Надежное обучение представлений: за рамками предсказательной неопределенности
Новый подход к машинному обучению позволяет создавать более стабильные и отказоустойчивые модели за счет явного моделирования неопределенности на уровне признаков.
Новый подход к машинному обучению позволяет создавать более стабильные и отказоустойчивые модели за счет явного моделирования неопределенности на уровне признаков.
Исследование показывает, что формулы дизъюнктивной нормальной формы (ДНФ) могут быть проверены на истинность с допустимой относительной погрешностью, открывая новые возможности для оптимизации алгоритмов.
Представлена система YuFeng-XGuard, обеспечивающая интерпретируемую и адаптивную защиту больших языковых моделей от потенциально опасных ответов.
Статья посвящена обзору космической обсерватории LISA, призванной уловить гравитационные волны от слияния компактных объектов и расширить наше понимание Вселенной.
В статье представлен обзор перспективных применений графена в различных областях энергетики, от аккумуляторов до водородных технологий.
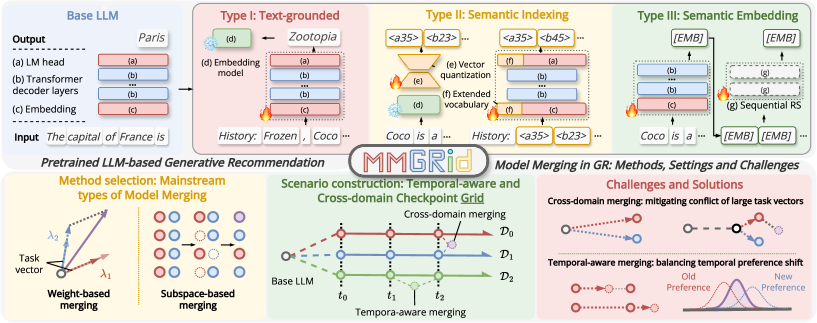
Новый подход позволяет рекомендательным системам динамически адаптироваться к изменяющимся предпочтениям пользователей и использовать данные из разных источников.
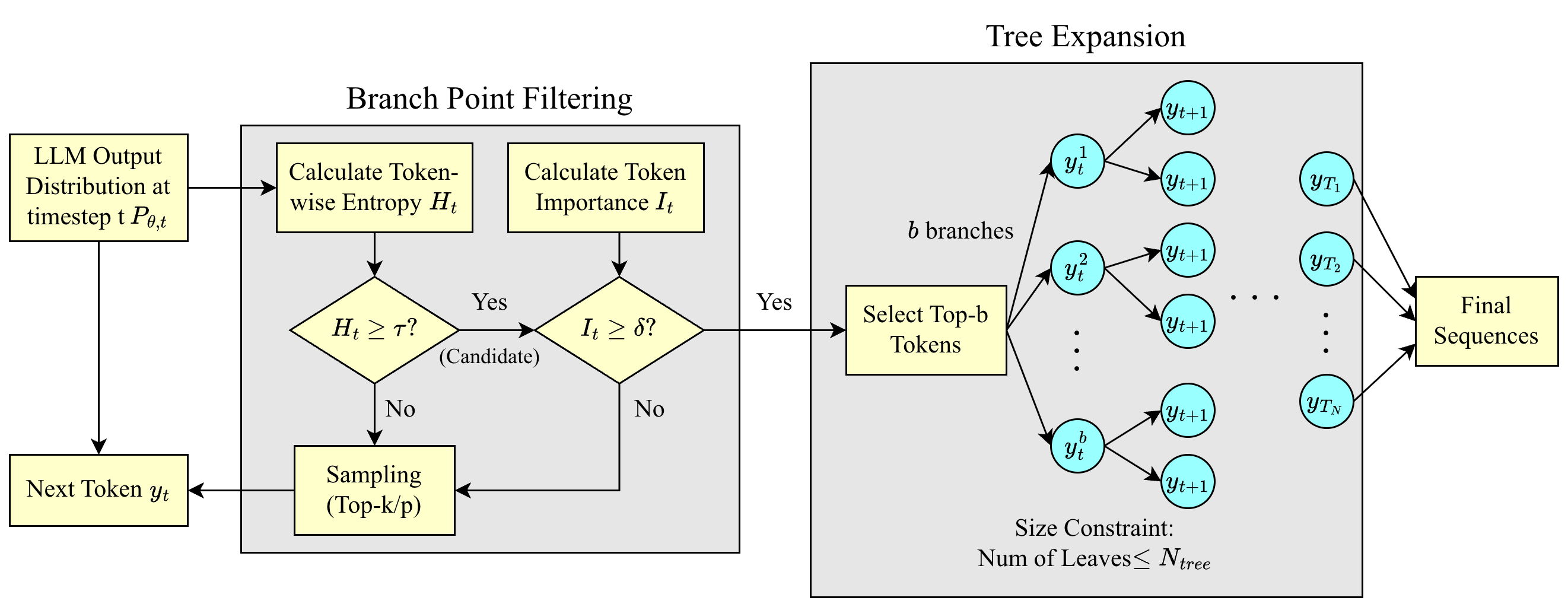
Исследователи предлагают стратегию декодирования, фокусирующуюся на наиболее неопределенных токенах для повышения точности и надежности языковых моделей.
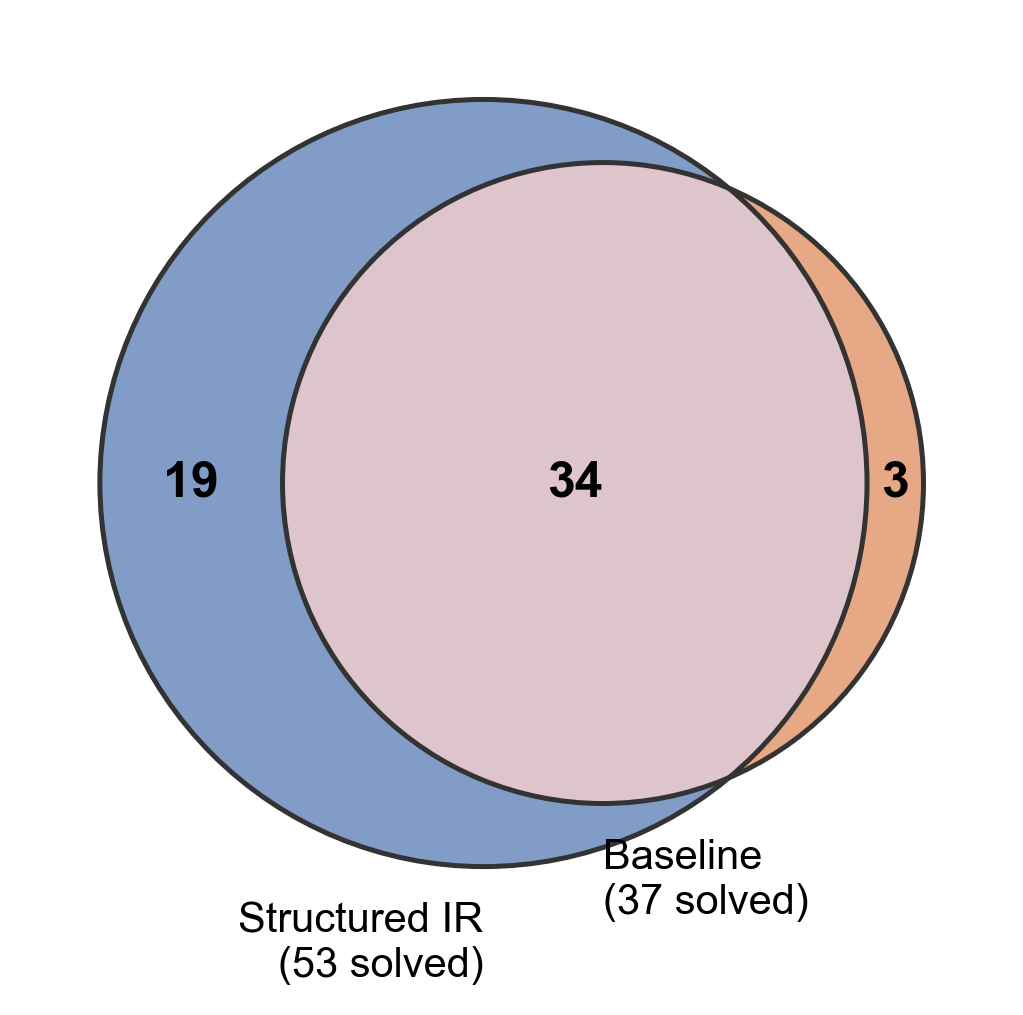
Новое исследование показывает, что структурированные подсказки значительно повышают эффективность нейронных систем, решающих математические задачи, даже при ограниченных вычислительных ресурсах.
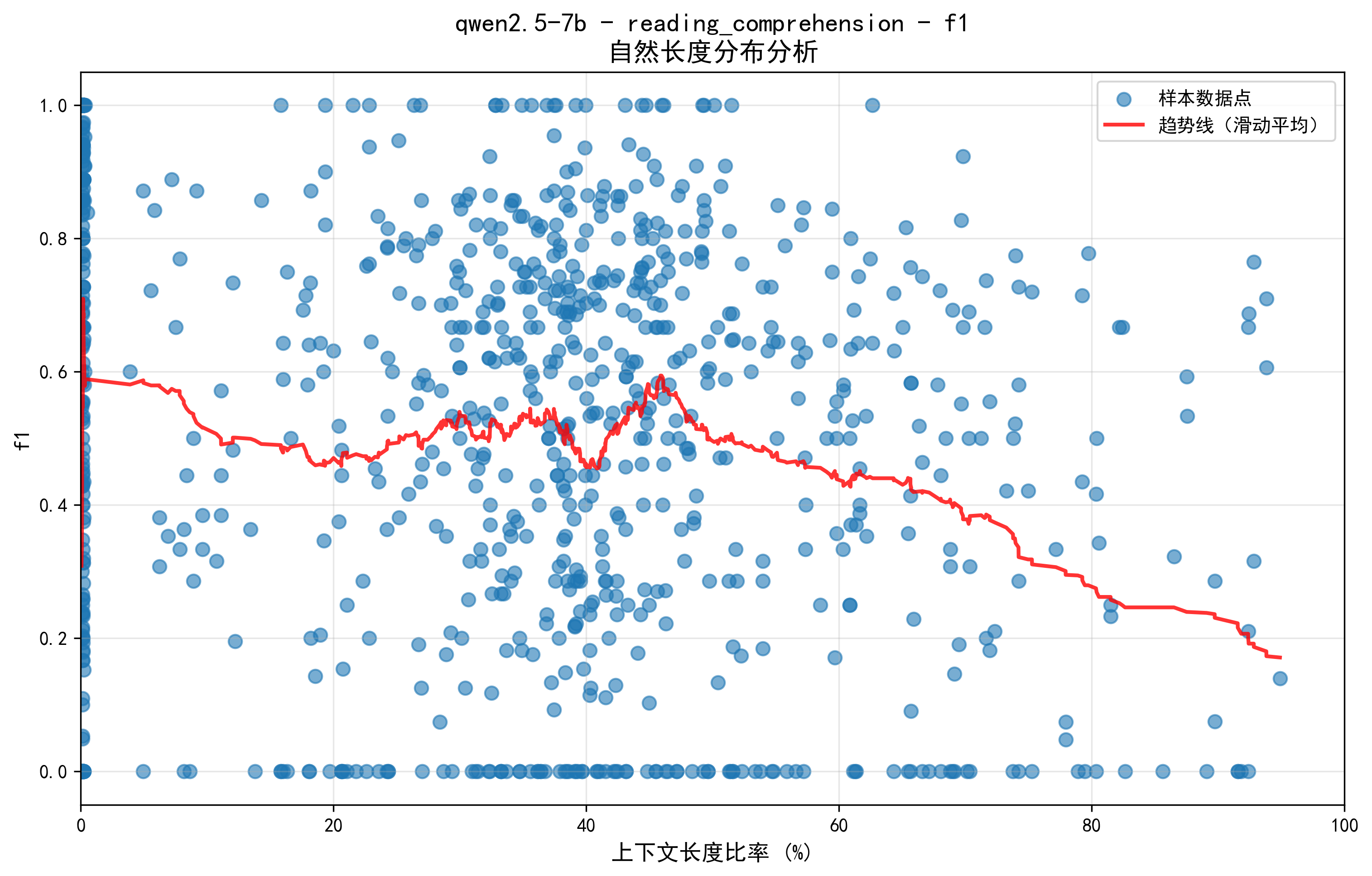
Новое исследование показывает, что производительность больших языковых моделей резко падает при обработке длинных текстов, несмотря на теоретическую возможность работать с большими объемами информации.
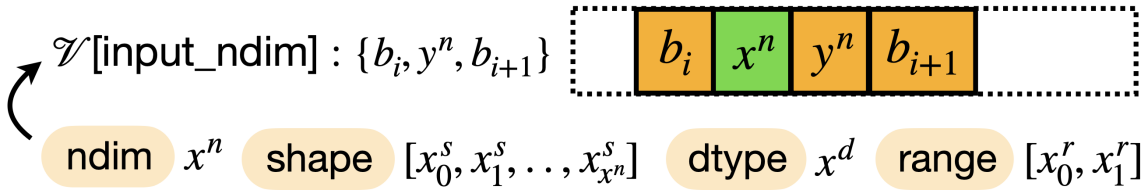
В новой работе представлена методика, использующая возможности больших языковых моделей и символьного исполнения для автоматизированного поиска уязвимостей в коде, используемом для создания нейросетей.