Направляя Искусственный Интеллект: Как Примерные Ответы Улучшают Обучение
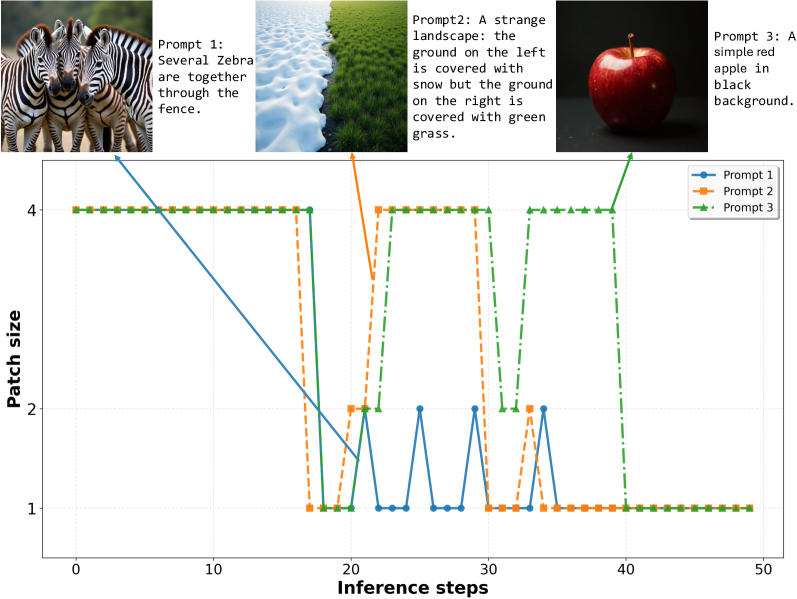
![Исследование демонстрирует, что использование эталонных данных в качестве руководства для оценки больших языковых моделей (LLM) не только повышает среднюю точность ([latex]\S 3.3[/latex]), но и способствует их самосовершенствованию ([latex]\S 4[/latex]), раскрывая потенциал для создания более надежных и согласованных систем.](https://arxiv.org/html/2602.16802v1/x1.png)
Новое исследование показывает, что использование высококачественных эталонных ответов может значительно повысить точность и соответствие моделей искусственного интеллекта заданным критериям.