Нейросети на службе причинности: новый подход к поиску связей
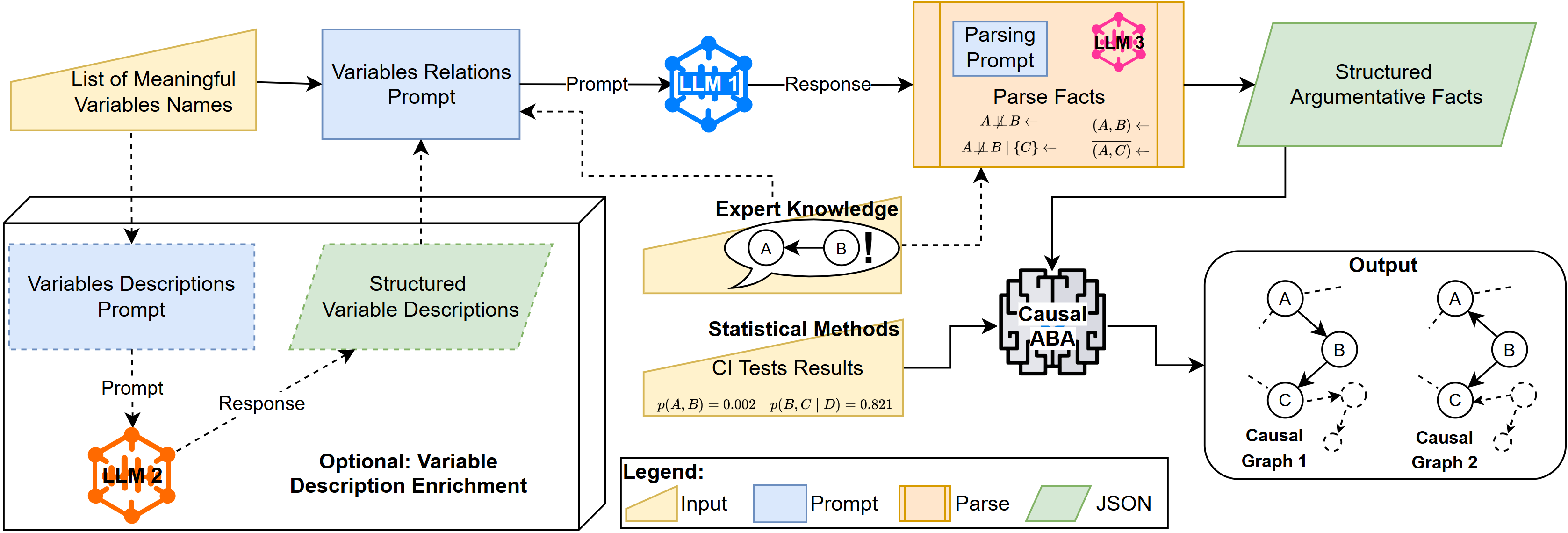
Исследователи предлагают инновационный метод, использующий мощь больших языковых моделей для выявления причинно-следственных связей в данных.
Исследователи предлагают инновационный метод, использующий мощь больших языковых моделей для выявления причинно-следственных связей в данных.
Исследователи представили модель SAM 3D Body, позволяющую с высокой точностью восстанавливать трехмерную модель человека по заданным подсказкам.
Появление автономных систем искусственного интеллекта в здравоохранении ставит под вопрос традиционные моральные принципы и меняет взаимоотношения между врачом и пациентом.
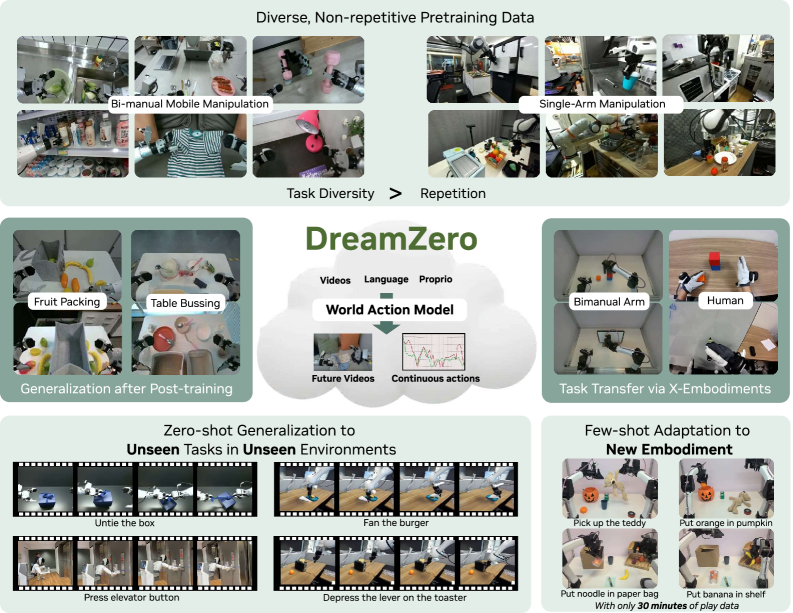
Новая модель DreamZero позволяет роботам осваивать сложные задачи, используя лишь видеоданные и демонстрируя впечатляющую адаптивность к различным платформам.
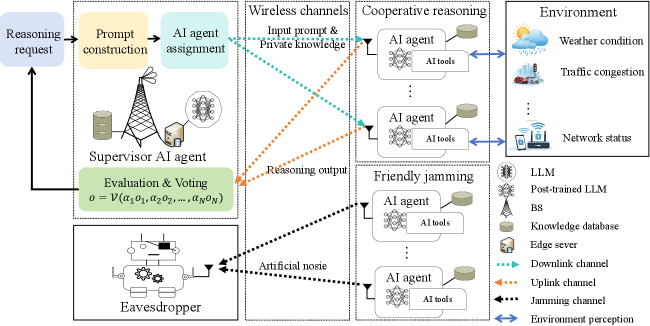
В статье рассматриваются новые подходы к организации беспроводных сетей, где интеллектуальные агенты совместно решают задачи, оптимизируя энергопотребление и обеспечивая надежную связь.
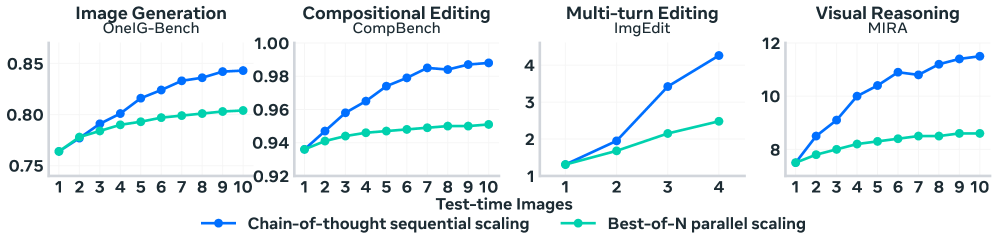
Исследователи предлагают инновационный подход, позволяющий моделям самостоятельно улучшать свои ответы, используя цепочку рассуждений и итеративную доработку.
![Предложенные решетчатые множества демонстрируют оптимальную скорость убывания радиуса разделения [latex]q(P_N)[/latex] как функцию от числа точек [latex]N[/latex], равную [latex]\Theta(N^{-1/d})[/latex], в то время как другие последовательности характеризуются более быстрым убыванием, обусловленным локальной кластеризацией.](https://arxiv.org/html/2602.15390v1/Figures/Separation_radius_d=7.png)
В статье представлены усовершенствованные методы построения квазиравномерных точечных множеств, обеспечивающих более точное и эффективное моделирование сложных систем.
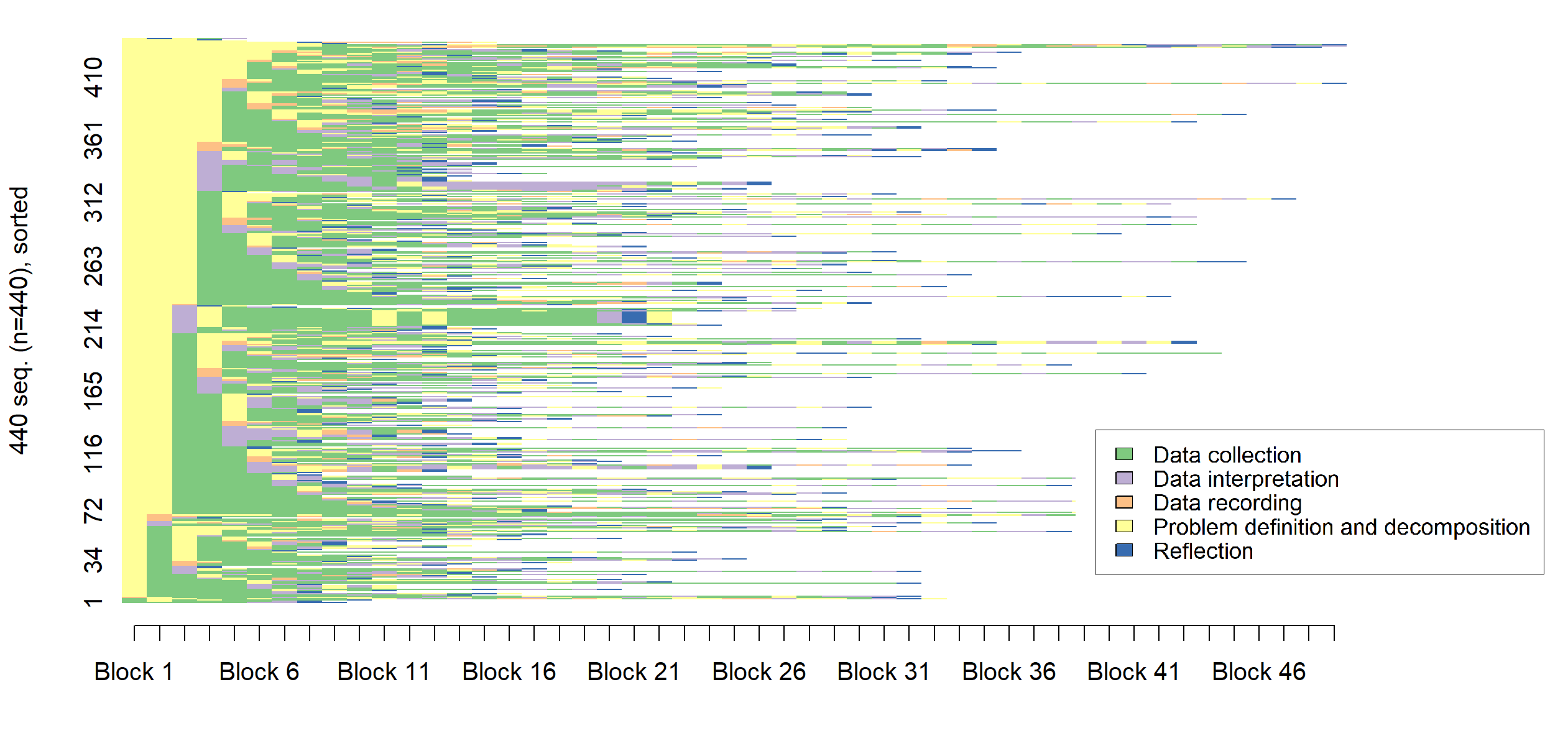
Новое исследование показывает, что ключевое отличие опытных специалистов в области анализа данных — не последовательность действий, а гибкость и эффективность их выполнения.
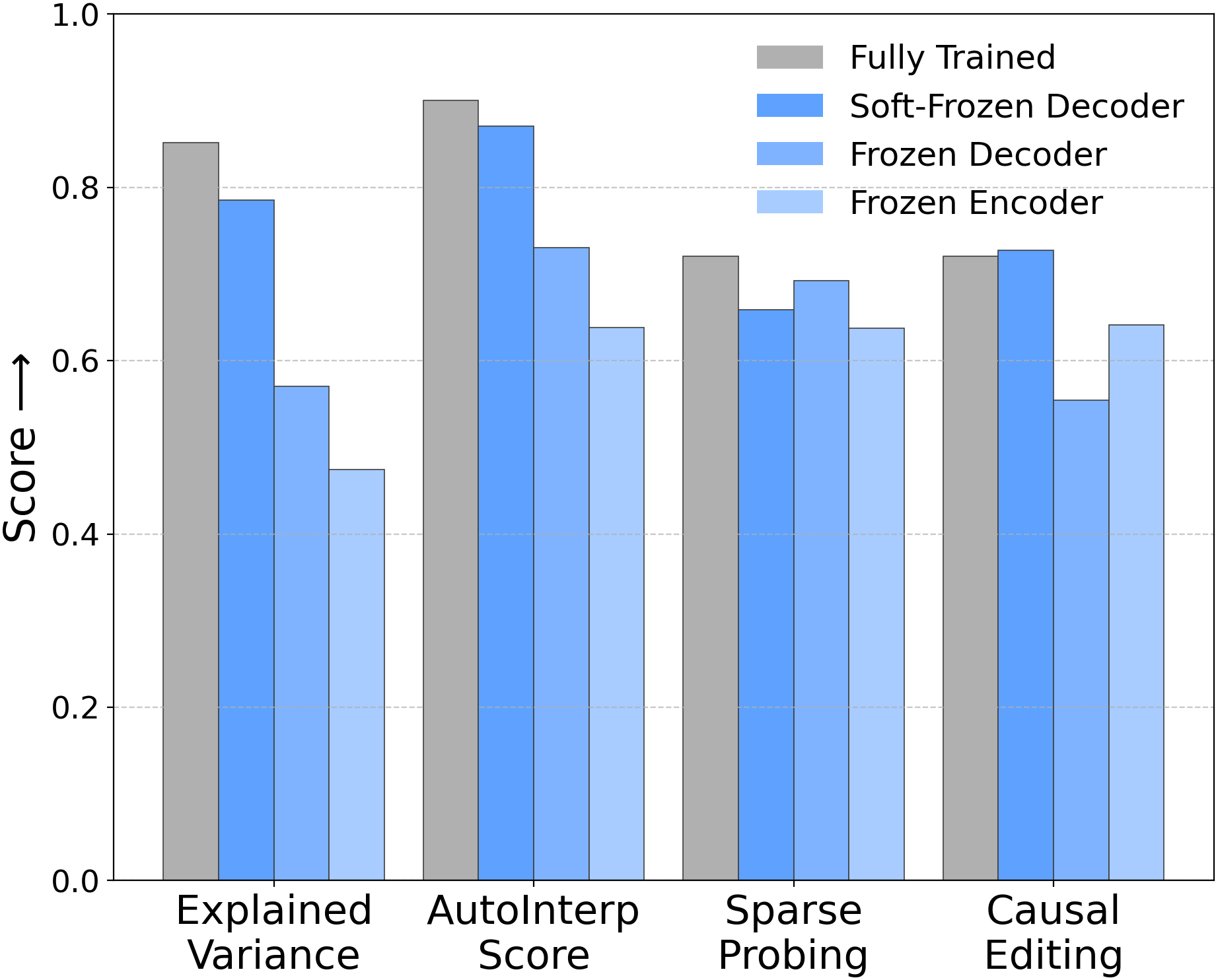
Новое исследование ставит под сомнение способность разреженных автокодировщиков извлекать значимые признаки, показывая, что они могут достигать высокой производительности реконструкции, не превосходя случайные модели.
![Эффективность переноса поляризации электрона на ядро [latex]\hat{\mathrm{S}}\_{x}[/latex] моделируется численно как функция смещения частоты спина электрона [latex]\Delta\omega\_{S}/(2\pi)[/latex] и времени контакта, демонстрируя зависимость от параметров, определенных с использованием симпсон-кода и параметров спиновой системы, при этом начальная инициализация и детекция основаны на импульсах [latex]\pi/2\_y[/latex] и последовательности эхо-импульсов, соответственно, а насыщающие импульсы и повторение элементов dn-эксперимента, используемые для накачки поляризации на несколько ядер, не включены в двухспиновые симуляции.](https://arxiv.org/html/2602.15793v1/x3.png)
Новая версия программного пакета SIMPSON открывает расширенные горизонты для численного моделирования сложных экспериментов в области ЯМР, ЭПР и ДНП.