Обучение на опыте: новый подход к развитию языковых моделей
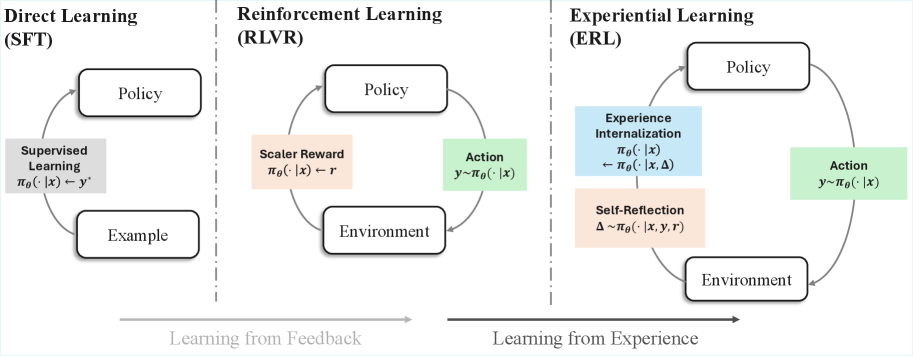
В статье представлена концепция обучения на опыте, позволяющая языковым моделям самостоятельно анализировать свои действия и улучшать результаты в сложных задачах.
В статье представлена концепция обучения на опыте, позволяющая языковым моделям самостоятельно анализировать свои действия и улучшать результаты в сложных задачах.
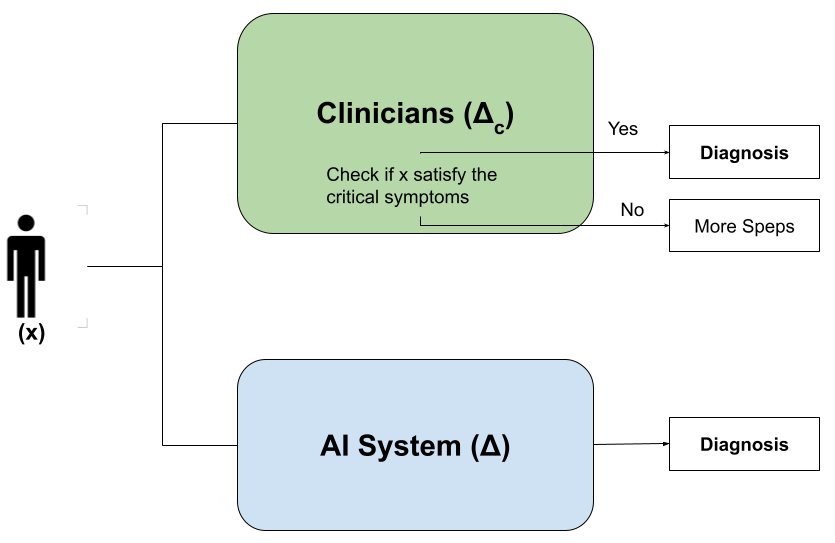
Новый метод, основанный на анализе критических симптомов и абдуктивных объяснениях, позволяет оценить и улучшить соответствие между логикой искусственного интеллекта и принятием клинических решений.
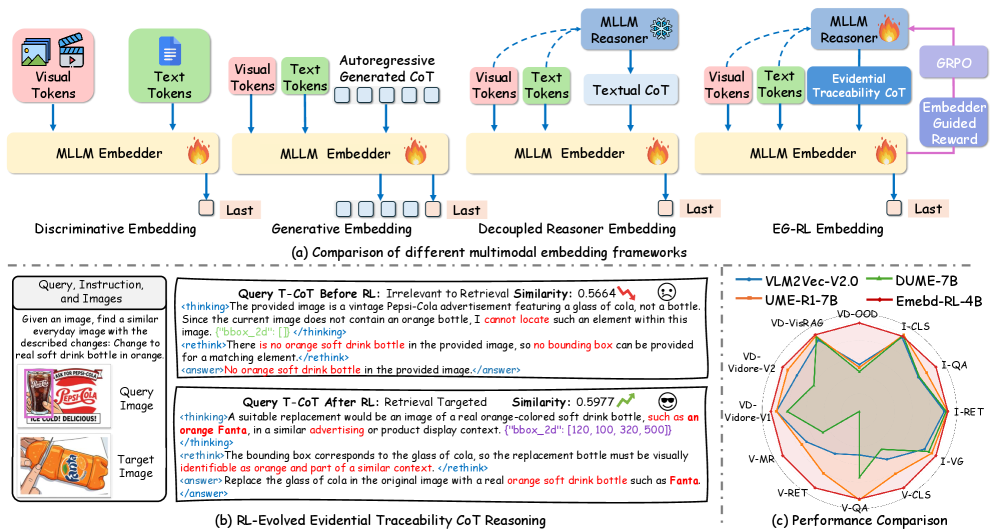
Новый подход использует обучение с подкреплением для оптимизации процесса рассуждений и повышения точности поиска информации в различных модальностях.
Исследователи представляют Qute — интегрированную архитектуру квантовой базы данных, призванную использовать возможности квантовых вычислений для ускорения фильтрации данных и других операций.
Представлена FireRed-Image-Edit, инновационная архитектура на основе диффузионных трансформаторов, позволяющая с высокой точностью редактировать изображения по текстовым инструкциям.
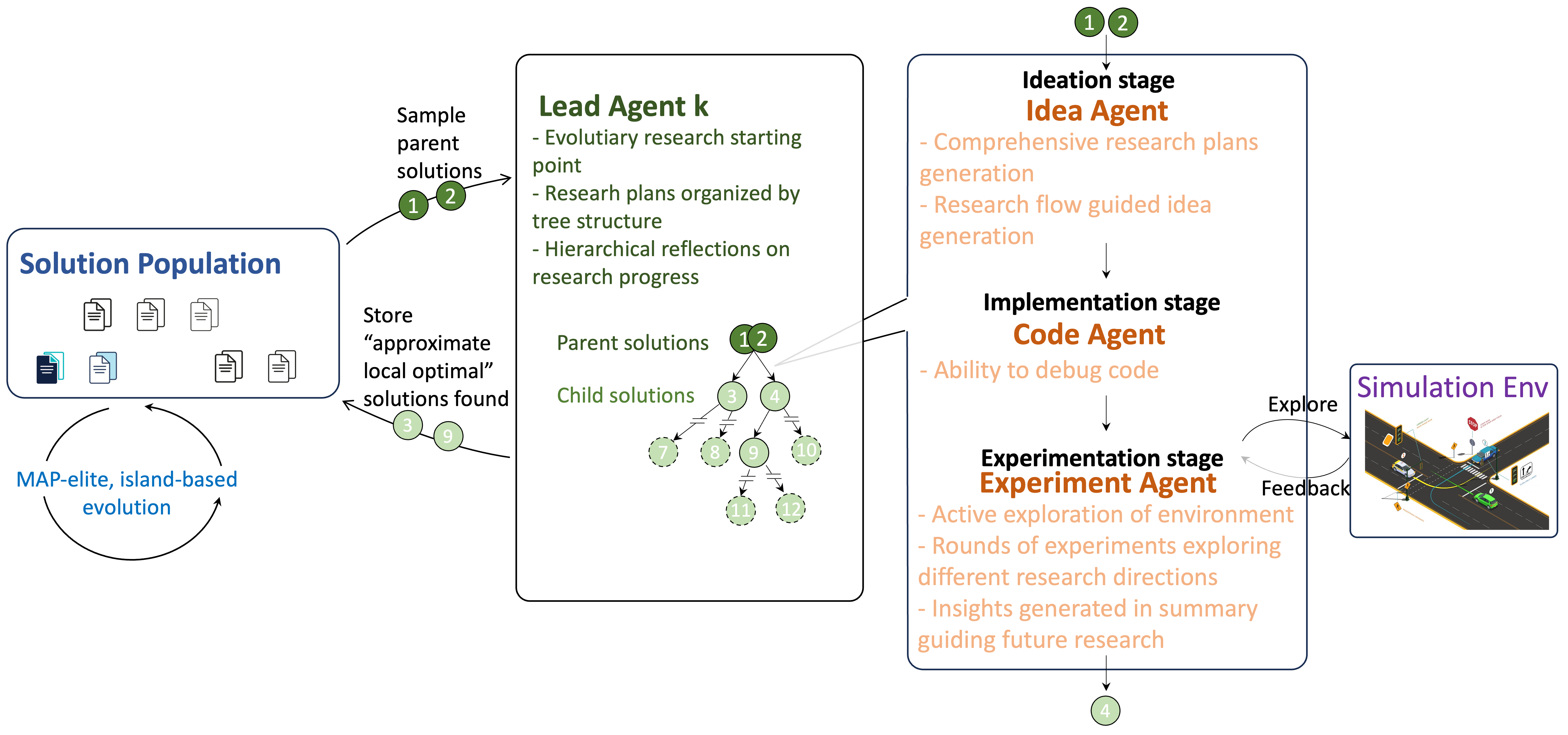
Новая система объединяет возможности больших языковых моделей и поиска по дереву для автоматизации научных исследований в области математической оптимизации.
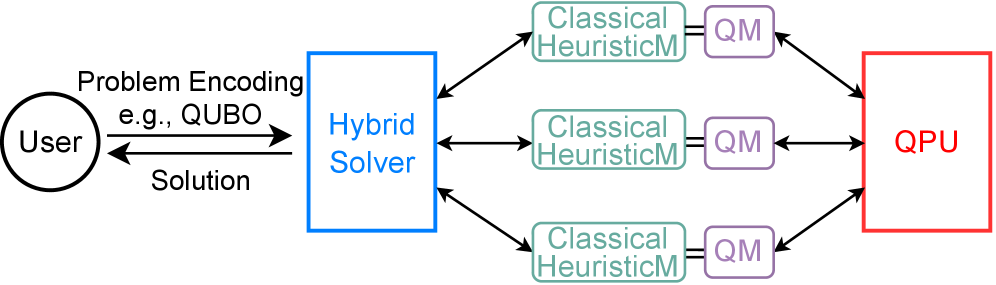
Новый подход к организации баз данных использует гибридные квантово-классические алгоритмы для ускорения обработки запросов и повышения масштабируемости.
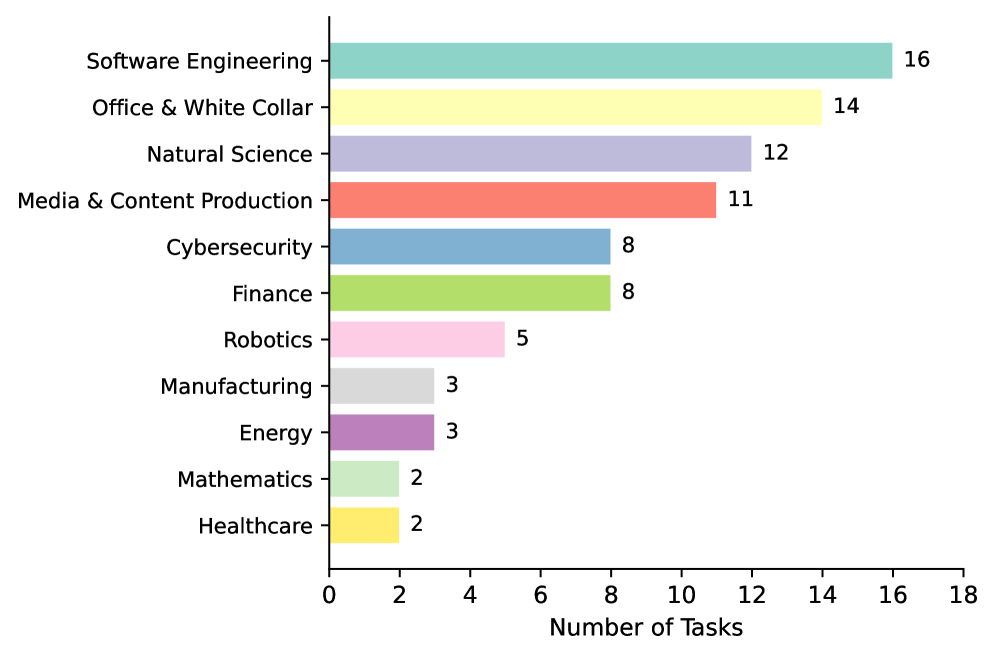
Новое исследование демонстрирует, что тщательно подобранные навыки значительно повышают эффективность интеллектуальных агентов в решении различных задач.
![Визуальный интеллект рассматривается как задача предсказуемого сжатия, где масштабируемое обучение возникает благодаря соответствию предсказуемой структуре мира, подобно видеокодекам, явно структурирующим визуальные сигналы на стабильный пространственный контекст и разреженные временные обновления, что позволяет OV-Encoder позиционироваться как масштабируемый механизм универсального мультимодального интеллекта, способного воспринимать, обновлять и рассуждать во времени, опираясь на принцип кодирования предсказуемой информации и минимизации избыточности, как это реализовано в современных видеокодеках, где [latex]I = S + R[/latex], где <i>I</i> - исходное изображение, <i>S</i> - стабильный контекст, а <i>R</i> - разреженные обновления.](https://arxiv.org/html/2602.08683v2/x1.png)
Исследователи предлагают инновационную архитектуру видео-трансформера, вдохновленную принципами кодирования видео, для более эффективного и надежного анализа визуальной информации.
В статье представлена исчерпывающая классификация квантовых подгрупп специальной линейной группы SL₂(ℂ) при корнях единства любого порядка.