Векторные представления нового поколения: эффективность и точность в поиске и анализе текста
![Архитектура модели jina-embeddings-v5-text представляет собой комплексную систему, предназначенную для эффективного кодирования текстовой информации в векторные представления, что позволяет осуществлять семантический поиск и анализ текста на основе [latex]n[/latex]-мерных эмбеддингов.](https://arxiv.org/html/2602.15547v1/img/architecture.png)
Новая серия моделей jina-embeddings-v5 обеспечивает высокую производительность в задачах семантического поиска и сравнения текстов, предлагая оптимальный баланс между размером и качеством.
![В рамках концепции вычислительного континуума реализована трехуровневая система автономной оркестровки сервисов, в которой текущее состояние сервисов анализируется посредством обучения поведенческих марковских одеял [latex] MB [/latex] на основе метрик обработки, агенты непрерывно оптимизируют работу сервисов, опираясь на внутреннее понимание окружающей среды и текущие соглашения об уровне обслуживания [latex] SLO [/latex], а для оптимизации выполнения [latex] SLO [/latex] по всему континууму происходит композиция [latex] MB [/latex], позволяющая количественно оценить зависимости между сервисами и хостинговыми устройствами.](https://arxiv.org/html/2602.15794v1/x1.png)
![Предлагаемая система обрабатывает разнородные состояния пространства [latex]\mathcal{S}[/latex] - такие как географические локации и поля ветра - посредством последовательного применения модулей пространственного запроса, пространственно-временного анализа и моделирования сельскохозяйственных культур; критически важный этап выравнивания координат преобразует исходную последовательность предварительного обучения в унифицированную последовательность [latex]g\to kg[/latex], после чего агент проверяет временную шкалу на наличие ошибок и соблюдение ограничений, касающихся валидности шаблонов и сохранения численных значений, прежде чем сформировать конечный результат.](https://arxiv.org/html/2602.15325v1/x1.png)
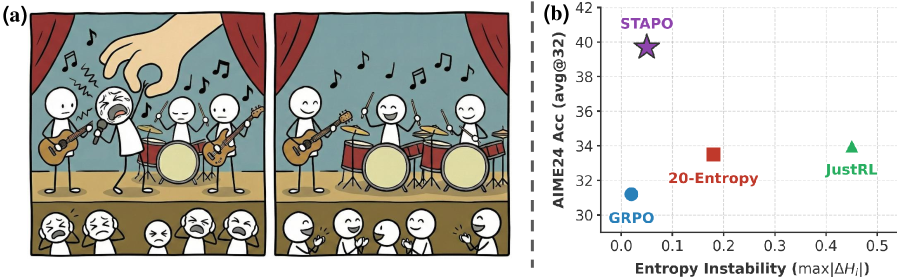

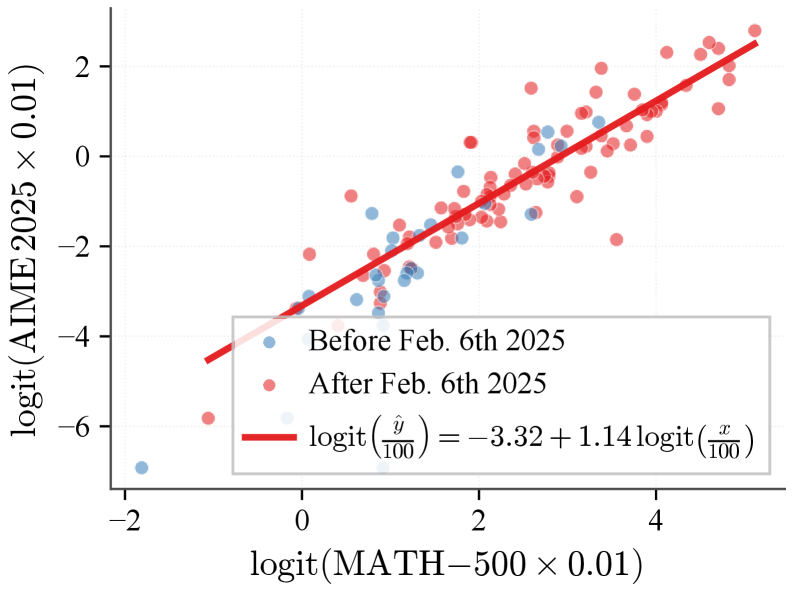
![Квантование с использованием равномерного распределения демонстрирует незначительно более высокую предсказательную точность (среднеквадратичная ошибка RMSE = 0.0305) по сравнению с квантованием на основе k-средних (RMSE = 0.0391), при этом оба метода обеспечивают сильное соответствие данным с коэффициентом детерминации [latex]R^2 > 0.96[/latex].](https://arxiv.org/html/2602.15563v1/figures/scaling_laws/06_predicted_vs_actual_scatter.png)
