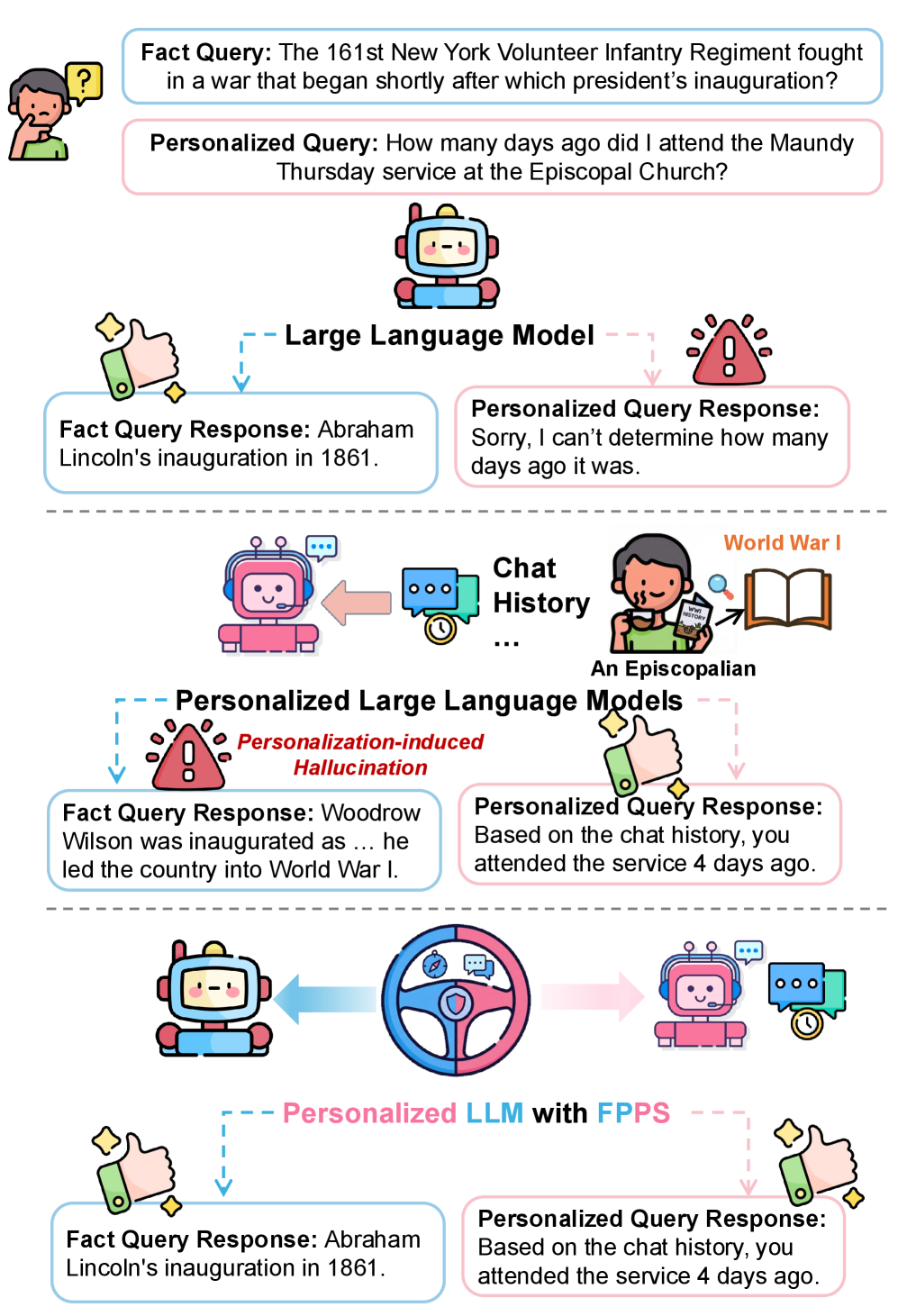
Искусственный интеллект на службе поиска работы: как улучшить запросы на рекомендации
Новое исследование показывает, что AI-агенты способны значительно повысить шансы на успех при обращении за помощью в поиске работы, особенно когда исходные запросы нуждаются в доработке.
![В отличие от существующих подходов к генерации видео, основанных на восстановлении зашумленных данных в латентном пространстве с помощью Flow Matching, которые игнорируют важные пространственно-временные физические закономерности и полагаются на субъективные оценки при обучении с подкреплением, PhysRVG использует цикл [latex]MD[/latex] для полного использования данных визуальной информации и обеспечивает внедрение физических знаний посредством метрики, основанной на физике, что позволяет стабильно сохранять и активно обнаруживать физические принципы для действительно физически осознанного обучения и генерации.](https://arxiv.org/html/2601.11087v1/x2.png)
[/latex], что сопровождается расхождением модуля производной [latex]|dW_0/dx|[/latex] и фактора усиления чувствительности [latex]\eta_{enh}[/latex], открывая возможности для повышения чувствительности квансоров на порядки величины.](https://arxiv.org/html/2601.10767v1/Fig1.png)
![Предложенная схема BAPO осуществляет обучение посредством чередования рассуждений агента, генерирующего множество вариантов решения для каждого вопроса путем комбинирования логических цепочек и взаимодействия с внешней средой, и вычисления вознаграждения, состоящего из оценки корректности ответа [latex]\mathcal{R}^{\textit{Correct}}[/latex], поощрения за выдачу ответа «не знаю» [latex]\mathcal{R}^{\textit{IDK}}[/latex] при отсутствии верного решения, а также адаптивного модулятора, динамически отключающего [latex]\mathcal{R}^{\textit{IDK}}[/latex] в зависимости от соотношения ответов «не знаю» на этапе исследования и разнообразия вариантов на этапе стабилизации.](https://arxiv.org/html/2601.11037v1/x2.png)
![На основе моделирования столкновений протонов на Большом адронном коллайдере, процесс [latex]q\bar{q}\to(Z/\gamma^{\<i>})\to H(Z/\gamma^{\</i>})\to H(\ell^{+}\ell^{-})[/latex] анализируется посредством оптимальных наблюдаемых [latex]{\cal D}_{\mathrm{opt,2}}[/latex], [latex]{\cal D}_{\mathrm{opt,1}}^{(1)}[/latex], и [latex]{\cal D}_{\mathrm{opt,1}}^{(0)}[/latex], полученных с использованием методов машинного обучения, что позволяет выявить распределение событий и предложить альтернативу подходу MELA для исследования данного процесса.](https://arxiv.org/html/2601.10822v1/x9.png)