Автор: Денис Аветисян
В статье предлагается новый подход к идентификации алгоритмов, позволяющий обеспечить их прослеживаемость и ответственность.
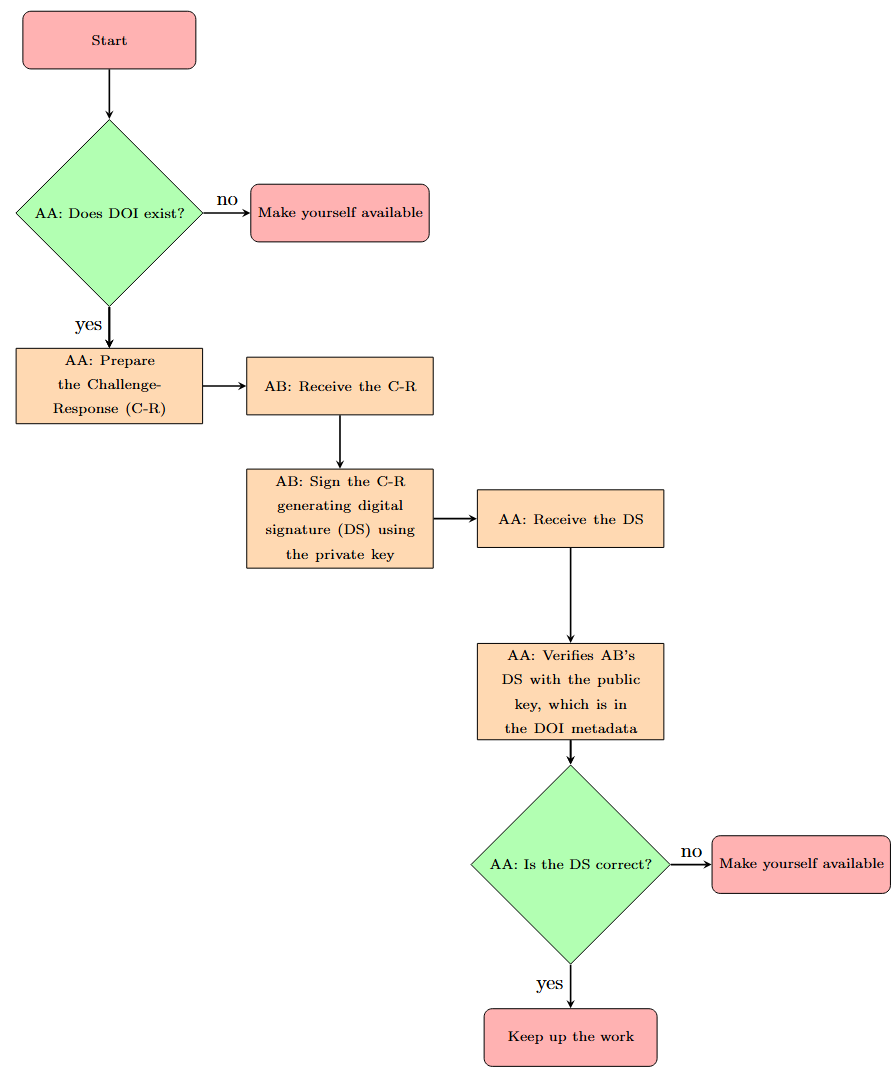
Использование цифровых идентификаторов (DOI) для однозначной идентификации алгоритмов и обеспечения прозрачности в сфере искусственного интеллекта.
Растущее применение алгоритмов в критически важных областях, от здравоохранения до финансов, порождает серьезные вопросы ответственности и прозрачности. В данной работе, ‘Algorithmic Identity Based on Metaparameters: A Path to Reliability, Auditability, and Traceability’, рассматривается возможность использования цифровых идентификаторов объектов (DOI) для уникальной идентификации алгоритмов и связывания их с ключевыми метаданными. Предлагаемый подход призван обеспечить отслеживаемость происхождения алгоритмов, облегчить аудит и повысить надежность их применения, особенно в контексте искусственного интеллекта и больших языковых моделей. Способно ли внедрение DOI стать основой для создания действительно прозрачной и ответственной системы разработки и использования алгоритмов?
Алгоритмическая Ответственность: Вызов Эпохи ИИ
Растущее распространение систем искусственного интеллекта ставит перед обществом сложную задачу: обеспечение ответственности за их действия и результаты. По мере того, как алгоритмы проникают во все сферы жизни — от принятия финансовых решений до здравоохранения и правосудия — возрастает необходимость в четком понимании того, кто несет ответственность в случае ошибок или нежелательных последствий. Это не просто вопрос этики, но и юридической ответственности, требующей разработки новых механизмов для отслеживания, аудита и объяснения решений, принимаемых искусственным интеллектом. Отсутствие такой системы может привести к подрыву доверия к технологиям, затруднить регулирование и создать возможности для злоупотреблений, что подчеркивает важность поиска эффективных решений в области алгоритмической подотчетности.
Современные методы идентификации алгоритмов оказываются недостаточными для отслеживания их сложной эволюции. Существующие системы часто не способны фиксировать детали конкретных моделей, а также изменения, вносимые в них на разных этапах разработки и эксплуатации. Это приводит к тому, что становится сложно установить происхождение конкретного результата, понять, какие именно параметры алгоритма повлияли на принятое решение, и, как следствие, обеспечить необходимый уровень контроля и ответственности. Отсутствие детальной и устойчивой идентификации алгоритмов создает значительные препятствия для эффективного регулирования в сфере искусственного интеллекта и повышает риски, связанные с возможным злоупотреблением или непредвиденными последствиями.
Непрозрачность алгоритмов создает серьезные препятствия для формирования доверия к системам искусственного интеллекта. Отсутствие четкой идентификации и отслеживания изменений в моделях затрудняет соблюдение нормативных требований и усложняет процесс аудита. Более того, данная неопределенность формирует благоприятную среду для злоумышленников, которые могут использовать уязвимости в алгоритмах для манипулирования данными или совершения других вредоносных действий. Эта скрытность подрывает стабильность и надежность систем, требуя разработки эффективных механизмов обеспечения прозрачности и подотчетности в сфере искусственного интеллекта.
Создание надежной системы идентификации алгоритмов представляется ключевым фактором для ответственной разработки и внедрения искусственного интеллекта. Отсутствие четкой и устойчивой идентификации затрудняет отслеживание изменений в моделях, что препятствует эффективному аудиту и контролю. Это, в свою очередь, снижает доверие к системам ИИ, усложняет соблюдение нормативных требований и создает уязвимости для злоумышленников. Разработка механизмов, позволяющих однозначно идентифицировать алгоритмы на протяжении всего их жизненного цикла — от создания до обновления и вывода из эксплуатации — является необходимым условием для обеспечения прозрачности, подотчетности и безопасности в сфере искусственного интеллекта, а также для стимулирования инноваций и общественного доверия к этой перспективной технологии.
Таксономия Алгоритмов: Уникальный След в Коде
Предлагается иерархическая таксономия для идентификации алгоритмов, в основе которой лежит Digital Object Identifier (DOI). Эта таксономия обеспечивает уникальную и постоянную идентификацию каждого алгоритма, позволяя отслеживать его эволюцию и различные реализации. Использование DOI в качестве основного идентификатора гарантирует разрешимость и возможность однозначной ссылки на конкретный алгоритм, его исходный код и обученные модели. Такой подход позволяет создать надежную систему учета и контроля версий алгоритмов, что критически важно для обеспечения воспроизводимости результатов и долгосрочного сохранения алгоритмических решений.
Предлагаемая таксономия алгоритмов состоит из трех уровней, отражающих полный жизненный цикл алгоритма. Первый уровень — Алгоритмическая Логика, представляющая собой абстрактное описание принципов работы алгоритма, независимо от конкретной реализации. Второй уровень — Эталонная Реализация, включающая исходный код, который конкретизирует алгоритмическую логику. Наконец, третий уровень — Обученные Модели, являющиеся результатом применения эталонной реализации к данным и представляющие собой артефакты, готовые к использованию. Каждый из этих уровней рассматривается как самостоятельная сущность, что позволяет отслеживать изменения и зависимости между ними.
Каждому уровню таксономии — абстрактной логике алгоритма, эталонной реализации (исходному коду) и обученным моделям — присваивается уникальный цифровой идентификатор объекта (DOI). Это позволяет обеспечить точное отслеживание изменений на каждом этапе жизненного цикла алгоритма и эффективно управлять версиями. Присвоение DOI каждому уровню обеспечивает возможность однозначной идентификации и верификации конкретной версии алгоритма, его реализации и полученных моделей, что критически важно для воспроизводимости результатов и обеспечения целостности данных. Такая система позволяет отслеживать эволюцию алгоритма от первоначальной концепции до финальной, развернутой модели, фиксируя все промежуточные изменения и обеспечивая полную прослеживаемость.
Предлагаемый подход выходит за рамки простого версионирования моделей, обеспечивая полную прослеживаемость всех этапов жизненного цикла алгоритма. Традиционное версионирование фокусируется исключительно на обученных моделях, в то время как данная система отслеживает не только артефакты, но и лежащую в их основе логику алгоритма, а также конкретную реализацию исходного кода. Каждому из этих уровней — абстрактной концепции, эталонной реализации и обученной модели — присваивается уникальный DOI, что позволяет точно фиксировать изменения и поддерживать контроль версий на протяжении всего жизненного цикла алгоритма, от первоначальной идеи до конечного продукта.
Метаданные и Аутентификация: Прозрачность и Доверие
Предлагаемая система включает в себя расширенные метаданные, обеспечивающие полную прослеживаемость и верификацию алгоритмов. В частности, предоставляются ссылки на используемые наборы обучающих данных, позволяющие оценить качество и предвзятость модели. Также, в метаданные включены отчеты об этическом соответствии, документирующие оценку алгоритма на предмет соответствия этическим нормам и принципам. Идентификатор программного наследия (SWHID) обеспечивает уникальную и неизменяемую идентификацию конкретной версии программного обеспечения, гарантируя целостность и возможность воспроизведения результатов. Совокупность этих метаданных позволяет осуществлять аудит алгоритма на всех этапах его жизненного цикла.
Для обеспечения подлинности алгоритмов и предотвращения злонамеренных изменений предложена система аутентификации, основанная на инфраструктуре DOI. Каждому алгоритму присваивается уникальный DOI, что позволяет однозначно идентифицировать его версию и историю изменений. Протокол аутентификации использует криптографические хеш-функции для создания цифровой подписи, привязанной к DOI и коду алгоритма. Любая модификация кода приведет к изменению хеш-значения и, следовательно, к недействительности подписи, что позволит оперативно выявлять несанкционированные изменения и гарантировать целостность алгоритма. Эта система обеспечивает возможность проверки подлинности алгоритма любым заинтересованным лицом, используя общедоступную инфраструктуру DOI.
Семантическое версионирование позволяет отслеживать инкрементальные изменения алгоритмов без присвоения им новых идентификаторов DOI. Вместо создания новых DOI для каждой модификации, система использует структуру версионирования MAJOR.MINOR.PATCH, где MAJOR указывает на несовместимые изменения API, MINOR — на добавление функциональности, обратно совместимой, а PATCH — на исправления ошибок, также обратно совместимые. Такой подход упрощает управление версиями, облегчает отслеживание эволюции алгоритма и снижает административные издержки, связанные с поддержанием большого количества DOI.
“Объяснимость для граждан” представляет собой краткое, нетехническое описание назначения и потенциального влияния алгоритма, предназначенное для широкой общественности. Этот документ, разработанный для обеспечения прозрачности и подотчетности, содержит информацию о том, как алгоритм функционирует, какие данные он использует, и какие последствия его применение может иметь для различных групп населения. Основная цель — предоставить доступное объяснение, позволяющее гражданам понимать принципы работы алгоритма и оценивать его социальную значимость, не требуя специальных технических знаний. Публикация таких сводок способствует укреплению доверия к автоматизированным системам и повышению осведомленности о потенциальных рисках и преимуществах, связанных с их использованием.
Ответственный ИИ: Минимизация Рисков и Обеспечение Прозрачности
Для эффективной борьбы с такими явлениями, как «промывка моделей» (Model Washing) и поддержания целостности распределенных алгоритмов, необходима их уникальная идентификация и отслеживание. Данный подход позволяет установить происхождение конкретной модели, выявить несанкционированные изменения и обеспечить возможность проверки её поведения. Отслеживание алгоритмов по уникальным идентификаторам создает надежный механизм контроля, препятствующий подмене или искажению моделей, что особенно важно в контексте быстрого распространения и повторного использования алгоритмов в различных приложениях. Это позволяет гарантировать, что используемая модель соответствует заявленным характеристикам и не подвергалась злонамеренным манипуляциям, обеспечивая тем самым надежность и предсказуемость её работы.
Система, основанная на цифровых идентификаторах объектов (DOI), создает важнейшую цепочку отслеживания, позволяющую проводить расследования случаев предвзятости алгоритмов и несправедливых результатов. Каждый алгоритм, получивший DOI, приобретает уникальный и постоянный идентификатор, что позволяет исследователям и регулирующим органам проследить его происхождение, изменения и применение. Такой подход обеспечивает возможность проверки алгоритма на различных этапах его жизненного цикла, выявляя потенциальные источники предвзятости, будь то данные, используемые для обучения, или логика, заложенная в сам алгоритм. Благодаря этой прозрачности, становится возможным более эффективно бороться с дискриминацией и несправедливостью, возникающими в результате использования искусственного интеллекта, и обеспечивать более справедливые и ответственные решения.
Предлагаемая система способствует достижению так называемой «Квалифицированной Прозрачности», позволяя заинтересованным сторонам — от разработчиков до конечных пользователей и регулирующих органов — получить глубокое понимание логики работы алгоритмов и их потенциального влияния. В отличие от полной прозрачности, которая может быть невозможна или нежелательна из-за соображений коммерческой тайны или интеллектуальной собственности, квалифицированная прозрачность предлагает сбалансированный подход. Она обеспечивает доступ к ключевой информации, необходимой для оценки справедливости, надежности и соответствия алгоритмов установленным нормам, при этом сохраняя конфиденциальность критически важных деталей. Это достигается за счет структурированного представления данных о разработке, обучении и применении алгоритма, что позволяет проводить независимую оценку и выявлять потенциальные риски или предубеждения, влияющие на результаты его работы. Такой подход не только способствует повышению доверия к искусственному интеллекту, но и стимулирует ответственное развитие и внедрение инновационных технологий.
Предлагаемый подход направлен на гармонизацию растущей силы алгоритмов с принципами демократичной прозрачности, что является ключевым фактором для укрепления общественного доверия и содействия ответственному развитию искусственного интеллекта. Суть заключается в создании системы, где алгоритмические решения не являются «черным ящиком», а поддаются осмыслению и проверке со стороны заинтересованных сторон. Такое сочетание мощности вычислений и открытости способствует не только повышению надежности и справедливости алгоритмов, но и формированию более осознанного и ответственного подхода к их использованию в различных сферах жизни, от здравоохранения до образования и правосудия. Подобная прозрачность позволяет обществу понимать логику, лежащую в основе автоматизированных решений, и эффективно контролировать их влияние, тем самым обеспечивая соответствие алгоритмов общественным ценностям и нормам.
Будущее Алгоритмической Подотчетности: Инфраструктура для Доверия
Внедрение DOI-системы для отслеживания интерфейсов прикладного программирования (API) обеспечивает беспрецедентный уровень контроля версий и ответственности за критически важные программные компоненты. Эта система позволяет однозначно идентифицировать каждую версию API, подобно тому, как DOI идентифицирует научные публикации, что позволяет отслеживать изменения, воспроизводить результаты и оперативно выявлять источник ошибок или уязвимостей. По сути, каждый вызов API становится аудируемым, что крайне важно для приложений, где точность и надежность имеют первостепенное значение, например, в здравоохранении, финансах и автономных системах. Такой подход не только упрощает отладку и обслуживание, но и закладывает основу для доверия к алгоритмам и системам, основанным на этих интерфейсах.
Для эффективного управления непредсказуемым поведением автономных агентов и установления ответственности за их действия, необходима надежная система идентификации. Отслеживание таких агентов становится критически важным, поскольку их самостоятельные решения могут приводить к непредсказуемым последствиям. Эта система должна обеспечивать возможность установления связи между конкретным действием агента и его создателем или оператором, что позволяет оперативно реагировать на возникающие проблемы и предотвращать потенциальный ущерб. Разработка подобных механизмов идентификации — это не только техническая задача, но и необходимый шаг к построению доверия к автономным системам и обеспечению их безопасного внедрения в различные сферы жизни. Без четкой идентификации и возможности отслеживания, эффективное регулирование и контроль над автономными агентами становится практически невозможным.
Предложенная таксономия представляет собой гибкую основу, способную адаптироваться к быстро меняющимся архитектурам и технологиям искусственного интеллекта. В отличие от жестких, статичных систем классификации, данная структура построена по модульному принципу, что позволяет легко включать новые типы агентов и алгоритмов по мере их появления. Такая адаптивность критически важна, учитывая экспоненциальный рост инноваций в области ИИ, и обеспечивает долгосрочную применимость таксономии для отслеживания и управления автономными системами. Более того, гибкость структуры позволяет учитывать различные уровни абстракции, от отдельных компонентов до сложных, интегрированных систем, предоставляя целостное представление об искусственном интеллекте и способствуя более эффективному управлению рисками и обеспечению ответственности.
Предлагаемый подход выходит за рамки чисто технического решения, представляя собой фундаментальный шаг к созданию будущего, где алгоритмы являются прозрачными, ответственными и соответствуют человеческим ценностям. Обеспечение отслеживаемости и идентификации автономных агентов — это не просто вопрос управления непредсказуемым поведением, но и залог возможности привлечения к ответственности за их действия. В конечном итоге, такая система позволяет перейти от «черных ящиков» к алгоритмам, функционирование которых можно понять, проверить и, при необходимости, скорректировать, что является необходимым условием для доверия к искусственному интеллекту и его успешной интеграции в различные сферы жизни общества. Разработка подобных механизмов контроля и отчетности — это инвестиция в будущее, где технологии служат интересам человечества, а не наоборот.
«`html
Наблюдатель, знакомый с проблемами внедрения новых технологий, отметил бы, что идея присвоения уникальных идентификаторов алгоритмам, как предлагается в данной работе, звучит разумно… пока не коснется вопросов практической реализации. Всё это напоминает попытку приручить хаос, надеясь, что метаданные и DOI смогут обеспечить прослеживаемость и ответственность. Как однажды заметил Дональд Дэвис: «Простота — это конечная сложность». В контексте алгоритмической идентификации это означает, что любая система, стремящаяся к полноте и точности метаданных, неизбежно столкнется с экспоненциальным ростом сложности. Продакшен, как всегда, найдет способ обойти эти идентификаторы, подменить метаданные или просто сломать систему, заставив вспомнить о необходимости постоянного мониторинга и адаптации.
Куда же это всё ведёт?
Предложение присваивать алгоритмам DOI — шаг, безусловно, логичный. Однако, не стоит обольщаться иллюзией мгновенного просветления. В конечном итоге, DOI — это просто указатель. Он укажет на метаданные, которые, в свою очередь, кто-то должен поддерживать в актуальном состоянии. А это, как известно, всегда требует ресурсов, времени и, главное, желания. Иначе DOI станет памятником благих намерений, а не инструментом реальной ответственности.
Более того, возникает вопрос масштабируемости. Количество алгоритмов растёт экспоненциально. Кто будет курировать эту «алгоритмическую номенклатуру»? Какие критерии будут использоваться для определения «значимости» алгоритма, заслуживающего DOI? Не превратится ли это в очередную бюрократическую процедуру, где «квалифицированная прозрачность» станет синонимом «дорогих способов всё усложнить»?
Вполне вероятно, что настоящая ценность этой работы проявится не в самом факте присвоения DOI, а в стимулировании дискуссии о том, что вообще значит «идентифицировать» алгоритм. Ведь код, который выглядит идеально — значит, его ещё никто не деплоил. А когда алгоритм начнёт принимать решения, влияющие на жизни людей, вопрос его «происхождения» станет куда более сложным, чем просто запись в реестре DOI.
Оригинал статьи: https://arxiv.org/pdf/2601.16234.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Кванты в Финансах: Не Шутка!
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Ранжирование с умом: новый подход к предсказанию кликов
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
2026-01-26 17:50