вычислений. Благодаря минимизации количества обучаемых параметров, модель требует значительно меньше памяти и энергии для работы, не уступая при этом в точности более громоздким альтернативам. Это позволяет внедрять современные технологии распознавания речи непосредственно на мобильные устройства, носимые гаджеты и другие платформы с ограниченной мощностью, открывая новые возможности для интерактивных приложений и систем, работающих в реальном времени, без необходимости подключения к облачным серверам.
Дальнейшие исследования сосредоточены на расширении возможностей SLM-TTA для работы с многоязычными сценариями, что позволит адаптировать систему к различным языковым средам и расширить область ее применения. Параллельно планируется изучение новых целей адаптации, направленных на оптимизацию производительности системы в различных акустических условиях и для разных типов пользователей. Такой подход позволит не только повысить точность распознавания речи, но и создать более гибкую и персонализированную систему взаимодействия человека и компьютера, способную эффективно функционировать в самых разнообразных контекстах.
Предложенный подход, направленный на смягчение эффекта акустического смещения, открывает перспективы для более плавной и надежной коммуникации между человеком и компьютером. Акустическое смещение, возникающее из-за индивидуальных особенностей речи и окружающей среды, часто приводит к ошибкам в системах распознавания и управления голосом. Минимизируя влияние этого фактора, данная разработка позволяет создавать более интуитивные и отзывчивые интерфейсы, адаптирующиеся к особенностям каждого пользователя. Это особенно важно для приложений, требующих высокой точности и скорости реакции, таких как голосовые помощники, системы управления умным домом и медицинское оборудование, где надежность взаимодействия имеет первостепенное значение.
Исследование демонстрирует, что адаптация моделей генерации речи к изменяющимся акустическим условиям требует динамического подхода. Авторы предлагают механизм, позволяющий модели оперативно корректировать небольшую часть параметров, опираясь на энтропию или псевдо-разметку с фильтрацией по уверенности. Этот процесс напоминает реверс-инжиниринг реальности, где система анализирует входящий сигнал и подстраивается под него. Как однажды заметил Винтон Серф: «Интернет — это не просто сеть компьютеров, это сеть людей». В данном случае, модель, подобно человеку, адаптируется к окружению, чтобы обеспечить более качественную коммуникацию, используя доступные данные и оптимизируя свою производительность в реальном времени.
Куда же дальше?
Представленная работа, безусловно, демонстрирует возможность динамической адаптации генеративных моделей речи к меняющимся акустическим условиям. Однако, стоит признать: «починка» лишь небольшой части параметров — это, скорее, элегантный обход проблемы, а не её решение. Система адаптируется, но насколько глубоко она понимает суть акустического сдвига? Ведь каждое «исправление» — это признание первоначальной неполноты модели, своего рода «баг» в архитектуре знания.
Следующим шагом видится отказ от поверхностной адаптации в пользу более фундаментального переосмысления архитектуры моделей. Возможно, необходимо исследовать механизмы, позволяющие модели не просто «подстраиваться» под шум, а активно его фильтровать и игнорировать, как это делает человеческий мозг. Стоит задуматься о внедрении принципов самообучения и активного исследования среды, чтобы модель могла самостоятельно выявлять и компенсировать акустические искажения, не полагаясь на внешние сигналы.
И, наконец, ключевым вопросом остаётся обобщение. Успешная адаптация к одному типу шума не гарантирует устойчивость к другому. Система должна научиться выделять инвариантные признаки речи, не зависящие от конкретных акустических условий. В противном случае, каждое новое окружение потребует новой «заплаты», превращая адаптацию в бесконечный цикл исправлений.
Оригинал статьи: https://arxiv.org/pdf/2512.24739.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Квантовые сети для моделирования молекул: новый подход
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Квантовые прорывы: Хорошее, плохое и смешное
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Квантовые вычисления: от шифрования армагеддона до диверсантов космических лучей — что дальше?
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
2026-01-05 04:45