Квантовые конструкторы для искусственного интеллекта

Новый подход к гибридным квантово-классическим моделям позволяет создавать более стабильные и устойчивые к шуму системы искусственного интеллекта.
Новый подход к гибридным квантово-классическим моделям позволяет создавать более стабильные и устойчивые к шуму системы искусственного интеллекта.
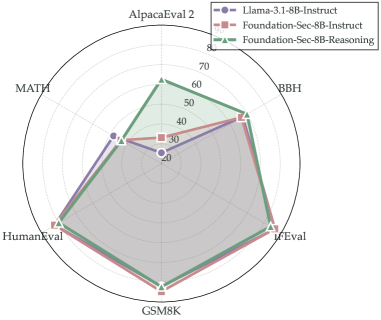
Представлена Foundation-Sec-8B-Reasoning — языковая модель с 8 миллиардами параметров, разработанная специально для решения задач в области кибербезопасности и демонстрирующая улучшенные возможности рассуждения.

Новое исследование оценивает способность современных систем искусственного интеллекта решать сложные научные задачи, приближенные к уровню экспертов.
Исследователи разработали детерминированный метод оптимизации нейронных квантовых состояний, позволяющий добиться высокой точности при моделировании сильно коррелированных систем.
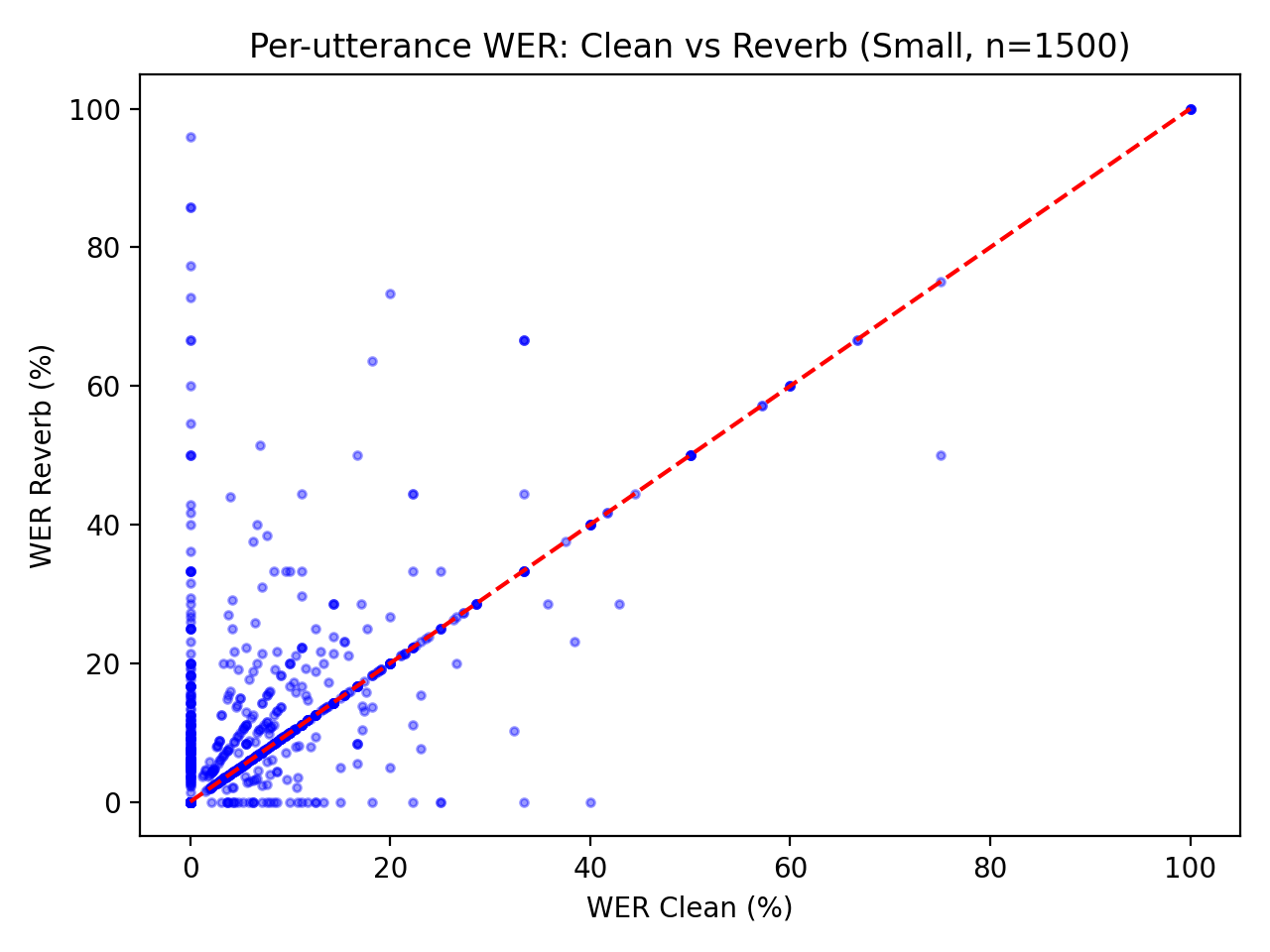
Представлен RIR-Mega-Speech — масштабный корпус речевых данных, записанных в различных реверберирующих помещениях, призванный улучшить устойчивость систем распознавания речи.

В статье представлена инновационная теория, объединяющая принципы континуальной механики и оптимального транспорта для создания генеративных моделей, эффективно работающих при ограниченном объеме данных.
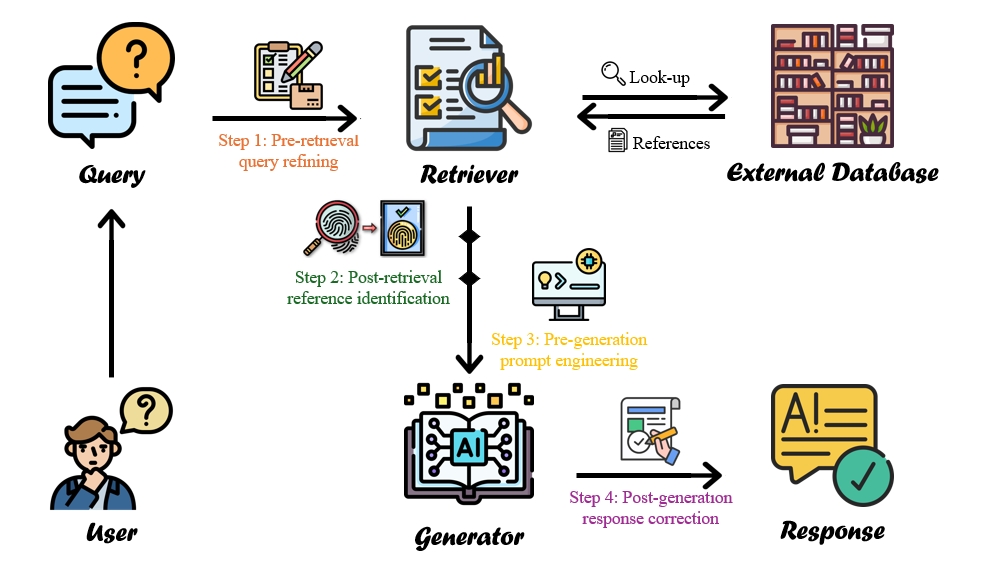
В статье представлен обзор методов атрибуции, направленных на снижение количества недостоверной информации, выдаваемой системами генерации, использующими поиск релевантных знаний.
Новое исследование показывает, что использование «персон» в запросах к большим языковым моделям может улучшить их способность к классификации социальных задач, но при этом снижает качество объяснений и не решает проблему предвзятости.
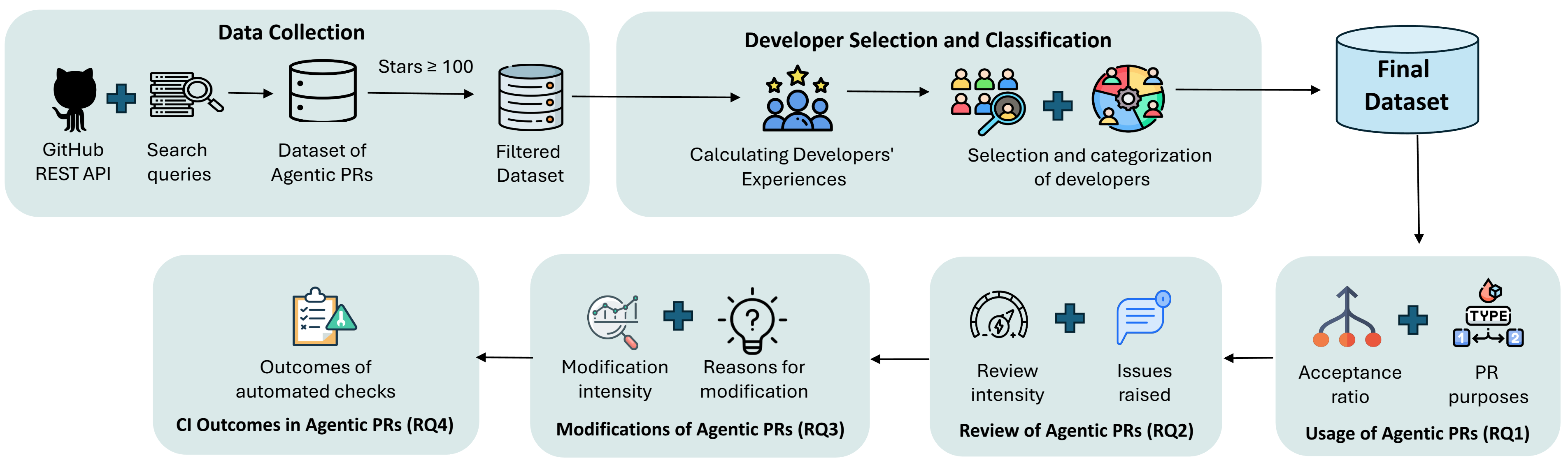
Новое исследование показывает, что опыт разработчиков по-прежнему определяет способы взаимодействия с инструментами автоматизации кода, даже с появлением «умных» помощников.

Исследование показывает, как использование оптимизатора второго порядка значительно повышает эффективность и скорость обучения моделей сжатия изображений.