Искусственный интеллект, который ищет сам: новая стратегия обучения

Исследователи разработали метод, позволяющий системам искусственного интеллекта самостоятельно улучшать качество поиска информации для более эффективного решения задач.
Исследователи разработали метод, позволяющий системам искусственного интеллекта самостоятельно улучшать качество поиска информации для более эффективного решения задач.
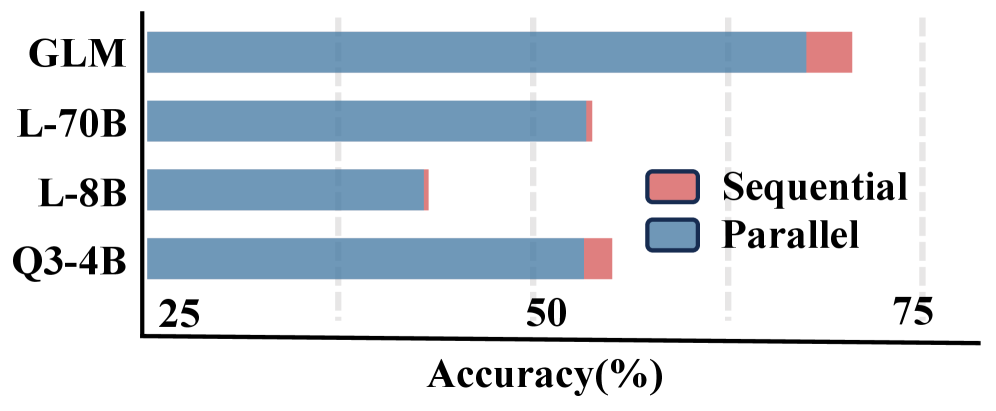
Исследователи представили новый способ оценки качества управления долгосрочной памятью в больших языковых моделях, выявляя слабые места существующих систем вознаграждения.
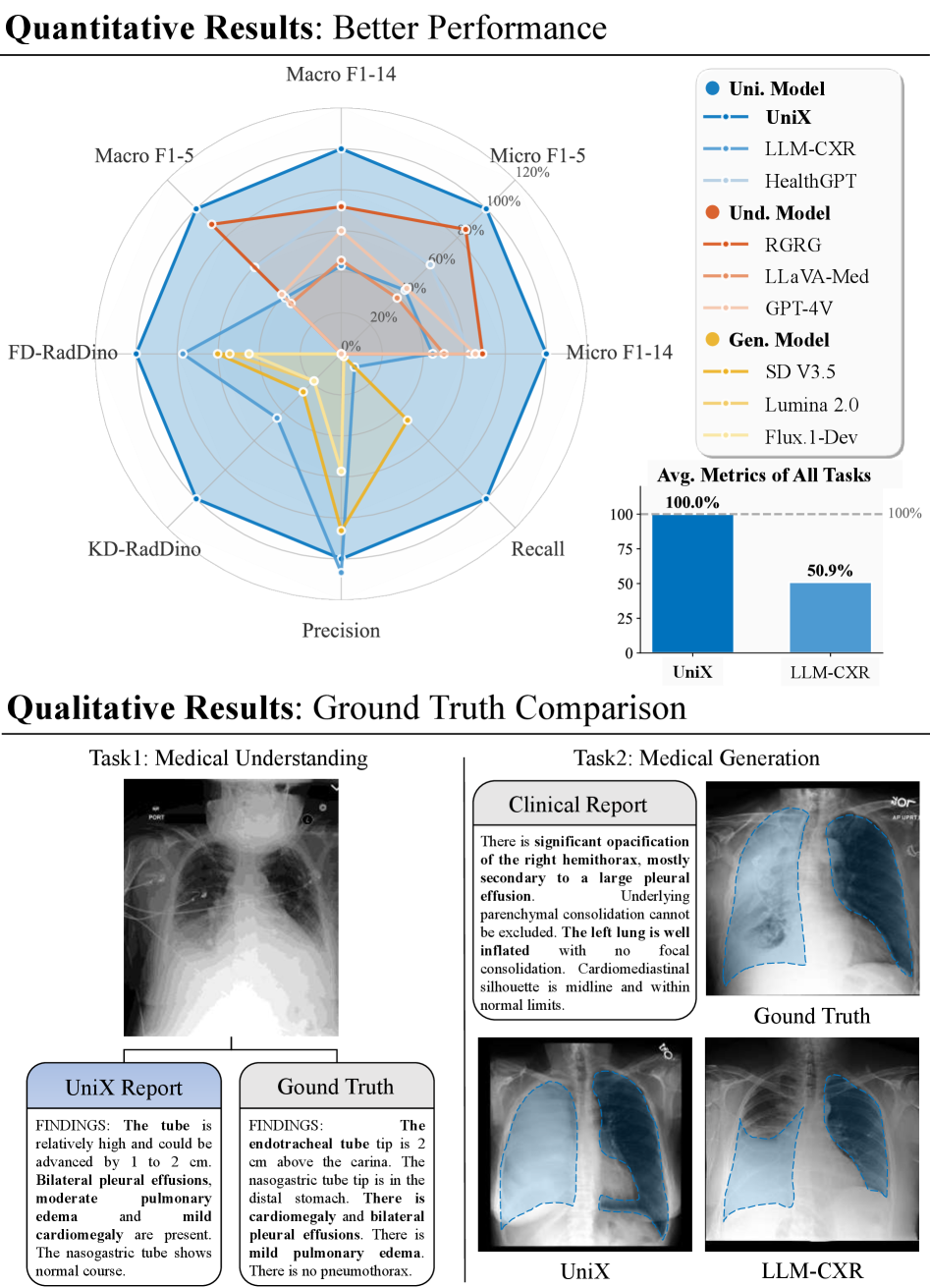
Новая модель объединяет возможности авторегрессии и диффузии для комплексного анализа и генерации изображений грудной клетки.
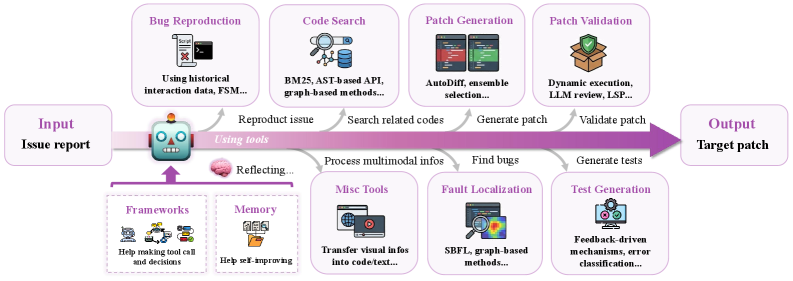
Обзор показывает, как современные модели машинного обучения автоматизируют рутинные задачи по исправлению ошибок и улучшению качества программного обеспечения.
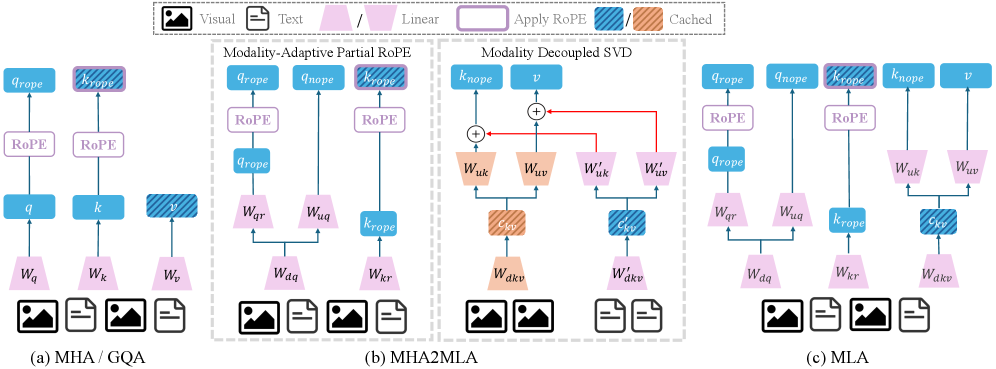
Исследователи разработали метод, позволяющий значительно снизить потребление памяти в мультимодальных моделях, не жертвуя при этом качеством обработки данных.
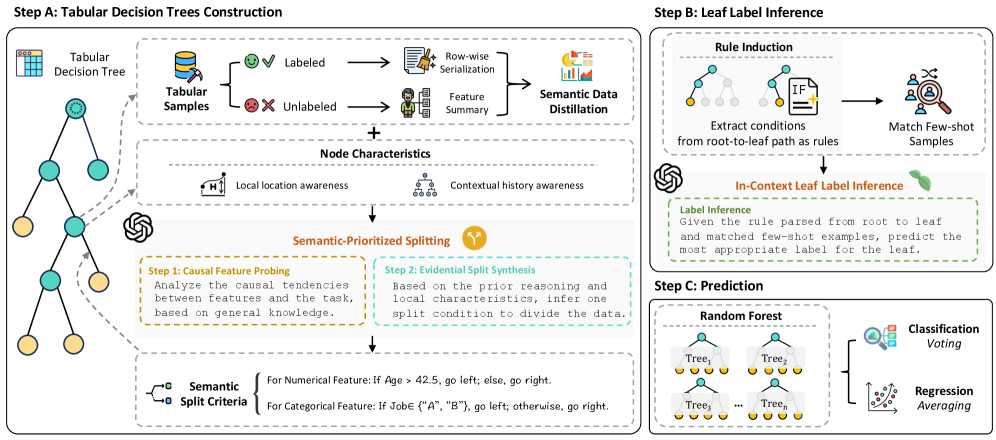
Исследователи разработали систему, использующую возможности больших языковых моделей для повышения эффективности алгоритмов случайного леса при работе с ограниченным объемом данных.
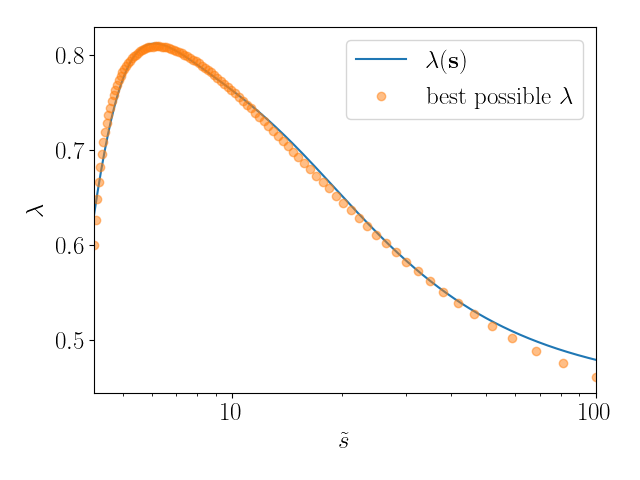
Исследователи предлагают использовать нейронные сети для оптимизации контурных деформаций, значительно повышая эффективность численного вычисления многомерных интегралов Фейнмана.
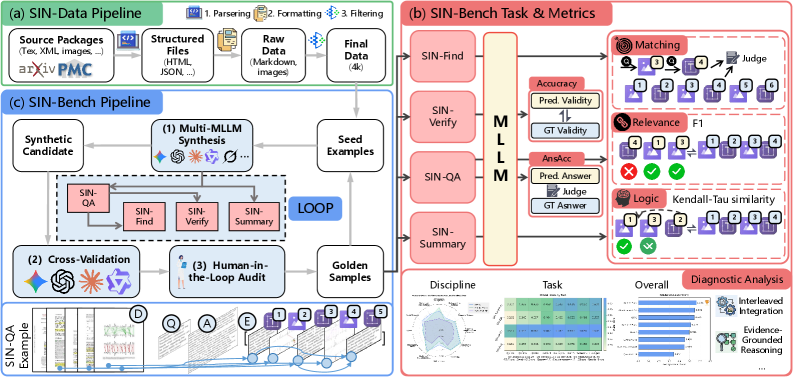
Ученые представили масштабный набор данных и методику оценки, позволяющие проверить, насколько хорошо современные системы искусственного интеллекта могут находить и связывать доказательства в сложных научных текстах.
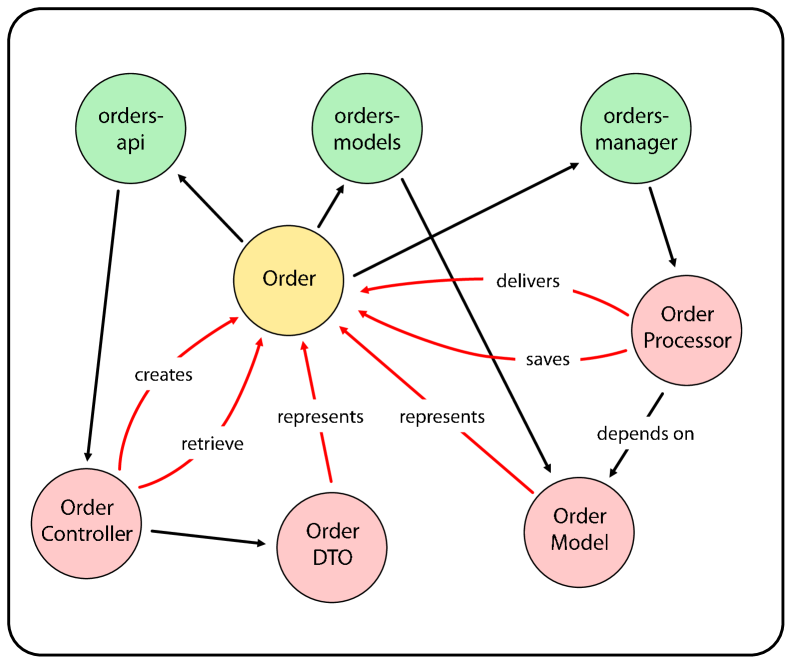
Исследователи представляют LogicLens — систему, использующую семантические графы и возможности больших языковых моделей для навигации и анализа сложных многорепозиторных кодовых баз.
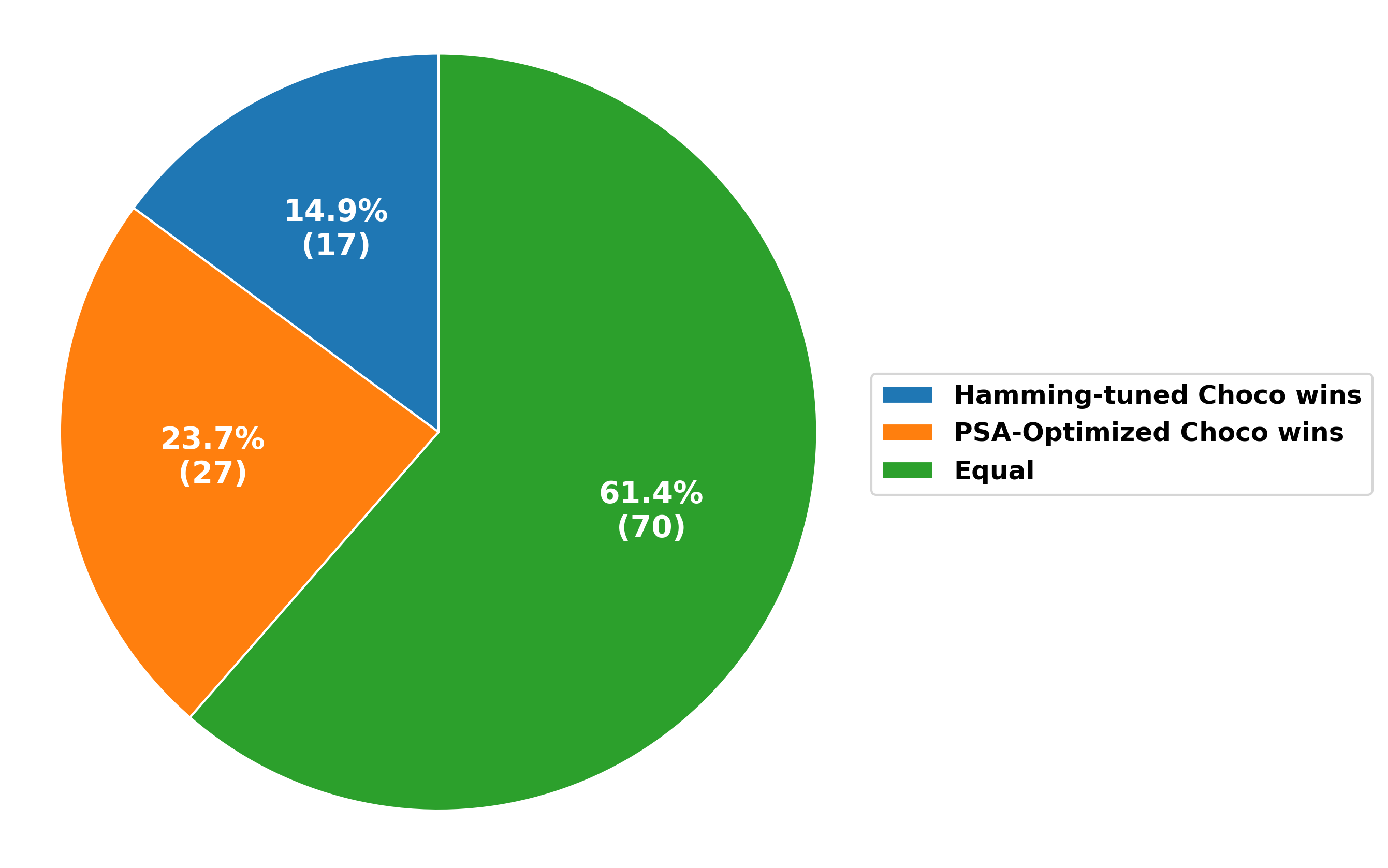
Новый подход позволяет автоматически оптимизировать параметры решателей задач ограничений, значительно повышая их эффективность.