Автор: Денис Аветисян
Новое исследование показывает, как лингвистические правила и характеристики говорящего позволяют точно контролировать акцент в синтезированной речи.
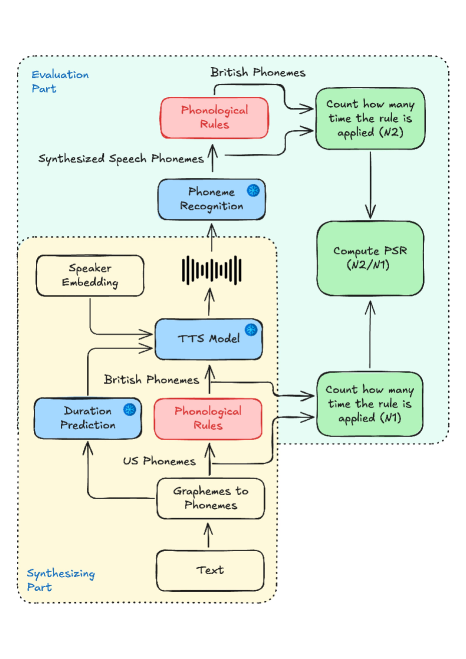
Количественная оценка взаимодействия между характеристиками говорящего и фонологическими правилами для управления акцентом в системах преобразования текста в речь.
Несмотря на успехи современных систем синтеза речи, точное управление акцентом остается сложной задачей из-за неявного кодирования лингвистических особенностей в векторных представлениях говорящих. В работе ‘Quantifying Speaker Embedding Phonological Rule Interactions in Accented Speech Synthesis’ исследуется взаимодействие между этими представлениями и формализованными правилами фонологии, влияющими на произношение. Показано, что комбинирование правил, описывающих особенности акцентов американского и британского английского, с векторными представлениями позволяет более эффективно контролировать силу акцента и повысить степень разделения лингвистических и индивидуальных характеристик голоса. Каким образом предложенный подход может быть расширен для моделирования более широкого спектра акцентов и диалектов, а также для повышения реалистичности синтезируемой речи?
Проблема Реалистичности Акцента в Синтезе Речи
Современные системы синтеза речи зачастую сталкиваются с проблемой передачи естественности звучания и точного воспроизведения региональных акцентов. Несмотря на значительный прогресс в области обработки языка, сгенерированная речь нередко звучит роботизированно и лишена характерных интонаций, присущих носителям определенного диалекта. Это связано с тем, что алгоритмы синтеза, как правило, фокусируются на правильности произношения отдельных звуков, упуская из виду тонкие фонетические нюансы, определяющие акцент. В результате, речь может казаться неестественной и лишенной эмоциональной окраски, что снижает её воспринимаемость и затрудняет коммуникацию, особенно в контексте, где важна аутентичность и узнаваемость голоса.
Реализация достоверного контроля акцента является ключевой задачей для современных систем синтеза речи, особенно в контексте быстро развивающихся приложений, таких как голосовые помощники и персонализированная коммуникация. Несмотря на значительный прогресс в области синтеза речи, воссоздание тонкостей региональных акцентов представляет собой серьезную проблему. Достижение реалистичного звучания требует не просто имитации отдельных звуков, но и точного воспроизведения просодических особенностей, ритма и интонаций, характерных для конкретного акцента. Сложность заключается в том, что акцент — это не просто замена звуков, а комплексная система изменений в артикуляции и произношении, требующая детального моделирования и адаптации. В результате, существующие системы часто испытывают трудности с обеспечением как аутентичности акцента, так и общей разборчивости речи, что ограничивает их применение в ситуациях, где важна естественность и понятность.
Существующие методы синтеза речи, направленные на воссоздание региональных акцентов, зачастую сталкиваются с проблемой баланса между выраженностью акцента и общим качеством звучания. В стремлении подчеркнуть особенности произношения, системы нередко создают гиперболизированные, карикатурные акценты, которые звучат неестественно и даже искажают смысл сказанного. Другой распространенный недостаток — снижение разборчивости речи, когда чрезмерное изменение фонетических характеристик приводит к невнятному произношению и затрудняет восприятие информации. Таким образом, достижение реалистичного и понятного акцента требует тонкой настройки параметров синтеза, позволяющей сохранить естественность звучания и избежать упрощенных или искаженных представлений о региональном произношении.
Существенная сложность в создании реалистичной синтезированной речи с акцентом заключается в тонкой настройке фонетических признаков. Речь — это не просто последовательность звуков, а сложная комбинация артикуляции, интонации и тембра, и даже незначительные изменения в этих параметрах могут существенно повлиять на восприятие акцента. Ученым представляется трудным точно моделировать и воспроизводить эти нюансы, поскольку акценты часто проявляются в микроскопических вариациях произношения, которые трудно уловить и алгоритмически закрепить. Проблему усугубляет тот факт, что фонетические характеристики акцента могут варьироваться в зависимости от конкретного говорящего и контекста речи, что требует разработки адаптивных систем, способных учитывать индивидуальные особенности и динамику разговорной речи. Достижение этой точности необходимо для того, чтобы избежать создания стереотипных или неестественных акцентов, которые могут исказить смысл сообщения или вызвать негативную реакцию слушателей.
Основы Коррекции Акцента на Основе Правил
Для целенаправленной коррекции акцента мы используем фонологические правила — систематические преобразования звуков речи. Эти правила позволяют точно воздействовать на ключевые характеристики произношения, такие как ротичность (наличие или отсутствие звука [r] после гласных) и флэппинг (замена звука [t] или [d] на [ɾ] между гласными). Применяя эти правила, мы осуществляем конкретные изменения в артикуляции, направленные на достижение желаемого американского или британского произношения, избегая произвольных корректировок и обеспечивая лингвистически обоснованный подход к модификации акцента.
Набор правил, используемый для модификации акцента, разработан специально для сопоставления фонологических различий между американским и британским английским. Эти правила оперируют конкретными звуковыми соответствиями и преобразованиями, например, заменой определенных гласных или согласных звуков, характерных для одного варианта английского, на их эквиваленты в другом. Такой структурированный подход обеспечивает целенаправленное воздействие на ключевые признаки акцента, позволяя систематически корректировать произношение и приблизить его к целевому варианту. Правила определяют, как конкретные звуки в исходном акценте должны быть изменены для соответствия нормам произношения американского или британского английского, обеспечивая предсказуемость и эффективность процесса коррекции.
В рамках комплексной коррекции акцента используются соответствия гласных звуков, представляющие собой систематические сдвиги в произношении. Эти соответствия отражают различия в системе гласных американского и британского английского языков, например, соответствие между [ʌ] в британском английском и [æ] в американском. Включение этих соответствий в набор правил позволяет целенаправленно изменять произношение гласных, обеспечивая более естественное и понятное звучание речи для носителей целевого акцента. Определение и применение этих соответствий основано на фонетических исследованиях и лингвистическом анализе, что гарантирует точность и эффективность коррекции.
Применение основанного на правилах подхода к коррекции акцента гарантирует, что вносимые изменения в произношение имеют лингвистическую обоснованность и воспринимаются на слух. Вместо произвольных корректировок, данный метод опирается на систематические фонетические соответствия между американским и британским английским, что позволяет целенаправленно воздействовать на ключевые особенности акцента. Такая структура обеспечивает не только акустическую различимость внесенных изменений, но и их соответствие принципам фонологии английского языка, что способствует более естественному и эффективному освоению желаемого акцента.
Нейронный Синтез и Сила Векторных Представлений Говорящего
Для синтеза речи используется Kokoro TTS — многоязыковая модель преобразования текста в речь. В процессе генерации речи применяется модуль Misaki G2P, осуществляющий преобразование графемических последовательностей (текста) в фонемные, что необходимо для корректного произношения. Данный модуль обеспечивает транскрипцию текста в фонетическую форму, служащую входными данными для Kokoro TTS, позволяя модели генерировать аудиосигнал, соответствующий заданному тексту.
В процессе синтеза речи используются векторные представления, известные как Speaker Embeddings, для управления характеристиками голоса. Эти векторы, полученные на основе анализа голосовых образцов конкретного диктора, служат входными данными для модели синтеза, позволяя точно контролировать такие параметры, как тембр, высота тона и манера речи. Изменяя значения Speaker Embeddings, можно плавно переключаться между разными голосами или даже создавать новые, гибридные голоса, сохраняя при этом естественность и разборчивость синтезируемой речи. Фактически, Speaker Embeddings позволяют модели «учитывать» индивидуальные особенности голоса диктора, делая сгенерированную речь более реалистичной и персонализированной.
Для достижения баланса между лингвистической точностью и естественностью синтезируемой речи, используется гибридный подход, сочетающий в себе правила модификации и векторные представления говорящего (speaker embeddings). Правила позволяют точно контролировать отдельные аспекты произношения и обеспечивают соответствие фонетической транскрипции исходному тексту. В то же время, speaker embeddings, обученные на данных различных говорящих, позволяют модели улавливать тонкие нюансы произношения и интонации, обеспечивая более реалистичное и естественное звучание. Комбинация этих двух методов позволяет добиться оптимального результата, сочетающего в себе точность и выразительность.
Гибридный подход, сочетающий в себе заданные лингвистические правила и векторные представления говорящих (speaker embeddings), позволяет модели не только воспроизводить акценты, явно заданные в правилах, но и обобщать полученные знания для генерации речи с новыми, не прописанными в явном виде, акцентными особенностями. Это достигается благодаря способности speaker embeddings кодировать тонкие нюансы произношения, которые модель может затем экстраполировать и применять к новым текстовым данным, формируя более реалистичные и разнообразные акценты. Фактически, модель способна «выучивать» паттерны акцентов, выходящие за рамки жестко заданных правил, что значительно расширяет возможности синтеза речи.
Оценка Контроля Акцента: Новый Показатель
В рамках оценки контроля над акцентом представлен новый показатель — «Коэффициент сдвига фонем» (Phoneme Shift Rate). Данный коэффициент позволяет количественно оценить, в какой степени правила преобразования фонем соблюдаются или, напротив, переопределяются векторами представления говорящего (speaker embeddings). По сути, он измеряет баланс между заранее заданными лингвистическими правилами и индивидуальными особенностями произношения, закодированными в векторах. Высокий коэффициент указывает на преобладание влияния speaker embeddings и, как следствие, на большую степень сохранения исходного акцента, в то время как низкий коэффициент свидетельствует о более сильном воздействии правил и, следовательно, об активном изменении акцента. Использование данного показателя позволяет более точно оценить эффективность алгоритмов модификации акцента и найти оптимальный баланс между сохранением естественности речи и достижением желаемого акцента.
Исследования показали значительное снижение вероятности североамериканского акцента с 86,5% до 58,8% при использовании разработанных правил в сочетании со speaker embeddings. Одновременно с этим, наблюдалось существенное улучшение соответствия британскому акценту, показатель которого изменился с -0,05 до 0,21. Эти результаты демонстрируют эффективность предложенного подхода в модификации акцентов, позволяя добиться более нейтрального произношения или, наоборот, приблизить его к целевому акценту с высокой степенью точности и сохранением естественности речи.
Показатель сдвига фонем, изначально составлявший 0.775, был успешно снижен до 0.628 благодаря применению разработанных правил. Данное снижение свидетельствует о достижении более гармоничного баланса между модификацией акцента, основанной на лингвистических правилах, и той, что обусловлена характеристиками говорящего, заложенными в векторных представлениях. По сути, предложенный подход позволяет не просто механически изменять произношение, но и учитывать индивидуальные особенности речи, сохраняя естественность звучания и избегая чрезмерной искусственности. Такое сочетание обеспечивает более тонкую и реалистичную трансформацию акцента, приближая синтезированную речь к образцу, сохраняя при этом узнаваемые черты голоса говорящего.
Для оценки естественности синтезированной речи использовалась метрика UTMOS, позволяющая судить о восприятии звучания человеком. Результаты показали, что даже после трансформации акцента, речь сохраняет высокий уровень естественности — 4.4 для североамериканского акцента и 3.7 для британского. Сохранение этих показателей указывает на то, что предложенные методы изменения акцента не приводят к заметной деградации качества звука и обеспечивают сохранение его реалистичности для слушателя, что является важным фактором для практического применения технологии синтеза речи.
Исследование взаимодействия между характеристиками говорящего и фонологическими правилами в синтезе речи с акцентом подтверждает давнюю истину: системы редко подчиняются строгим предписаниям. Подобно тому, как невозможно предсказать все последствия архитектурного решения, невозможно полностью контролировать нюансы акцента, используя лишь математические модели. Бертранд Рассел некогда заметил: «Чем больше я узнаю людей, тем больше я люблю собак». Эта фраза, хоть и кажется отвлеченной, отражает суть работы: попытка свести сложность человеческой речи к набору параметров всегда будет компромиссом. Управление акцентом, как и любое проектирование систем, требует признания непредсказуемости и принятия неизбежных несовершенств. Истинная сила заключается не в контроле, а в умении адаптироваться к возникающим отклонениям, подобно тому, как фонологические правила, взаимодействуя с характеристиками говорящего, создают уникальный лингвистический отпечаток.
Что дальше?
Исследование взаимодействия векторных представлений говорящих и фонологических правил, предпринятое в данной работе, скорее всего, лишь открывает ящик Пандоры. Стремление к «контролю» над акцентом в синтезе речи — это, по сути, попытка обуздать поток, заставить язык подчиняться заранее заданным рамкам. Каждый рефакторинг, каждая попытка «дизъюнкции» характеристик акцента, начинается как молитва о предсказуемости и заканчивается покаянием перед лицом неминуемой энтропии. Недостаточно просто «классифицировать» акценты; необходимо понимать их эволюцию, их внутреннюю логику, которая, несомненно, ускользает от любых формальных моделей.
Настоящая проблема заключается не в манипулировании фонетическими сдвигами, а в создании систем, способных к адаптации и самоорганизации. Представление об акценте как о статичном наборе правил — это иллюзия. Акцент живет и дышит, меняется со временем, под влиянием внешних факторов и внутренних потребностей говорящего. Более перспективным представляется отказ от жесткого контроля в пользу эмерджентных свойств, позволяющих системе «выращивать» акцент, а не навязывать его.
Система, способная к истинному синтезу речи, должна быть не инструментом, а экосистемой. Она должна учиться на ошибках, адаптироваться к новым данным, и позволять акценту эволюционировать естественным образом. И тогда, возможно, она перестанет звучать как машина и начнет говорить на языке жизни. Не стоит забывать: каждая попытка упростить — это пророчество о будущей нестабильности.
Оригинал статьи: https://arxiv.org/pdf/2601.14417.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые нейросети на службе нефтегазовых месторождений
- Квантовые прорывы: Хорошее, плохое и смешное
- Квантовая криптография: от теории к практике
- Квантовые вычисления: от шифрования армагеддона до диверсантов космических лучей — что дальше?
- Робот, который видит, понимает и действует: новая эра общего назначения
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Квантовые сети для моделирования молекул: новый подход
- Лунный гелий-3: Охлаждение квантового будущего
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Квантовые симуляторы: точное вычисление энергии основного состояния
2026-01-22 12:48