Qwen3-ASR: Голос без границ

Новая модель Qwen3-ASR открывает возможности для точного и многоязычного распознавания речи, обеспечивая высокую точность и временную синхронизацию.
Новая модель Qwen3-ASR открывает возможности для точного и многоязычного распознавания речи, обеспечивая высокую точность и временную синхронизацию.
Новые возможности генеративных моделей открывают невиданные горизонты в создании контента, но вместе с тем поднимают острые вопросы этики и безопасности.
![В рамках предложенной модели, описываемой уравнением (14) и характеризующейся параметрами U=1.0, V=0.5, E=0.32 и [latex]\omega_{p}=5.3[/latex] при [latex]N_{c}\approx 10\%[/latex], не равновесный спектр эмиссии [latex]\mathcal{A}_{\mathbf{k}}(\omega)[/latex] демонстрирует различия в зависимости от используемого подхода: Хартри-Фока, двухчастичной теории возмущений в реальном времени (2B-RTDE) и двухчастичной теории Кубо-Грина (2B-KBE), при ширине зонда [latex]T_{w}=8\sqrt{2}[/latex], центрированного на [latex]T_{M}=60[/latex].](https://arxiv.org/html/2601.21088v1/x6.png)
Исследование демонстрирует, как метод расширения дисперсионного уравнения в реальном времени позволяет эффективно моделировать поведение квантовых систем в неравновесном состоянии.

Новый бенчмарк WorldBench позволяет оценить, насколько хорошо ИИ-системы понимают и предсказывают поведение физического мира, выходя за рамки простой визуальной правдоподобности.
Новый подход к разработке материалов объединяет возможности машинного обучения и оценки жизненного цикла для создания действительно экологичных и эффективных решений.
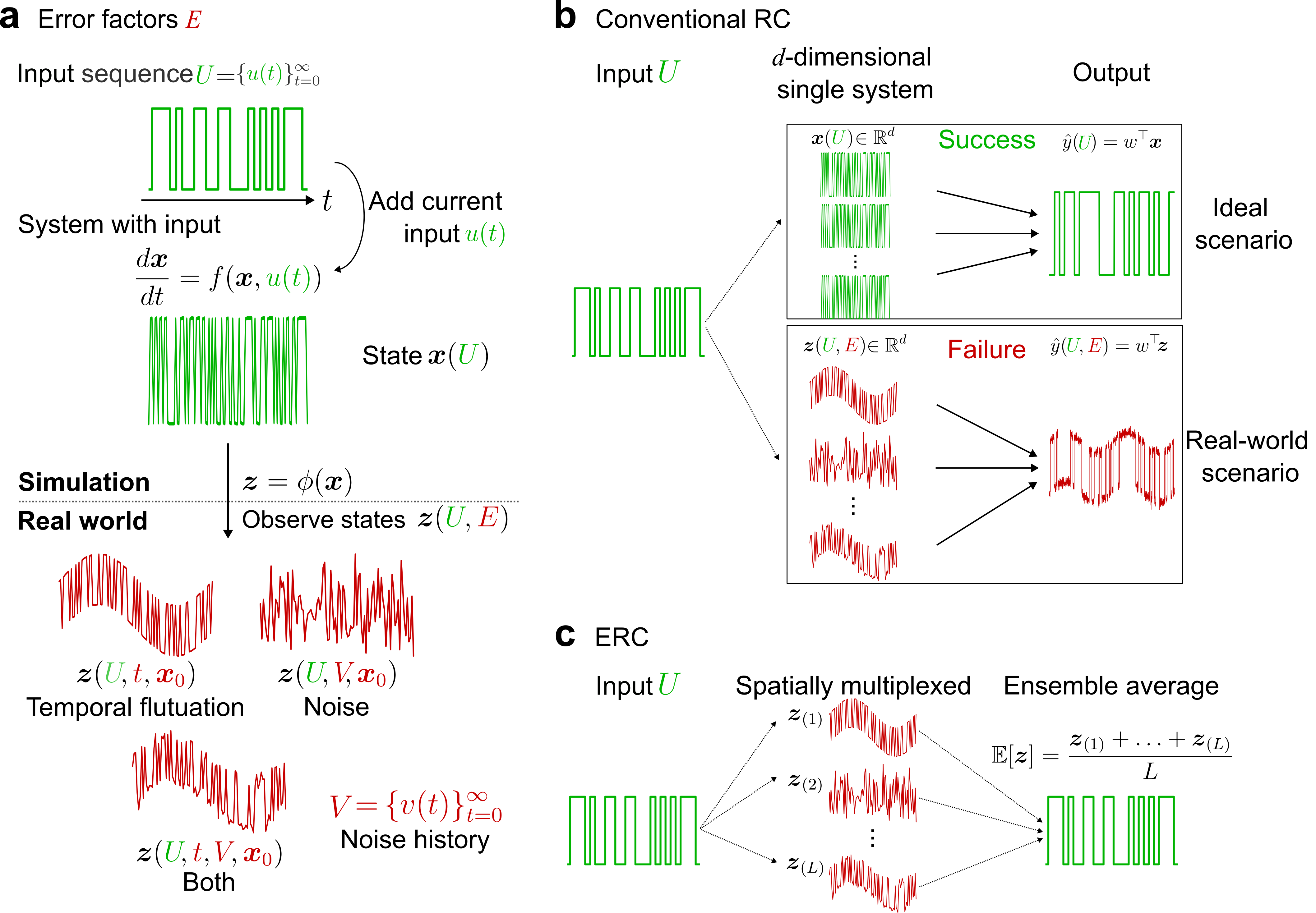
В статье представлен инновационный метод, использующий ансамблевое усреднение для повышения стабильности и эффективности вычислений в физических системах.
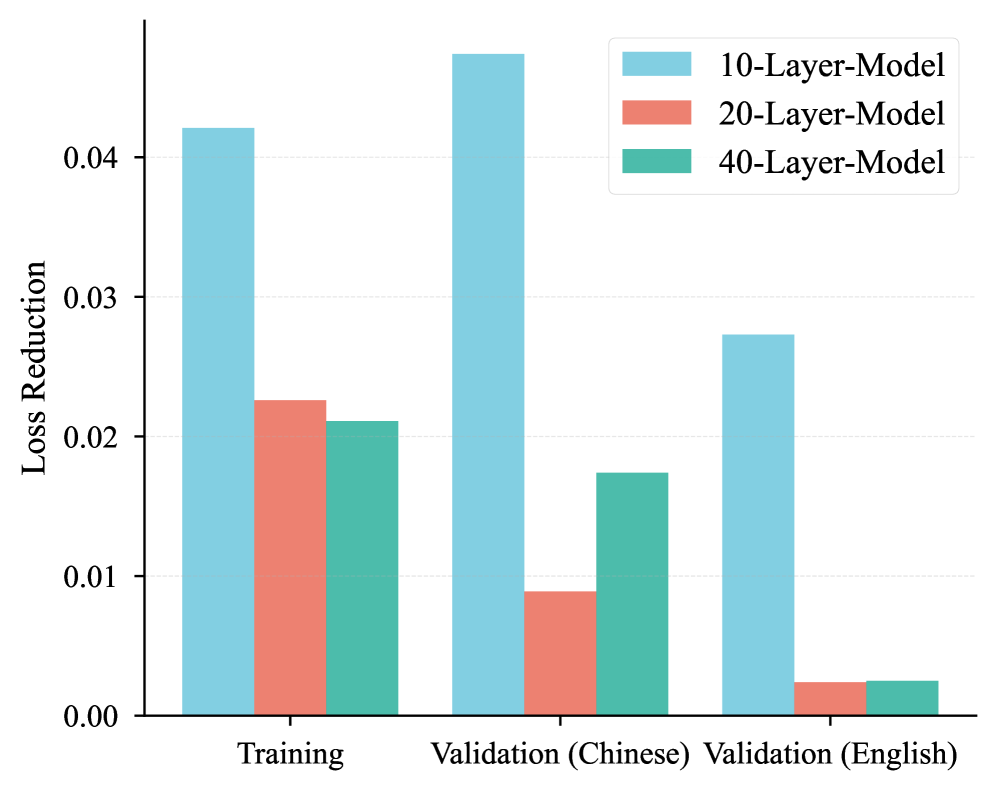
Исследование показывает, что увеличение размера словарного представления, а не количества экспертов, может стать более эффективным способом улучшения производительности и скорости работы больших языковых моделей.
![Исследование линейных зондов, применённых к трансформеру, обученному предсказывать бинарную операцию на [latex]S_5[/latex], и многослойному персептрону (MLP) на [latex]D_{30}[/latex], демонстрирует, что зонды, ориентированные на чередующиеся подгруппы и подгруппы вращений, достигают более высокой точности, чем зонды, обученные на случайной разметке, при этом доверительные интервалы, рассчитанные для MLP после каждого слоя ReLU, показывают стабильность результатов, в то время как значительные колебания производительности трансформера между различными инициализациями не позволяют сделать аналогичные выводы.](https://arxiv.org/html/2601.21150v1/subgroup_probe_mlp_dihedral.png)
Исследование показывает, могут ли узкие нейронные сети, обученные предсказывать операции в конечных группах, выявить абстрактные алгебраические концепции, такие как коммутативность и подгрупповая структура.

Многомодальные большие языковые модели, несмотря на впечатляющие возможности, подвержены проблеме межмодальных галлюцинаций, приводящих к неверной генерации информации. В работе ‘MAD: Modality-Adaptive Decoding for Mitigating Cross-Modal Hallucinations in Multimodal Large Language Models’ предложен метод Modality-Adaptive Decoding (MAD) — обучение без учителя, динамически взвешивающее вклад различных модальностей при декодировании. Данный подход позволяет модели фокусироваться на релевантной информации и подавлять межмодальные помехи, значительно снижая количество галлюцинаций в аудиовизуальных задачах. Не является ли адаптивное взвешивание модальностей ключевым шагом к созданию более надежных и эффективных многомодальных систем искусственного интеллекта?

В статье представлена инновационная концепция, объединяющая активное умозаключение и обучение с подкреплением, позволяющая агентам эффективно действовать в сложных средах.