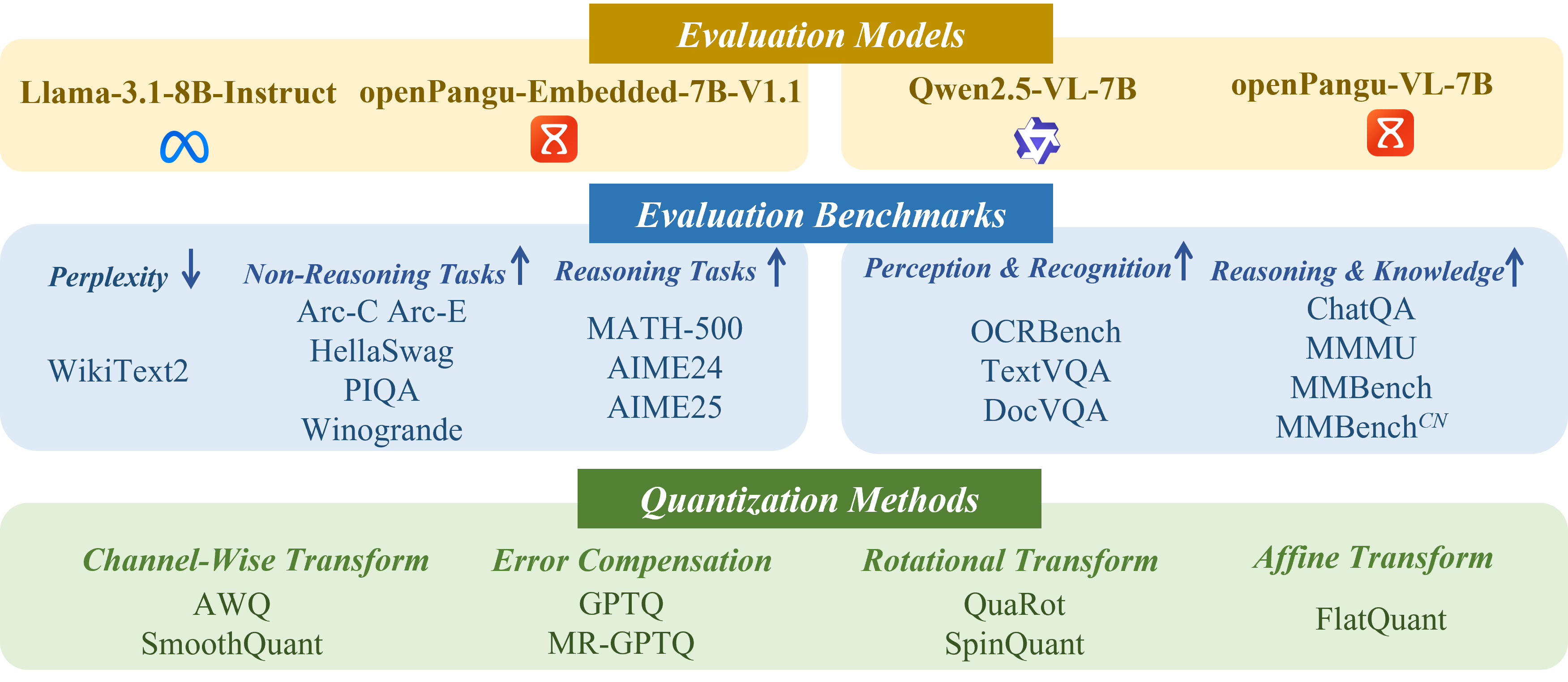
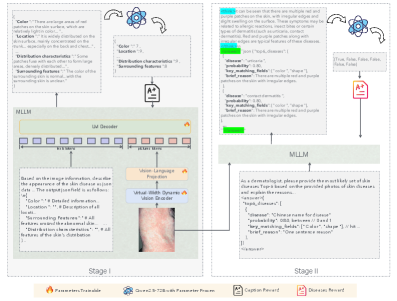
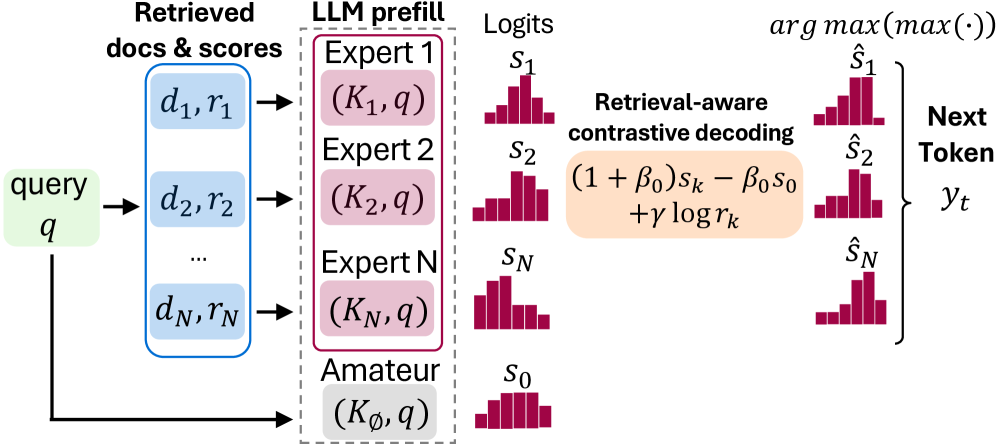
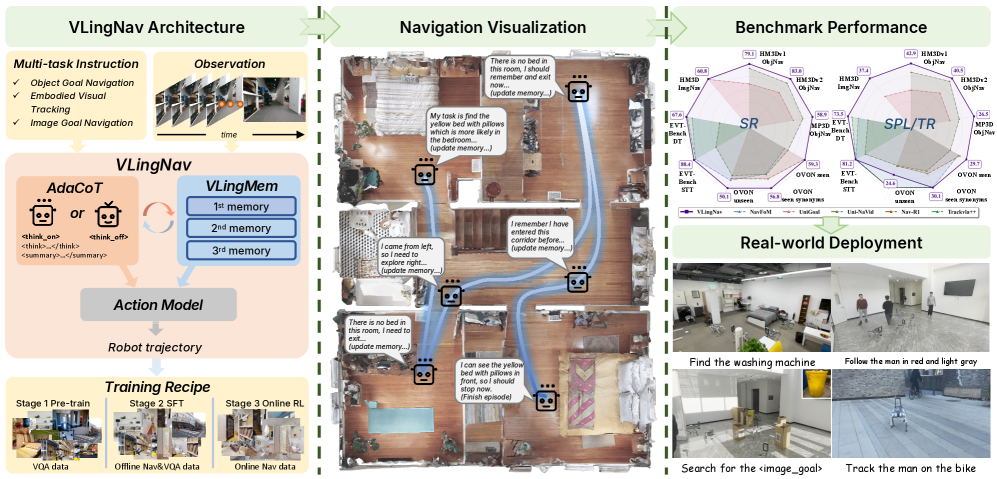
Искусственный интеллект на страже беспроводной связи: новый подход к моделированию каналов

В статье представлен инновационный подход к прогнозированию характеристик беспроводных каналов связи, основанный на применении методов искусственного интеллекта.