Автор: Денис Аветисян
В статье описывается библиотека astra-langchain4j, позволяющая использовать возможности больших языковых моделей в рамках агентного программирования на языке ASTRA.
Исследование посвящено интеграции больших языковых моделей в язык ASTRA, анализу ограничений в области рассуждений и сложностям эффективной разработки промптов.
Несмотря на стремительное развитие генеративных моделей искусственного интеллекта, интеграция с традиционными инструментами разработки агентов остается сложной задачей. В статье ‘astra-langchain4j: Experiences Combining LLMs and Agent Programming’ представлен опыт разработки библиотеки для интеграции больших языковых моделей (LLM) в язык программирования ASTRA, ориентированный на разработку агентов. Полученные результаты демонстрируют успешную интеграцию, однако выявляют ограничения возможностей логического вывода LLM и сложность эффективной разработки запросов. Какие перспективы открываются для создания более надежных и интеллектуальных агентов, сочетающих сильные стороны традиционного программирования и возможностей генеративного ИИ?
Традиционные системы против адаптивного интеллекта: Почему старые подходы больше не работают
Традиционные системы искусственного интеллекта зачастую демонстрируют ограниченные возможности в условиях сложных и динамично меняющихся сред. Их работа, как правило, основана на заранее заданных алгоритмах и наборах данных, что затрудняет адаптацию к новым, непредвиденным ситуациям. В отличие от них, реальный мир характеризуется постоянной неопределенностью и требует от систем не только обработки информации, но и способности к рассуждению, планированию и принятию решений на основе неполных или противоречивых данных. Эта неспособность к адаптивному мышлению приводит к тому, что традиционные ИИ-системы быстро теряют эффективность при столкновении с задачами, выходящими за рамки их первоначальной подготовки, и нуждаются в постоянном вмешательстве человека для корректировки действий и переобучения.
Агентный искусственный интеллект, основанный на автономных агентах, представляет собой принципиальный сдвиг в подходах к решению задач. Вместо реактивного ответа на заданные условия, подобные системы способны самостоятельно определять цели, планировать действия и адаптироваться к изменяющейся обстановке. Этот переход от пассивного выполнения команд к проактивному поиску решений позволяет справляться со сложными и динамичными задачами, которые ранее требовали постоянного вмешательства человека. Автономные агенты, действуя как независимые единицы, способны самостоятельно исследовать пространство возможностей, оценивать риски и принимать обоснованные решения, что открывает перспективы для автоматизации процессов, требующих гибкости, инициативности и долгосрочного планирования.
В основе систем агентного ИИ лежит синергия больших языковых моделей (LLM) и надежных архитектур агентов. Исследования показали, что простое масштабирование LLM недостаточно для решения сложных задач, требующих планирования, адаптации и взаимодействия с окружением. Поэтому, разрабатываются системы, в которых LLM выступают в качестве “мозга”, генерируя стратегии и принимая решения, а архитектура агента обеспечивает выполнение этих стратегий посредством взаимодействия с инструментами и средой. Наша прототипная библиотека для интеграции LLM в ASTRA демонстрирует этот подход, предоставляя набор компонентов для создания автономных агентов, способных самостоятельно ставить цели, разбивать их на подзадачи, выбирать необходимые инструменты и итерировать процесс до достижения результата. Это позволяет значительно расширить возможности ИИ за пределы пассивного ответа на запросы, переходя к проактивному решению проблем и автономному выполнению задач.
ASTRA: Платформа для создания разумных агентов на базе LLM
ASTRA представляет собой язык программирования, разработанный для интеграции больших языковых моделей (LLM) в архитектуры агентов. Он предназначен для упрощения процесса создания и управления агентами, использующими LLM, путем предоставления структурированного способа определения логики их поведения. В отличие от прямого использования LLM для выполнения задач, ASTRA позволяет разработчикам создавать агентов с четко определенными функциями и взаимодействиями, что повышает надежность и предсказуемость их работы. Язык обеспечивает абстракцию от сложности LLM, позволяя сосредоточиться на разработке агентов высокого уровня, способных решать конкретные задачи.
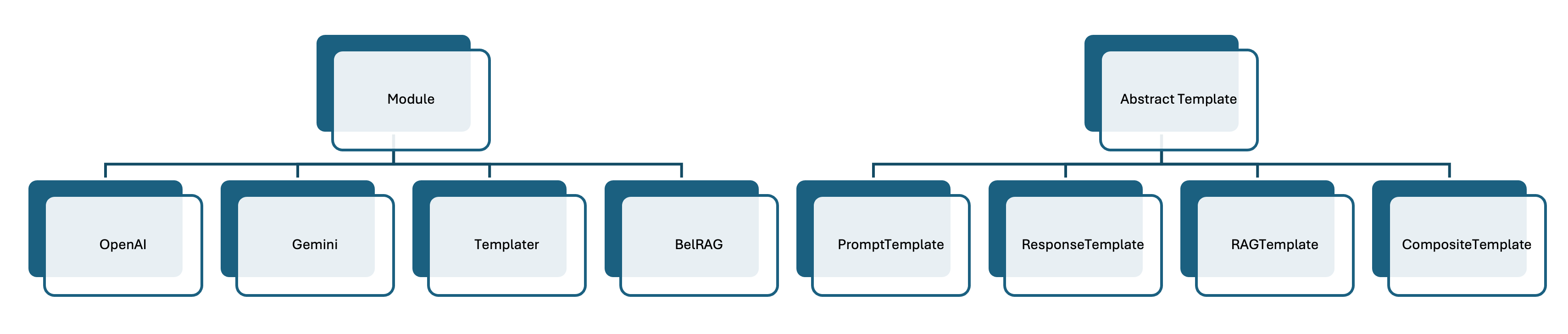
Язык ASTRA использует модульную структуру, представленную “Модулями”, для расширения функциональности агентов. Эти Модули представляют собой отдельные компоненты, позволяющие добавлять в агента специализированные возможности, такие как доступ к внешним API, выполнение сложных вычислений или обработка специфических типов данных. Модульность позволяет разработчикам создавать и интегрировать новые функции без изменения основной архитектуры агента, обеспечивая гибкость и масштабируемость системы. Каждый Модуль инкапсулирует определенную задачу и предоставляет стандартизированный интерфейс для взаимодействия с другими компонентами агента, что упрощает процесс разработки и отладки.
Язык ASTRA обеспечивает бесшовную интеграцию с LangChain4J, предоставляя доступ к широкому спектру больших языковых моделей (LLM). Данная интеграция позволяет разработчикам легко использовать существующие LLM в рамках ASTRA-агентов, не требуя существенной переработки кода. В ходе проведенных исследований продемонстрирована работоспособность ASTRA в трех различных сценариях применения, подтверждающих его гибкость и адаптивность к различным задачам, требующим использования LLM.
Belief-Driven RAG: Улучшение рассуждений агентов на основе убеждений
Эффективное проектирование запросов (prompt engineering) играет критически важную роль в управлении большими языковыми моделями (LLM). Для достижения оптимальных результатов требуется тщательная разработка и оптимизация структуры запроса, включая определение точных инструкций, предоставление контекста и форматирование выходных данных. Недостаточно продуманные запросы могут приводить к нерелевантным, неточным или неполным ответам. Процесс оптимизации обычно включает в себя итеративное тестирование различных вариантов запросов и анализ полученных результатов для выявления наиболее эффективных подходов. Важно учитывать специфику конкретной LLM и задачи, для которой она используется, поскольку оптимальные запросы могут существенно различаться.
BeliefRAG использует внутренний процесс ‘Пересмотра Убеждений’ агента для улучшения ‘Генерации, Расширенной Извлечением’ (Retrieval-Augmented Generation). В основе лежит динамическое обновление базы знаний агента на основе извлеченных документов. В процессе работы, агент оценивает релевантность полученной информации и, при необходимости, корректирует свои существующие убеждения, что позволяет формировать более точные и связные ответы. В отличие от традиционных RAG-систем, BeliefRAG не просто добавляет извлеченные данные к контексту запроса, а активно интегрирует новую информацию в свою внутреннюю модель знаний, повышая устойчивость к нерелевантным или противоречивым данным.
Подход BeliefRAG позволяет агентам основывать свои ответы на релевантных знаниях, что способствует повышению точности и связности генерируемого текста. В основе лежит процесс «Пересмотра Убеждений» (Belief Revision), который динамически корректирует внутреннее представление агента о мире на основе полученной информации. Как показано в нашей опубликованной работе, включающей прототипную реализацию, это обеспечивает более обоснованные и контекстуально уместные ответы, снижая вероятность галлюцинаций и неточностей в ответах агента.
Практическое применение: от крестиков-ноликов до планирования путешествий
Пример игры в крестики-нолики демонстрирует возможности ASTRA по эффективному управлению стратегиями, реализуемыми на основе больших языковых моделей. В данном случае, для представления игровой информации и состояний используется формат ‘JsonNode’, что обеспечивает гибкость и структурированность данных. ASTRA позволяет не просто генерировать ходы, но и контролировать логику игры, адаптируясь к действиям оппонента и стремясь к оптимальному результату. Использование ‘JsonNode’ упрощает взаимодействие между языковой моделью и системой управления, позволяя представлять игровую доску, возможные ходы и оценки позиций в удобном для обработки формате. Этот подход позволяет создавать интеллектуальных агентов, способных к обучению и адаптации, демонстрируя потенциал ASTRA в области игрового искусственного интеллекта.
Пример с планировщиком путешествий демонстрирует возможности системы в организации взаимодействия между несколькими агентами. Для делегирования задач и координации действий между ними используется протокол FIPA Request Interaction Protocol. Этот протокол позволяет агентам запрашивать информацию, услуги или выполнение определенных действий у других агентов, обеспечивая структурированный и стандартизированный обмен сообщениями. В рамках данного примера, агенты совместно разрабатывают план путешествия, распределяя задачи, такие как поиск авиабилетов, бронирование отелей и составление маршрута, благодаря чему система демонстрирует свою способность к сложным совместным действиям и эффективной организации многоагентного взаимодействия.
Представленные примеры, охватывающие как простую игру в крестики-нолики, так и сложные задачи планирования путешествий, ярко демонстрируют универсальность разработанного фреймворка. Их реализация не является лишь теоретической демонстрацией; они включены в состав прототипной библиотеки, предоставляющей разработчикам готовые инструменты для практического применения. Такой подход позволяет быстро оценить возможности системы и адаптировать её для решения широкого спектра задач, от создания игровых агентов до автоматизации сложных логистических процессов. Эта библиотека служит отправной точкой для дальнейших исследований и разработок в области многоагентных систем и искусственного интеллекта.
Взгляд в будущее: к сотрудничеству человека и робота
Интеграция больших языковых моделей, таких как ‘OpenAI’ и ‘Gemini’, в архитектуру ASTRA значительно расширяет спектр возможных поведенческих паттернов агента. Ранее ограниченные заранее запрограммированными реакциями, теперь агенты способны генерировать более сложные и адаптивные стратегии, опираясь на обширные знания, заложенные в этих моделях. Это позволяет им не просто выполнять конкретные задачи, но и понимать контекст, рассуждать о целях и планировать действия, приближая их поведение к человеческому. В результате, ASTRA получает возможность решать более разнообразные и непредсказуемые задачи, требующие гибкости и творческого подхода, что открывает новые перспективы для взаимодействия человека и робота.
Интеграция передовых языковых моделей значительно расширяет горизонты взаимодействия человека и робота, приближая его к естественному общению. Благодаря способности понимать и генерировать человеческую речь, роботы, оснащенные подобными системами, способны воспринимать команды и запросы в более свободной, интуитивно понятной форме, минуя необходимость точного следования жестким протоколам. Это открывает возможности для более плавного и эффективного сотрудничества, где робот выступает не просто исполнителем команд, а полноценным партнером, способным к адаптации и пониманию контекста. В результате, взаимодействие становится менее обременительным и более продуктивным, позволяя человеку сосредоточиться на решении задачи, а не на формулировании инструкций для машины.
Дальнейшие исследования направлены на усовершенствование этих систем для применения в сложных реальных задачах, требующих надежного логического мышления и планирования. Основываясь на созданном прототипе и продемонстрированных возможностях, ученые стремятся расширить спектр решаемых задач, включая сценарии, где робот должен самостоятельно принимать решения в динамичной и непредсказуемой среде. Особое внимание уделяется разработке алгоритмов, позволяющих роботу не просто выполнять заданные инструкции, а адаптироваться к изменяющимся условиям и находить оптимальные решения для достижения поставленной цели, что откроет новые горизонты для взаимодействия человека и робота в различных сферах деятельности.
Наблюдения за интеграцией больших языковых моделей в ASTRA неизбежно приводят к мысли о хрупкости любой, даже самой элегантной, архитектуры. Стремление к созданию самовосстанавливающихся систем, как показывает практика, часто оборачивается лишь отсрочкой неизбежного. Как однажды заметил Дональд Дэвис: «Любая революционная технология завтра станет техдолгом». В данном случае, сложность заключается не только в ограниченных возможностях LLM в плане рассуждений, но и в искусстве точного формулирования запросов. Идеальный промт — это миф, а документация по нему — лишь форма коллективного самообмана. Впрочем, если баг воспроизводится — значит, у нас стабильная система, верно?
Что Дальше?
Представленная работа, как и большинство попыток приручить языковые модели, демонстрирует скорее возможности интеграции, чем решение фундаментальных проблем. ASTRA, будучи элегантным фреймворком для агентного программирования, сталкивается с неизбежной реальностью: языковые модели, несмотря на всю свою статистическую мощь, склонны к галлюцинациям и требуют постоянной, утомительной тонкой настройки промптов. Это не недостаток библиотеки, а скорее закономерность. Каждый «революционный» шаг в области LLM неизбежно превращается в техдолг, требующий постоянного обслуживания.
Более того, увлечение Retrieval-Augmented Generation (RAG) не решает проблему истинного рассуждения, а лишь маскирует её, заменяя логику на поиск ближайших соответствий в корпусе данных. Ожидать от системы, построенной на статистических закономерностях, прорывных решений — наивно. Вместо этого, вероятно, стоит сосредоточиться на гибридных подходах, сочетающих сильные стороны символьного AI и статистических моделей, пусть даже это и потребует больше усилий.
В конечном итоге, будущее агентных систем, интегрированных с LLM, видится не в создании всемогущих «разумных» агентов, а в разработке специализированных инструментов, решающих конкретные задачи. Мы не чиним продакшен — мы просто продлеваем его страдания. И это, пожалуй, самое реалистичное предсказание.
Оригинал статьи: https://arxiv.org/pdf/2601.21879.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Гармония в коде: Распознавание аккордов с помощью глубокого обучения
- Визуальный след: Сжатие рассуждений для мощных языковых моделей
- Кванты в Финансах: Не Шутка!
- Взлом языковых моделей: эволюция атак, а не подсказок
- Квантовый оптимизатор: Новый подход к сложным задачам
- Оптимизация Комбинаторных Задач: Новый Взгляд с Помощью Автокодировщиков
- Волны спинов для нейроморфных вычислений: новый подход к скорости и эффективности
2026-01-31 00:20