Музыка в объятиях квантов: новая модель для понимания полифонии
Ученые предлагают принципиально новый подход к моделированию музыкального контекста, вдохновленный законами квантовой физики.
Ученые предлагают принципиально новый подход к моделированию музыкального контекста, вдохновленный законами квантовой физики.
![Оценка производительности комплексного обучения (MATH и LIMR) и различных выборок полиматематического обучения (Синтетические простые, естественные примеры пред-алгебры, [latex]\pi_{1}[/latex]) на базе Qwen2.5-7b-base демонстрирует, что применение жадного декодирования и скользящего усреднения с окном в 5 точек для AIME2024, AIME2025 и других эталонов позволяет выявить различия в эффективности различных подходов к обучению.](https://arxiv.org/html/2601.03111v1/x10.png)
Новое исследование показывает, что для существенного улучшения способности больших языковых моделей к логическому мышлению достаточно всего одного, тщательно подобранного или сгенерированного примера.

Исследование демонстрирует значительный прогресс в использовании искусственного интеллекта для автоматизации и улучшения задач разработки программного обеспечения.
В статье исследуются скорости сходимости при обучении псевдодифференциальных операторов с использованием вейвлет-анализа и методов разреженного приближения.
![Предложенный подход DiffCoT преодолевает проблему накопления ошибок, свойственную традиционным методам последовательного рассуждения [latex]CoT[/latex], за счет одновременного анализа как шумовых, так и временных измерений, что позволяет итеративно корректировать предыдущие ошибки и эффективно снижать предвзятость, возникающую при несоответствии между обучением и применением.](https://arxiv.org/html/2601.03559v1/x1.png)
Исследователи предлагают инновационный подход к многоступенчатому логическому выводу, вдохновленный принципами диффузионных моделей, позволяющий языковым моделям самокорректироваться и повышать точность решения математических задач.
![Расширенная нейро-символическая архитектура обеспечивает одновременное обучение как нейронными сетями, так и символьными системами: прямой вывод ([latex]deduce()[/latex] методы нейронного и символьного модулей, соединённые через транслятор) формирует предсказания, в то время как нейронная индукция (обучение нейронного модуля посредством обратного распространения ошибки, основанного на абдуктивных сигналах от символьного модуля) и символическая индукция (добавление новых правил в политику символьного модуля через его метод [latex]induce()[/latex] во время эволюционных мутаций) обеспечивают адаптацию и обогащение знаний системы.](https://arxiv.org/html/2601.04799v1/x2.png)
Новый подход позволяет обучать системы, способные к логическому мышлению и адаптации, без необходимости в заранее заданных знаниях или градиентной оптимизации.
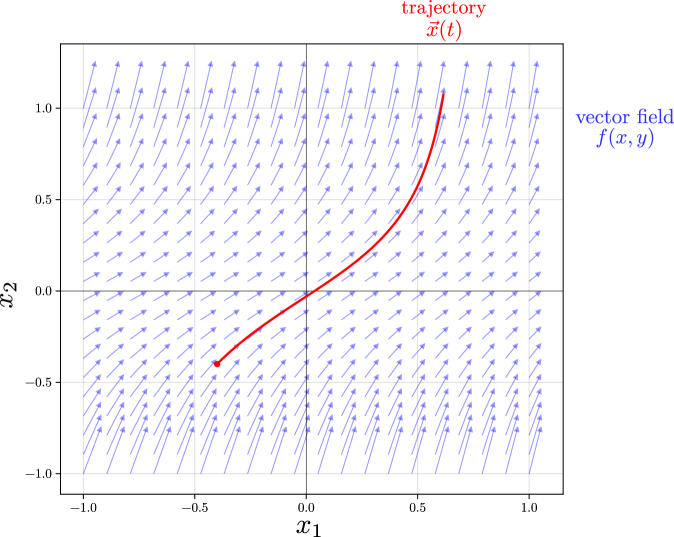
Эта статья предлагает всесторонний обзор теории динамических систем и методов анализа сложных процессов, изменяющихся во времени.

Новое исследование показывает, что в моделях Mixture-of-Experts формируется небольшая группа экспертов, обрабатывающая основную часть задач, независимо от входных данных.
Новое исследование углубляется в механизмы логического вывода у моделей обработки естественного языка, проверяя, насколько последовательны их умозаключения.
Исследователи представили Qwen3-VL-Embedding и Qwen3-VL-Reranker — модели, устанавливающие новые стандарты в поиске по изображениям и тексту.