Автор: Денис Аветисян
Новая архитектура Canon позволяет эффективно распределять вычислительные ресурсы и адаптироваться к различным типам задач, особенно тем, которые характеризуются нерегулярными данными.
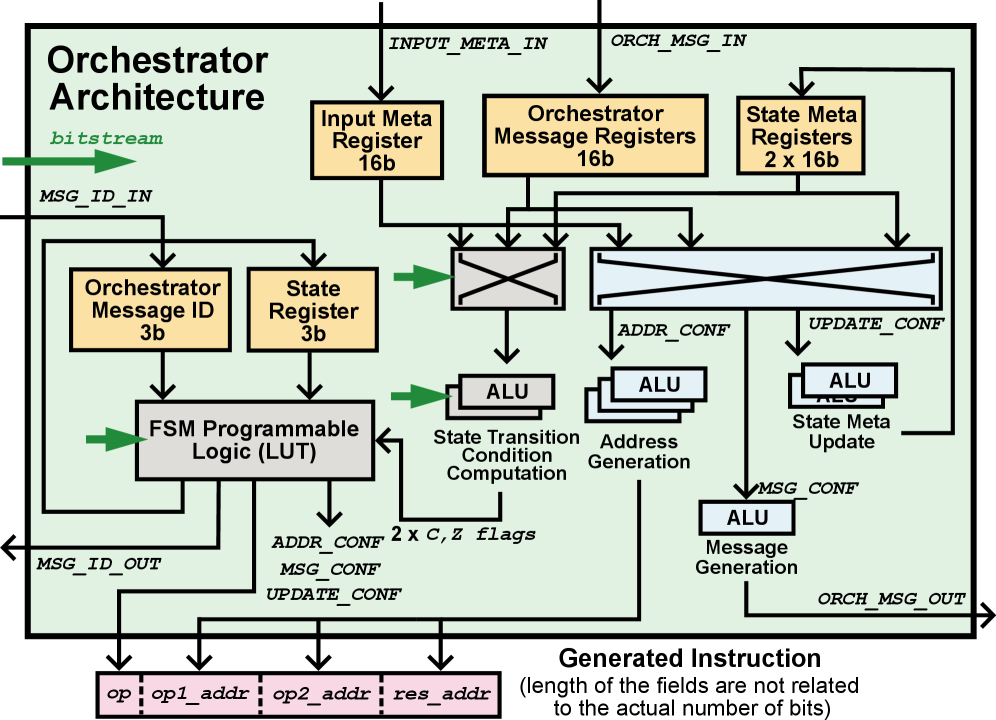
Представлена архитектура, объединяющая компиляцию и динамическое управление, использующая модель Time-Lapsed SIMD для повышения эффективности и устойчивости к неравномерной нагрузке.
Специализированные аппаратные ускорители обеспечивают высокую производительность, но демонстрируют хрупкость при обработке новых или нерегулярных данных, в то время как программируемые архитектуры уступают им в эффективности. В данной работе, посвященной ‘A Data-Driven Dynamic Execution Orchestration Architecture’, представлена Canon — параллельная архитектура, объединяющая компиляционное и динамическое оркестрование с использованием модели SIMD с задержкой по времени. Это позволяет достичь высокой производительности и энергоэффективности, сравнимой со специализированными ускорителями, сохраняя при этом гибкость, присущую программируемым платформам. Способна ли Canon стать основой для создания универсальных вычислительных систем, эффективно адаптирующихся к широкому спектру задач и форматов данных?
Пределы Традиционных Архитектур: Временная Перспектива
Несмотря на десятилетия оптимизации, традиционные архитектуры фон Неймана испытывают значительные трудности при обработке современных, требовательных к объему данных задач. Основная проблема заключается в так называемом «узком горлышке фон Неймана» — последовательном переносе данных между процессором и памятью. Постоянно растущие объемы информации, необходимые для анализа и обработки, приводят к тому, что скорость передачи данных становится ограничивающим фактором, существенно снижая общую производительность системы. В результате, даже самые мощные процессоры оказываются неспособны эффективно использовать свой вычислительный потенциал, поскольку большую часть времени тратят на ожидание данных, а не на их обработку. Данное ограничение особенно остро проявляется в таких областях, как машинное обучение, анализ больших данных и научное моделирование, где требуются огромные объемы данных и высокая скорость обработки.
В течение десятилетий, развитие вычислительной техники опиралось на два фундаментальных принципа — закон Мура и масштабирование Деннарда. Закон Мура предсказывал удвоение числа транзисторов на интегральной схеме каждые два года, обеспечивая экспоненциальный рост вычислительной мощности. Масштабирование Деннарда, в свою очередь, позволяло уменьшать энергопотребление при уменьшении размеров транзисторов, сохраняя при этом стабильную производительность. Однако, в последние годы оба этих закона замедлились. Уменьшение размеров транзисторов становится все более сложным и дорогим, а сохранение пропорционального снижения энергопотребления сталкивается с физическими ограничениями. Это приводит к формированию «бутылочного горлышка» в производительности, поскольку увеличение числа транзисторов не всегда ведет к соответствующему увеличению скорости вычислений. В результате, традиционные архитектуры компьютеров, основанные на этих принципах, испытывают трудности в обработке растущих объемов данных и выполнении сложных задач, что требует пересмотра устоявшихся парадигм проектирования и поиска новых подходов к созданию вычислительных систем.
Ограничения традиционных архитектур, вызванные замедлением масштабирования Деннарда и закона Мура, стимулируют поиск принципиально новых подходов к организации вычислительных систем. Исследования направлены на преодоление узких мест последовательной обработки данных и уменьшающегося прироста производительности от увеличения числа транзисторов. Разрабатываются архитектуры, использующие параллелизм на различных уровнях — от аппаратного обеспечения до алгоритмов — для эффективной обработки огромных объемов информации, характерных для современных задач, таких как машинное обучение и анализ больших данных. Цель этих инноваций — создание вычислительных систем, способных не только соответствовать растущим требованиям, но и открывать новые возможности в различных областях науки и техники.

Поток Данных: Новый Импульс Параллелизму
Архитектуры, основанные на потоке данных, в отличие от традиционных, ориентированных на последовательное выполнение инструкций, определяют порядок вычислений исходя из зависимостей между данными. Это позволяет автоматически выявлять и использовать возможности параллельного выполнения операций, поскольку задача запускается, когда доступны необходимые входные данные, а не в заранее определенной последовательности. Такой подход существенно снижает потребность в централизованном управлении и координации, поскольку выполнение определяется исключительно потоком данных, что приводит к повышению эффективности и масштабируемости вычислений.
Архитектура Canon представляет собой новую параллельную систему, развивающую принципы потоковой обработки данных. Она демонстрирует производительность, сопоставимую с специализированными ускорителями в их областях применения, однако в отличие от них, поддерживает более широкий спектр рабочих нагрузок. Достигается это за счет динамического распределения ресурсов и оптимизации выполнения задач на основе зависимостей между данными, что позволяет эффективно использовать доступные вычислительные мощности для различных типов приложений, включая те, которые не оптимальны для традиционных ускорителей.
Архитектура Canon обеспечивает эффективное выполнение разнообразных рабочих нагрузок за счет разделения управления и вычислений. В отличие от традиционных архитектур, где последовательность инструкций жестко задана, Canon позволяет вычислениям выполняться как только доступны необходимые данные, независимо от порядка их определения в программе. Это разделение позволяет системе динамически распределять вычислительные ресурсы и избегать простоев, характерных для последовательного выполнения. В результате, Canon эффективно использует преимущества параллельной обработки, максимизируя пропускную способность и снижая задержки при выполнении широкого спектра задач, включая как специализированные, так и общие вычислительные нагрузки.
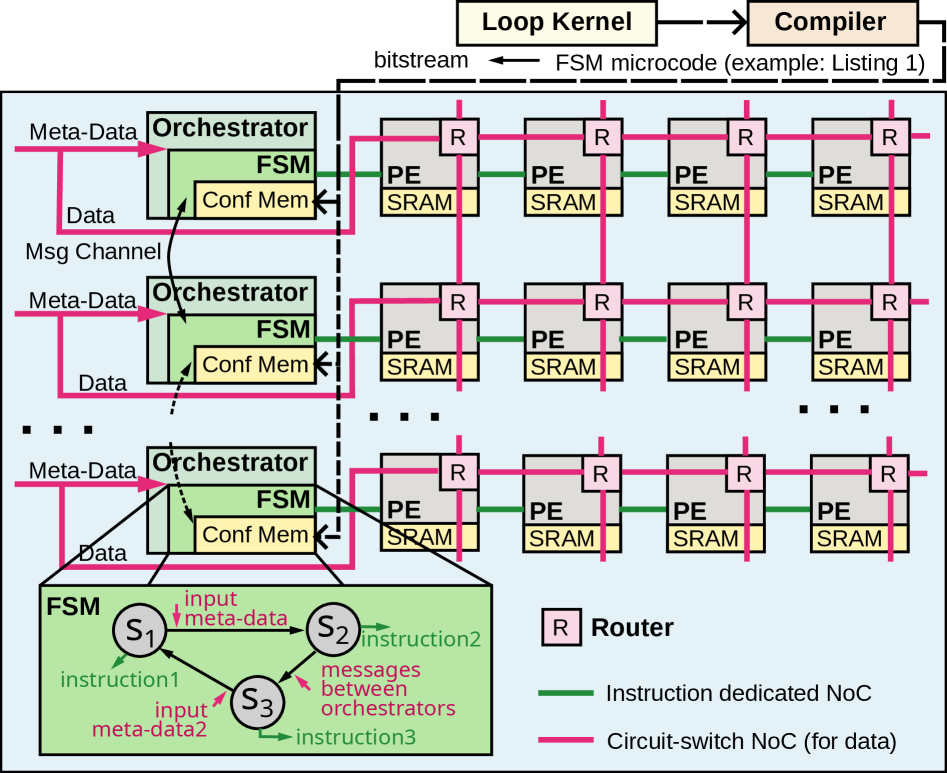
Разреженность Данных: Эффективность в Деталях
В современных реальных наборах данных часто наблюдается значительная разреженность, то есть большая доля элементов представляет собой нули. Это явление особенно характерно для задач обработки естественного языка (например, one-hot encoding векторов слов), рекомендательных систем (где пользователи взаимодействуют лишь с малой частью доступных элементов) и компьютерного зрения (например, изображения с преобладающим фоном). Высокая разреженность позволяет оптимизировать хранение и обработку данных, поскольку нет необходимости хранить и учитывать нулевые значения при вычислениях. Уровень разреженности может существенно варьироваться в зависимости от конкретного набора данных и области применения, но часто превышает 60-80%, что делает оптимизацию разреженных данных критически важной для повышения производительности и снижения потребления ресурсов.
Операции над разреженными тензорами могут быть значительно ускорены за счет использования специализированного аппаратного обеспечения, разработанного для пропуска вычислений с нулевыми элементами. Традиционные вычислительные архитектуры выполняют операции над всеми элементами тензора, независимо от их значения, что приводит к избыточным вычислениям и потреблению энергии. Аппаратные ускорители для разреженных тензоров используют различные методы, такие как сжатие данных и оптимизированные схемы доступа к памяти, для эффективной обработки только ненулевых элементов. Это позволяет снизить вычислительную сложность и энергопотребление, особенно для больших разреженных наборов данных, широко распространенных в областях машинного обучения и анализа данных.
Комбинация архитектуры Canon, специализированных ускорителей для работы с разреженными данными и систолических массивов обеспечивает эффективную обработку разреженных представлений данных. Тестирование показало, что при оптимизированном размере промежуточной памяти (scratchpad) достигается прирост производительности в диапазоне 10-20% для рабочих нагрузок с уровнем разреженности 60% и выше. Данная схема позволяет обходить ненужные вычисления над нулевыми элементами, что существенно повышает эффективность использования вычислительных ресурсов.
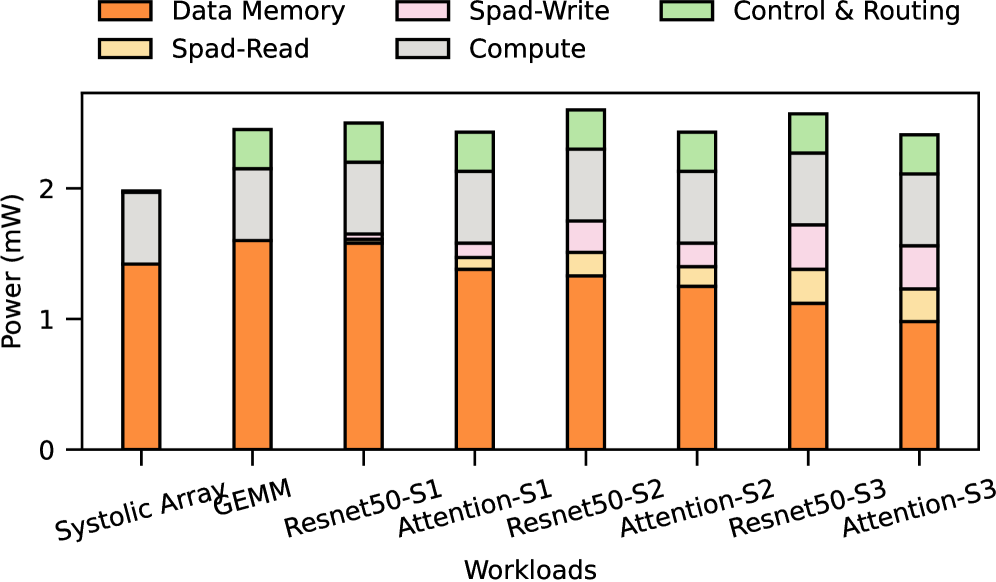
Системная Интеграция: Гармония Высокой Производительности
Для обеспечения максимальной производительности специализированного процессора Canon критически важна высокоскоростная память, такая как LPDDR5X. Системные массивы, составляющие основу вычислительной мощности данной архитектуры, требуют непрерывного и оперативного доступа к большим объемам данных. LPDDR5X, благодаря своей высокой пропускной способности и низкой задержке, позволяет эффективно «насыщать» эти массивы информацией, предотвращая возникновение «узких мест» и обеспечивая стабильную работу даже при выполнении сложных задач. Недостаточная скорость памяти привела бы к простоям вычислительных блоков, значительно снижая общую эффективность системы и ограничивая ее потенциал в области обработки данных.
В архитектуре Canon используется коммутируемая по цепям сеть-на-чипе (NoC), что обеспечивает выделенные каналы связи между вычислительными блоками. В отличие от пакетно-коммутируемых сетей, где данные разбиваются на пакеты и передаются по общим ресурсам, коммутируемая по цепям NoC устанавливает прямое, физически выделенное соединение между отправителем и получателем. Это значительно снижает задержки, поскольку исключается необходимость маршрутизации и арбитража, а также максимизирует пропускную способность, позволяя передавать данные с максимальной скоростью. Такой подход особенно важен для высокопроизводительных вычислений, где минимизация задержек и обеспечение высокой пропускной способности являются критическими факторами для достижения оптимальной производительности системы.
Интеграция энергонезависимой памяти Scratchpad и механизма управления, основанного на данных, значительно оптимизирует доступ к информации и последовательность выполнения операций в системе. Такой подход позволяет сократить время задержки и повысить пропускную способность обработки данных по сравнению с традиционными систолическими массивами. Несмотря на то, что внедрение данной системы влечет за собой увеличение занимаемой площади на 30%, повышение эффективности вычислений и снижение энергопотребления оправдывают данное удорожание. Эффективное управление потоком данных, обеспечиваемое Scratchpad Memory, позволяет минимизировать обращения к внешней памяти, а Data-Driven Control динамически адаптирует процесс обработки данных к текущим условиям, обеспечивая максимальную производительность.

Будущие Направления: Эволюция Архитектурной Адаптивности
Модульная конструкция архитектуры Canon предполагает возможность интеграции с массивами грубозернистой реконфигурируемой логики, что открывает путь к адаптации системы под широкий спектр вычислительных задач. Такой подход позволяет динамически перестраивать аппаратную конфигурацию в зависимости от требований конкретного приложения, эффективно используя ресурсы и избегая ограничений фиксированной архитектуры. В отличие от традиционных систем, где изменение функциональности требует полной замены аппаратного обеспечения, Canon, благодаря взаимодействию с массивами грубозернистой реконфигурации, может гибко подстраиваться под изменяющиеся нагрузки и новые алгоритмы, обеспечивая долгосрочную актуальность и экономическую эффективность. Это особенно важно для облачных вычислений, систем искусственного интеллекта и других областей, где требования к производительности и энергоэффективности постоянно растут.
В архитектуре Canon управление ресурсами и снижение накладных расходов достигаются за счет интеграции принципов временных задержек SIMD и конечного автомата. Временные задержки SIMD позволяют выполнять несколько операций над данными параллельно, но с возможностью отсрочки выполнения некоторых из них до момента, когда это наиболее эффективно с точки зрения энергопотребления и использования ресурсов. Конечный автомат, в свою очередь, обеспечивает предсказуемое и контролируемое выполнение задач, минимизируя неэффективные переключения контекста и оптимизируя последовательность операций. Такое сочетание позволяет Canon динамически адаптироваться к требованиям различных приложений, избегая избыточного использования ресурсов и поддерживая высокую производительность даже при ограниченных вычислительных возможностях.
Архитектура Canon, опираясь на принципы потоковой обработки данных и акцентируя внимание на разреженности вычислений, предлагает перспективный путь к устойчивому увеличению производительности. В отличие от традиционных подходов, где масштабирование становится все менее эффективным, данная конструкция позволяет оптимизировать использование ресурсов за счет обработки данных непосредственно по мере их поступления и минимизации избыточных операций. Такой подход особенно важен в контексте современных вычислительных задач, характеризующихся огромными объемами данных и сложностью алгоритмов. Приоритет разреженности, то есть концентрация вычислений на значимых данных, позволяет снизить энергопотребление и ускорить обработку информации, обеспечивая долгосрочную перспективу развития вычислительных систем, не зависящую от физических ограничений масштабирования.
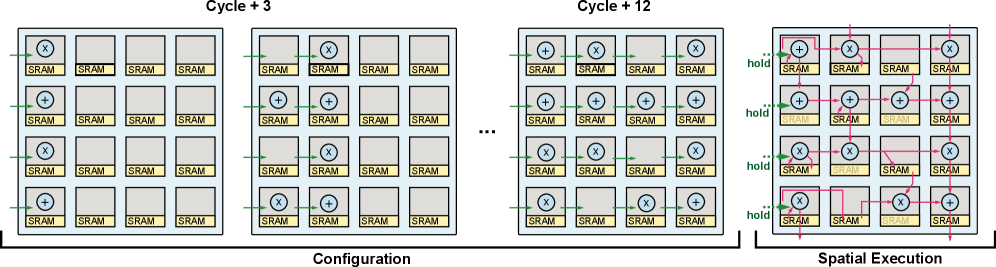
Архитектура Canon, представленная в данной работе, стремится к преодолению хрупкости производительности, присущей многим параллельным системам. Она комбинирует статическое и динамическое управление, адаптируясь к особенностям входных данных и обеспечивая высокую эффективность. Этот подход особенно важен для задач с нерегулярными паттернами данных, где традиционные методы могут давать сбой. Как однажды заметил Линус Торвальдс: «Плохой дизайн, плохие компромиссы и плохие решения — это просто признаки эволюции». Canon, в сущности, воплощает эту идею, постоянно адаптируясь и совершенствуясь, чтобы обеспечить оптимальную производительность в постоянно меняющейся среде вычислений. Система, подобно живому организму, развивается, приспосабливаясь к вызовам времени и данных.
Что дальше?
Представленная работа, исследуя динамическую оркестровку исполнения, лишь обозначает горизонт, а не его предел. Архитектура Canon, стремясь к устойчивости перед лицом нерегулярных данных, сталкивается с неизбежной истиной: любая система, даже тщательно спроектированная, подвержена энтропии. Оптимизация для текущего набора рабочих нагрузок — это лишь временное состояние, иллюзия стабильности, кэшированная временем. Вопрос не в достижении абсолютной производительности, а в элегантности деградации.
Особое внимание заслуживает проблема балансировки рабочей нагрузки в условиях постоянно меняющихся потоков данных. Распределенное исполнение, несмотря на свою привлекательность, неизбежно наталкивается на задержки — плату за каждый запрос, налог, который уплачивает любая параллельная система. Дальнейшие исследования должны быть направлены на разработку адаптивных стратегий оркестровки, способных предвидеть и смягчать дисбаланс, а также минимизировать накладные расходы, связанные с динамической реконфигурацией.
В конечном итоге, задача состоит не в создании идеальной архитектуры, а в построении систем, способных достойно стареть. Поиск компромисса между производительностью, энергоэффективностью и гибкостью — это непрерывный процесс, определяемый не абсолютными метриками, а средой, в которой эти системы существуют.
Оригинал статьи: https://arxiv.org/pdf/2602.17119.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Предел возможностей: где большие языковые модели теряют разум?
- Улучшение точности квантовых сенсоров: новый подход к подавлению шумов
- Резонансы в тандеме: Управление светом в микрорезонаторах
- Квантовый шум: за пределами стандартных моделей
- Виртуальная примерка без границ: EVTAR учится у образов
- Искусственный разум и квантовые данные: новый подход к синтезу табличных данных
- Моделирование спектроскопии электронного пучка: новый подход
- Квантовое программирование: Карта развивающегося мира
- За пределами стандартной точности: новая структура эффективной теории
- Сердце музыки: открытые модели для создания композиций
2026-02-21 10:09