Ускорение генерации текста: новый подход к работе с длинными контекстами
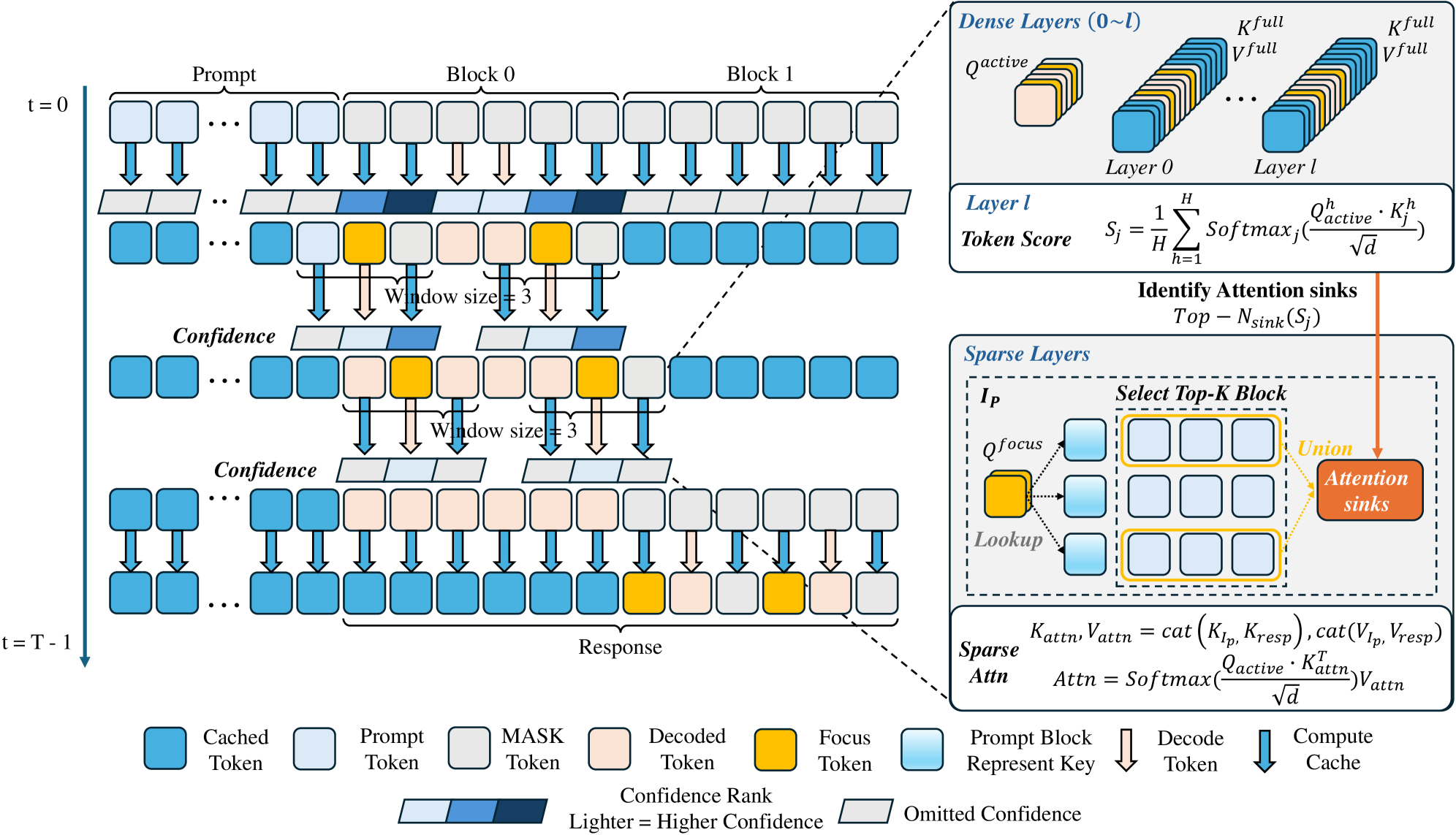
Исследователи предлагают эффективный метод повышения скорости работы больших языковых моделей при обработке длинных текстов, не жертвуя качеством генерации.
Исследователи предлагают эффективный метод повышения скорости работы больших языковых моделей при обработке длинных текстов, не жертвуя качеством генерации.
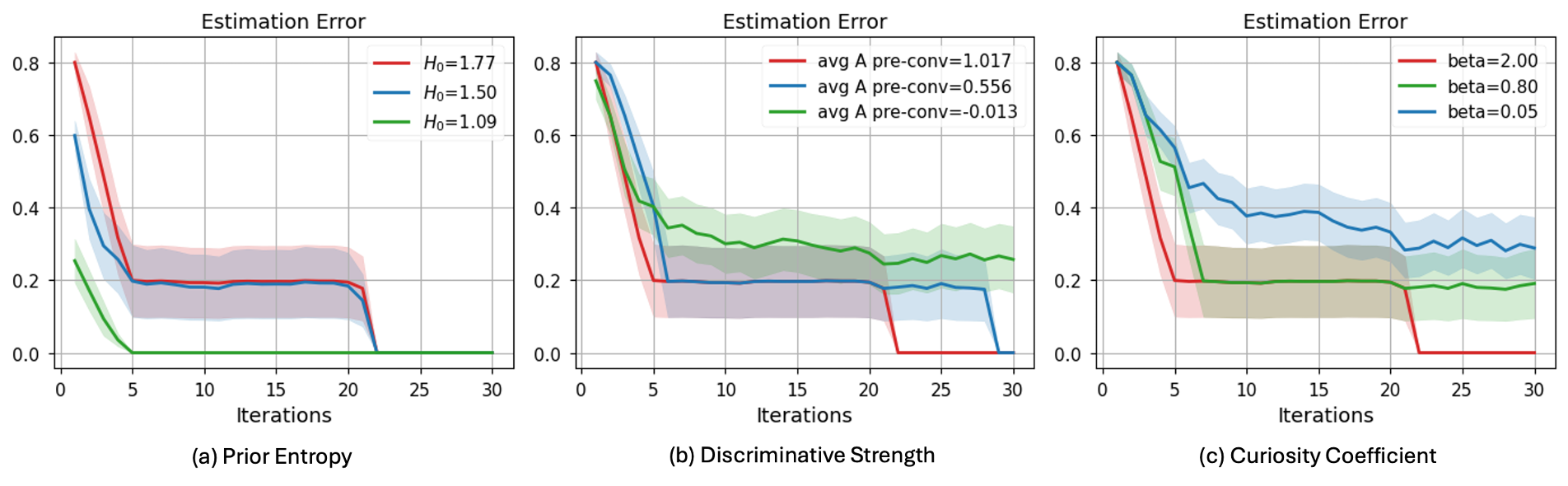
Новое исследование теоретически обосновывает, что достаточно высокий коэффициент ‘любопытства’ в алгоритмах активного вывода гарантирует как самосогласованное обучение, так и оптимальное принятие решений.
В статье представлен инновационный метод для повышения эффективности выборки вероятностных распределений в многомерных пространствах.

Исследователи представили инновационную архитектуру для эффективного сжатия и восстановления видеоданных, основанную на диффузионных моделях и трансформерах.
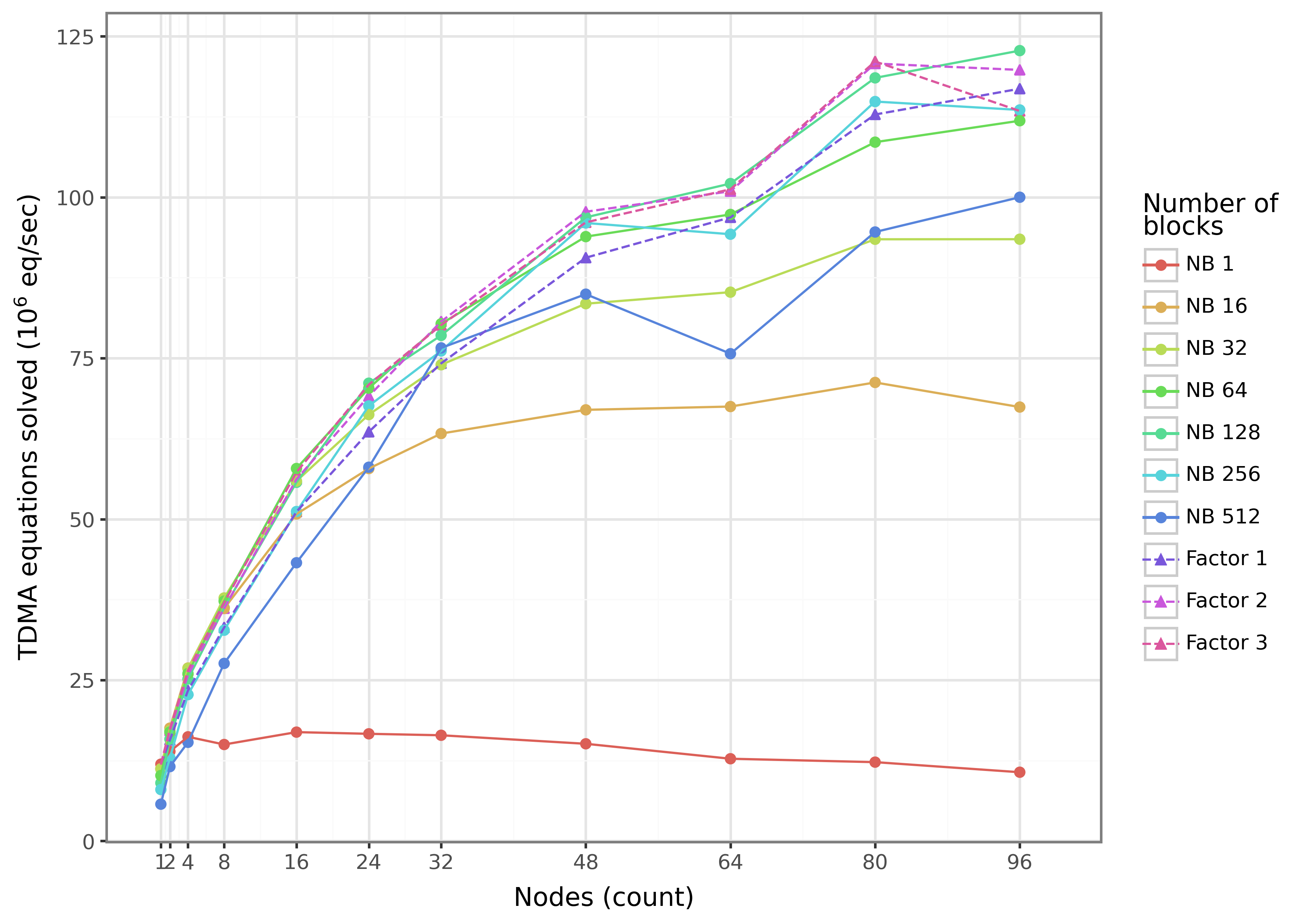
Представлен BioFVM-B — библиотека, значительно ускоряющая многомасштабное моделирование клеток и позволяющая симулировать целые микроокружения органов.
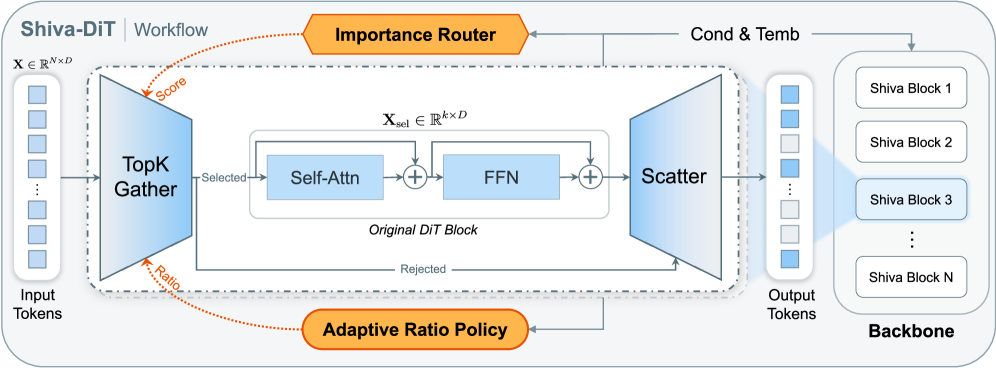
Исследователи предлагают инновационный метод адаптивной фильтрации токенов, позволяющий значительно повысить эффективность диффузионных трансформеров без потери качества генерируемых изображений.
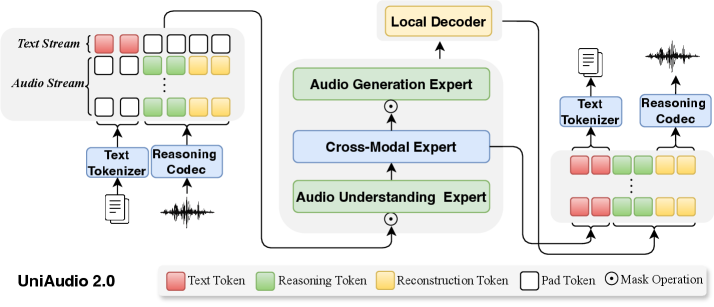
Исследователи представили UniAudio 2.0 — универсальную модель для обработки звука, способную понимать и создавать аудиоконтент, подобно тому, как языковые модели работают с текстом.

Новая архитектура DARWIN демонстрирует способность нейронных сетей к самосовершенствованию посредством генетического алгоритма и взаимодействия агентов.
Исследование представляет инновационный цифровой ускоритель Compute-in-Memory, оптимизирующий FP8 вычисления для достижения высокой производительности и снижения энергопотребления в задачах глубокого обучения.
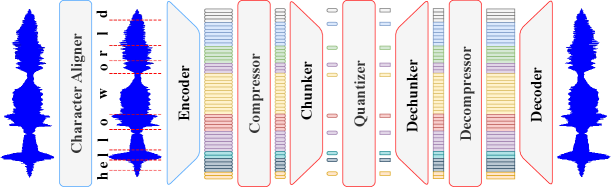
Исследователи предлагают инновационную систему кодирования речи, которая адаптируется к естественному ритму языка для повышения эффективности и качества звучания.