Автор: Денис Аветисян
Исследователи предложили инновационную стратегию адаптивного вычисления, позволяющую повысить стабильность и эффективность работы нейронных сетей-трансформеров.
Метод LAMP использует смешанную точность и селективное перевычисление ключевых операций для повышения численной устойчивости и снижения вычислительных затрат.
Вычислительная точность в современных больших языковых моделях часто является компромиссом между скоростью и надежностью. В данной работе, озаглавленной ‘LAMP: Look-Ahead Mixed-Precision Inference of Large Language Models’, предлагается адаптивная стратегия инференса, основанная на анализе ошибок округления и позволяющая выборочно пересчитывать критически важные компоненты вычислений с повышенной точностью. Предложенный подход, использующий смешанную точность, позволяет значительно повысить стабильность и эффективность инференса Transformer-моделей, демонстрируя улучшения в точности до двух порядков при минимальных затратах на пересчет. Какие новые возможности для оптимизации и развертывания больших языковых моделей откроет дальнейшее развитие методов адаптивной точности?
Невидимая Угроза: Потеря Точности в Глубоком Обучении
Современные системы глубокого обучения, особенно архитектуры, основанные на трансформерах, в своей работе опираются на арифметику с плавающей точкой. Это означает, что все вычисления, от простых сложений до сложных матричных операций, выполняются с использованием чисел, представленных в формате с ограниченной точностью. Такой подход позволяет обрабатывать широкий диапазон значений, однако неизбежно вносит погрешности округления. Поскольку трансформеры характеризуются огромным количеством параметров и сложными вычислениями, зависимость от арифметики с плавающей точкой становится критическим фактором, влияющим на стабильность и надежность моделей. Использование \mathbb{F}\mathbb{P} является неотъемлемой частью обучения и инференса, определяя возможности и ограничения современных нейронных сетей.
Современные системы глубокого обучения, использующие числа с плавающей точкой для вычислений, неизбежно сталкиваются с проблемой округления. Эта проблема возникает из-за фундаментальной ограниченности представления действительных чисел в цифровом формате, где каждое число может быть представлено лишь с конечной точностью. Неизбежная погрешность округления, хотя и кажется незначительной на первый взгляд, накапливается в процессе многократных операций, таких как сложение и умножение, и может приводить к заметным отклонениям в результатах. Особенно критично это становится в сложных архитектурах, где даже небольшие ошибки могут усиливаться и приводить к нестабильности модели, снижению её точности и непредсказуемым результатам. Таким образом, округление представляет собой не просто техническую особенность, но и потенциальную угрозу для надежности и воспроизводимости систем искусственного интеллекта.
Накопление ошибок округления во время вычислений представляет собой серьезную угрозу надежности моделей глубокого обучения. В частности, операции накопления, такие как суммирование векторов или матриц, усиливают эти погрешности, поскольку небольшие расхождения при каждой итерации суммируются, приводя к значительному отклонению от истинного значения. Особенно чувствительна к этому функция Softmax, широко используемая для классификации. Softmax(x_i) = \frac{e^{x_i}}{\sum_{j=1}^{K} e^{x_j}} — даже незначительные ошибки в вычислении экспоненты и суммы в знаменателе могут привести к искажению вероятностей, нарушая процесс принятия решений моделью и снижая точность прогнозов. Таким образом, неконтролируемое накопление ошибок округления может приводить к нестабильности и непредсказуемости работы сложных нейронных сетей, требуя разработки специальных методов для смягчения их влияния.
Смешанная Точность: Частичное Решение с Неявными Издержками
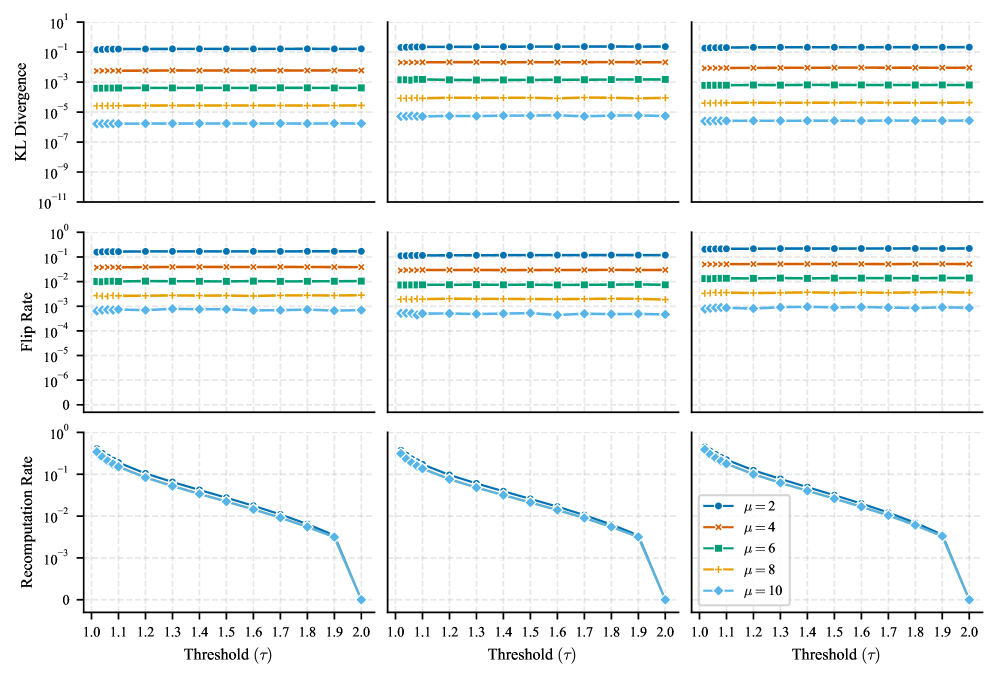
Использование смешанной точности (mixed precision) представляет собой перспективный подход к снижению потребления памяти и ускорению процесса обучения нейронных сетей. Этот метод заключается в применении различных уровней точности представления чисел (например, 16-битной с плавающей точкой вместо 32-битной) для различных частей сети. Снижение точности позволяет уменьшить объем памяти, необходимый для хранения весов и активаций, а также ускорить вычисления, особенно на аппаратном обеспечении, оптимизированном для работы с пониженной точностью. При этом, критически важным является грамотный выбор частей сети, для которых допустимо снижение точности, чтобы избежать существенной потери производительности или нестабильности обучения.
Неосторожное применение смешанной точности может усугубить ошибку округления в критически важных операциях, приводя к непредсказуемому поведению и снижению производительности модели. Снижение точности представления чисел с плавающей точкой, особенно в операциях, включающих вычитание близких по значению чисел или умножение малых чисел, увеличивает относительную ошибку округления. Эта ошибка может накапливаться в процессе многократных вычислений, приводя к значительным отклонениям от ожидаемых результатов и, как следствие, к ухудшению метрик качества модели. Проблемы проявляются в расчетах градиентов и обновлении весов, что может привести к нестабильности обучения или даже к расхождению модели.
Особую чувствительность к накоплению ошибок округления демонстрируют ключевые вычисления в архитектуре Transformer, такие как скалярное произведение Key и Query (Key \cdot Query) и нормализация слоев. В данных операциях даже незначительные погрешности, возникающие при использовании пониженной точности, могут экспоненциально усиливаться при последовательных вычислениях. Это происходит из-за того, что результаты данных операций являются входными данными для последующих слоев сети, и любая неточность передается и накапливается, приводя к ухудшению сходимости обучения и снижению итоговой производительности модели. В частности, скалярное произведение Key и Query влияет на механизм внимания, а ошибки в нормализации слоев могут дестабилизировать процесс обучения.
LAMP Evaluation: Адаптивная Точность для Надежного Вывода
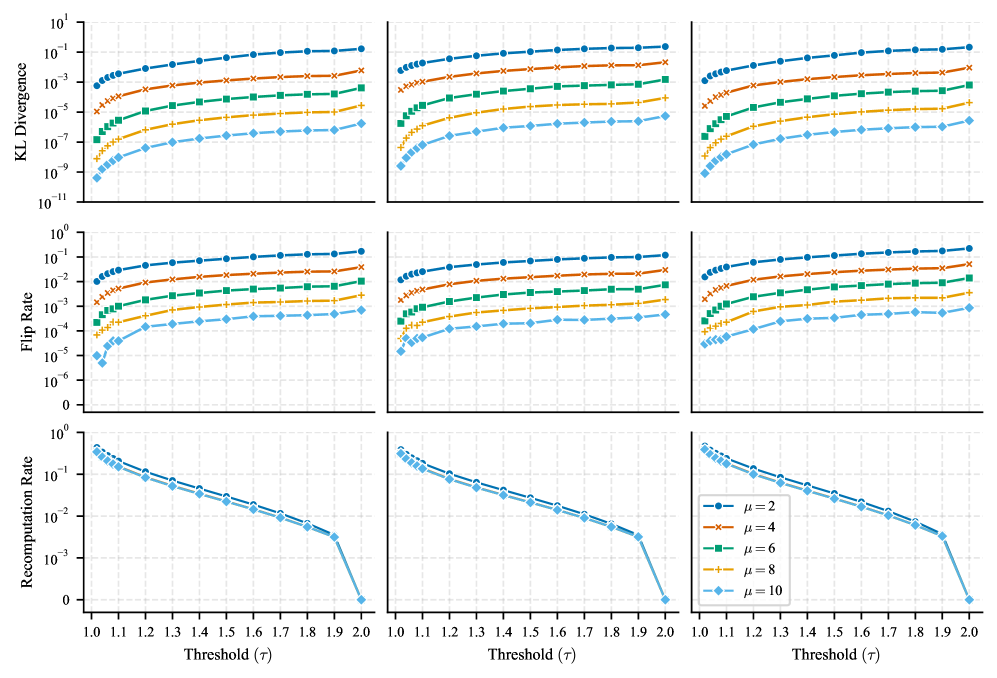
LAMP Evaluation представляет собой новый метод адаптивного выбора операций для выполнения в повышенной точности с целью снижения влияния ошибки округления. В отличие от статических подходов, требующих выполнения всех или заранее определенных операций в высокой точности, LAMP динамически оценивает чувствительность каждой операции к потере точности во время выполнения. Это достигается путем мониторинга выходного распределения вычислений и определения тех, которые наиболее подвержены ошибкам округления. Адаптивное повышение точности только для критических операций позволяет минимизировать влияние ошибок округления на итоговую точность модели, сохраняя при этом общую производительность и снижая вычислительные затраты.
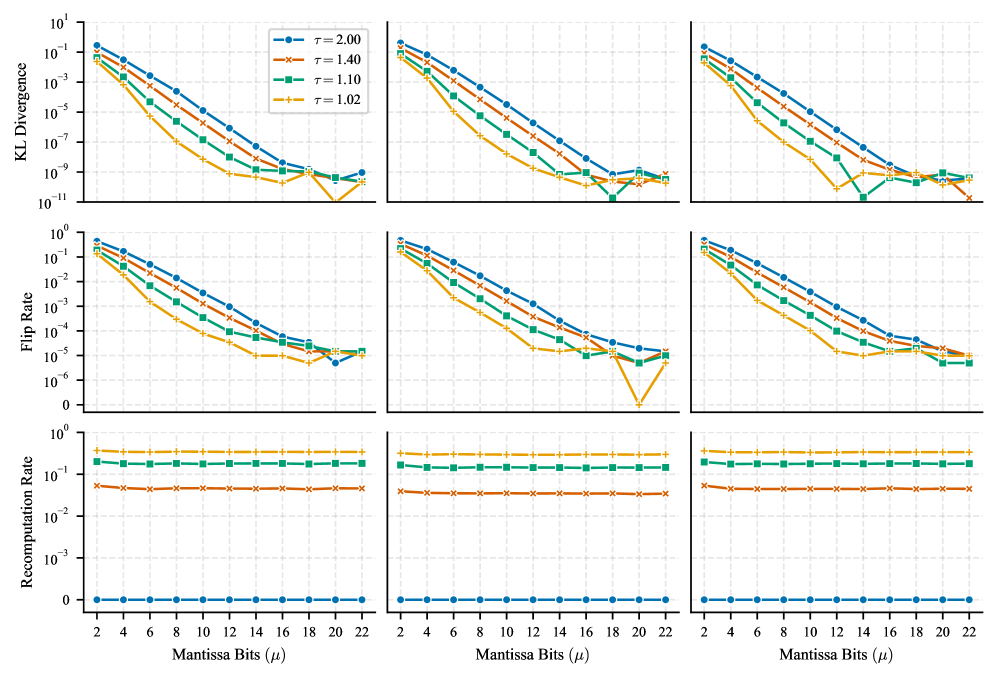
Метод LAMP использует расхождение Кульбака-Лейблера (KL Divergence) для мониторинга распределения выходных данных вычислений в процессе инференса. KL Divergence позволяет оценить степень различия между распределением выходных данных, выполненных в пониженной точности, и эталонным распределением, полученным при вычислениях в полной точности. Операции, демонстрирующие значительное увеличение KL Divergence, идентифицируются как наиболее чувствительные к потере точности, что указывает на повышенный риск ошибок округления и потенциальное снижение точности модели. Динамическое отслеживание KL Divergence позволяет LAMP целенаправленно перевычислять критические операции в более высокой точности, минимизируя влияние ошибок округления без существенного снижения производительности.
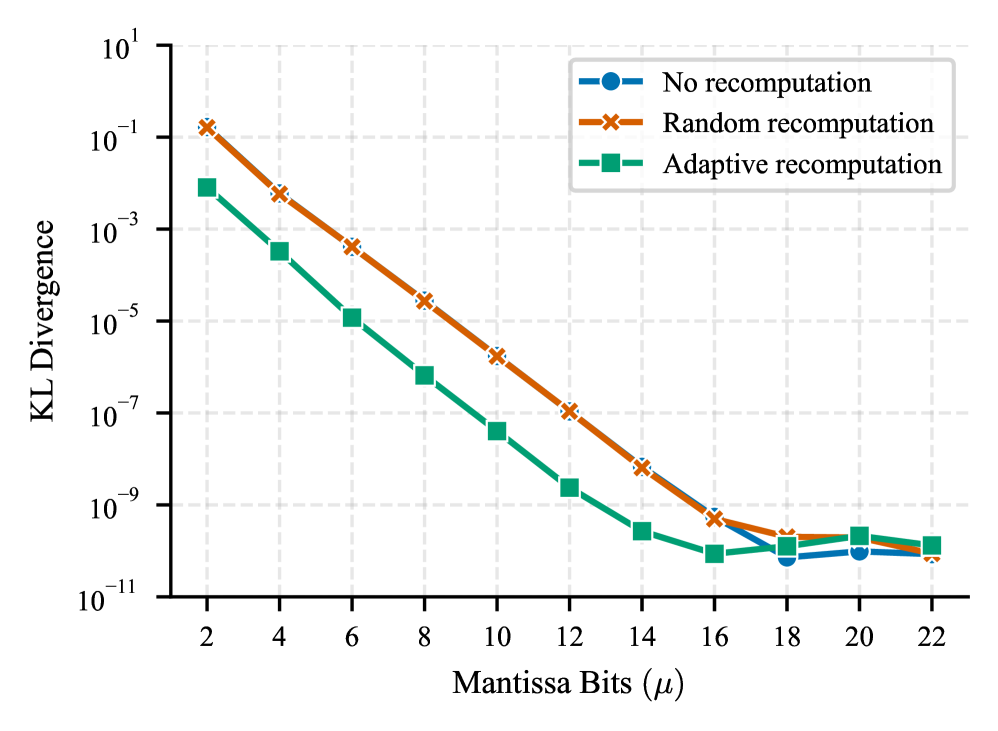
Метод LAMP динамически повышает точность вычислений для критически важных операций, что позволяет минимизировать влияние ошибки округления и поддерживать высокую точность модели без снижения производительности. Этот подход основан на мониторинге выходного распределения вычислений и выборочном увеличении разрядности для тех операций, которые наиболее подвержены потере точности. Благодаря этому, LAMP позволяет существенно снизить частоту изменений в предсказаниях модели по сравнению с эталонной моделью, при этом затраты на перевычисления составляют всего 3.4%.
Оценка LAMP демонстрирует значительное снижение частоты смены предсказаний (Flip Rate) — процента предсказаний, отличающихся от эталонной модели, что подтверждает ее эффективность. В ходе тестирования зафиксировано до 10-кратного снижения расхождения КЛ-дивергенции (KL Divergence) при скорости повторных вычислений всего 3,4%. Это указывает на возможность существенного повышения надежности модели без значительных затрат производительности, поскольку лишь небольшая часть операций требует выполнения в повышенной точности для минимизации влияния ошибок округления.
Влияние и Перспективы для Надежного Искусственного Интеллекта
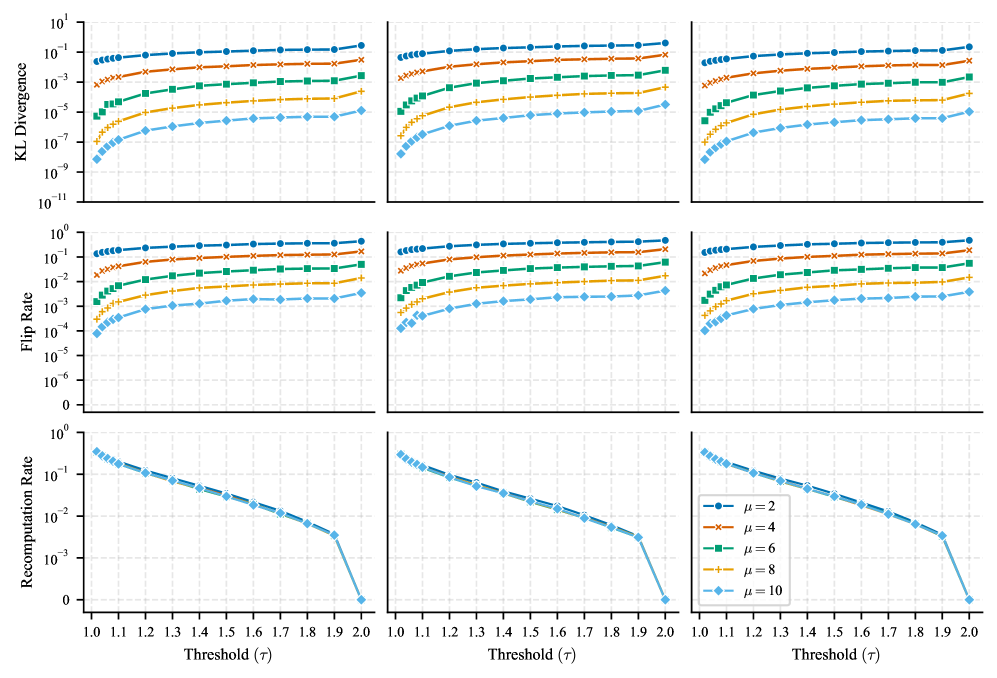
Оценка LAMP представляет собой значительный прорыв в создании более надежных и заслуживающих доверия систем искусственного интеллекта, особенно в областях, где ставки высоки — например, в медицине, финансах или автономном транспорте. Традиционные модели глубокого обучения часто подвержены ошибкам округления при вычислениях с плавающей точкой, что может приводить к непредсказуемым результатам и снижать общую надежность системы. LAMP позволяет адаптировать точность вычислений, динамически увеличивая ее в критических участках модели и снижая в менее важных, что обеспечивает сохранение высокой производительности при одновременном повышении устойчивости к ошибкам и улучшении воспроизводимости результатов. Этот подход открывает новые возможности для внедрения ИИ в ответственные сферы, где безопасность и надежность являются первостепенными задачами, и способствует укреплению доверия к технологиям искусственного интеллекта.
Повсеместная проблема ошибок округления, возникающих в процессе вычислений глубоких нейронных сетей, долгое время сдерживала раскрытие их полного потенциала. Эти ошибки, накапливаясь при последовательных операциях, могут приводить к снижению точности и непредсказуемому поведению моделей, особенно в критически важных приложениях. Однако, фокусируясь на минимизации влияния ошибок округления, становится возможным значительно повысить надежность и производительность алгоритмов машинного обучения. Исследования показывают, что адаптивные стратегии, позволяющие динамически регулировать точность вычислений, способны не только уменьшить эти ошибки, но и открыть путь к разработке более эффективных и устойчивых систем искусственного интеллекта, способных решать задачи, ранее считавшиеся недостижимыми. Освобождение от ограничений, накладываемых ошибками округления, позволит создавать модели, способные к более сложным рассуждениям, более точным прогнозам и более надежной работе в реальных условиях.
Предстоящие исследования направлены на расширение области применения LAMP, охватывая более широкий спектр архитектур глубокого обучения, помимо тех, что были изучены на данный момент. Особое внимание будет уделено оценке потенциала этой адаптивной стратегии точности для повышения обобщающей способности и устойчивости моделей к различным возмущениям и шумам. Предполагается, что расширение LAMP на различные типы нейронных сетей, такие как трансформеры и графовые нейронные сети, позволит не только снизить вычислительные затраты и энергопотребление, но и значительно повысить надежность и предсказуемость работы искусственного интеллекта в реальных условиях, где входные данные часто бывают неполными или зашумленными. Исследователи планируют изучить, как адаптивная точность может способствовать более эффективному обучению моделей на ограниченных объемах данных и улучшить их способность к переносу знаний на новые, ранее не встречавшиеся задачи.
Адаптивная стратегия точности открывает путь к созданию более эффективного и устойчивого искусственного интеллекта, способного надежно функционировать в реальных условиях. Исследования показали, что при уровне перевычислений всего в 15% удается добиться стократного снижения расхождения Кульбака-Лейблера KL, а увеличение этого показателя до 34,3% приводит к тысячекратному уменьшению KL. Это свидетельствует о значительном потенциале данной методики для повышения надежности и стабильности глубоких нейронных сетей, особенно в критически важных приложениях, где даже незначительные погрешности могут иметь серьезные последствия. Возможность снижения вычислительных ошибок при минимальных затратах ресурсов делает адаптивную точность перспективным направлением для дальнейших исследований и практического внедрения в различные области применения ИИ.
Данная работа демонстрирует стремление к кристальной ясности в сложных вычислениях. Авторы, исследуя методы адаптивного вывода для трансформаторных сетей, фактически преследуют цель минимизировать избыточность, предлагая элегантное решение для повышения численной устойчивости и эффективности. Как однажды заметил Джон фон Нейман: «В науке не существует готовых ответов, только новые вопросы». И действительно, представленный подход LAMP, оптимизируя смешанную точность и выборочное перевычисление, не только решает текущие проблемы с ошибками округления, но и открывает путь для дальнейших исследований в области низкоточных вычислений и оптимизации производительности больших языковых моделей. Простота и элегантность предложенного решения — подтверждение того, что истинное совершенство достигается путем удаления лишнего.
Что дальше?
Абстракции стареют. Представленная работа, фокусируясь на смешанном представлении чисел и адаптивной перекоммутации, лишь частично снимает проблему накопления ошибок в трансформаторных сетях. Ошибки округления — это не ошибка реализации, а фундаментальное ограничение вычислений. Требуется более глубокий анализ композиционных численных эффектов, выходящий за рамки простого повышения точности.
Каждая сложность требует алиби. Эффективность адаптивной стратегии, безусловно, заслуживает внимания, но вопрос о её универсальности остается открытым. Различные архитектуры и наборы данных могут потребовать иных подходов к выбору точности. Необходимо исследовать, как принципы, предложенные в данной работе, могут быть адаптированы к другим моделям и задачам.
Следующим шагом видится не просто оптимизация существующих алгоритмов, а поиск принципиально новых методов представления и обработки информации. Точность — это лишь один из аспектов. Важнее — устойчивость, предсказуемость и интерпретируемость. И, возможно, стоит признать, что идеальной точности достичь невозможно, и сосредоточиться на контроле ошибок, а не на их устранении.
Оригинал статьи: https://arxiv.org/pdf/2601.21623.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовый оптимизатор: Новый подход к сложным задачам
- Кванты в Финансах: Не Шутка!
- Гармония в коде: Распознавание аккордов с помощью глубокого обучения
- Взлом языковых моделей: эволюция атак, а не подсказок
- Квантовый скачок из Андхра-Прадеш: что это значит?
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Искусственный интеллект на допросе: как объяснить решения в цифровой криминалистике?
2026-01-31 13:53