Поиск и Логика: Как Отвечать на Сложные Вопросы
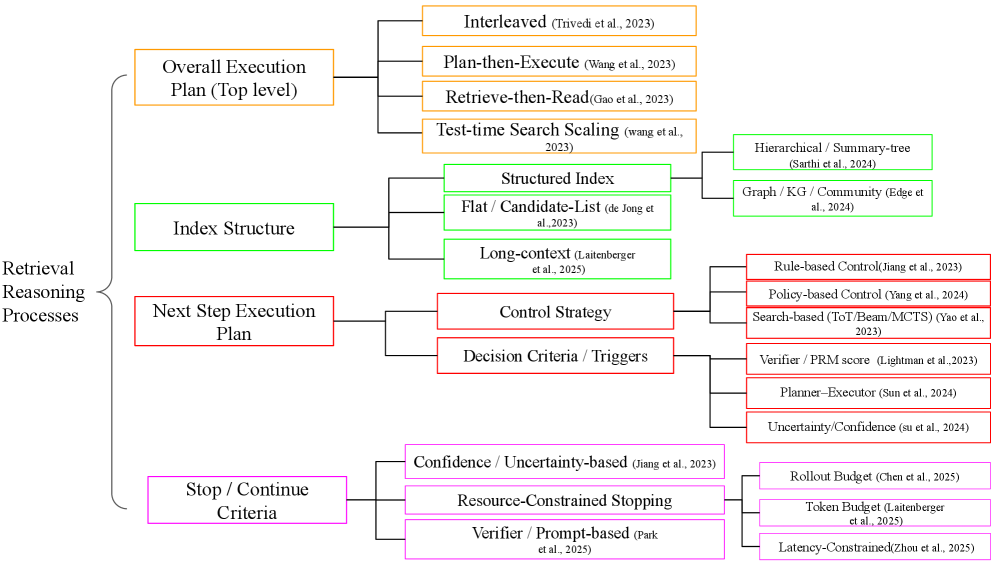
Новая работа предлагает структурированный подход к анализу процессов извлечения информации и логических рассуждений, необходимых для ответа на многоступенчатые вопросы.
Новая работа предлагает структурированный подход к анализу процессов извлечения информации и логических рассуждений, необходимых для ответа на многоступенчатые вопросы.
![Динамические видео предстают как адаптивные габоровские примитивы с плавным изменением движения, где траектории примитивов моделируются кубическими сплайнами Эрмита с контрольными точками [latex]\mu(t)[/latex] и [latex]q(t)[/latex], обеспечивающими непрерывность первого порядка, а обучаемые веса частот [latex]\omega_k[/latex] позволяют примитивам адаптироваться от гауссовского (низкочастотного) до габоровского (высокочастотного) представления, что способствует иерархической реконструкции деталей и оптимизируется совместным использованием RGB, данных о глубине, оптического потока и регуляризации кривизны [latex]L_{curv}[/latex], обеспечивая возможности интерполяции кадров, согласованности глубины и редактирования видео.](https://arxiv.org/html/2601.00796v1/x3.png)
Исследователи предлагают инновационный подход к реконструкции движущихся 3D-сцен, позволяющий добиться беспрецедентной детализации и плавности движения.
![В рамках исследуемой системы автоматического проектирования (ADS) процесс декларации знаний и декларации модели разграничен и структурирован посредством взаимодействия агентов, основанных на больших языковых моделях [latex]LLM[/latex], действий, выполняемых человеком, и точек принятия решений, что позволяет организовать последовательность операций от формулировки исходных требований до построения конечной модели.](https://arxiv.org/html/2601.00743v1/x1.png)
Исследователи предлагают фреймворк, позволяющий автоматически создавать сложные программы из текстовых инструкций, значительно упрощая процесс разработки.
![В предложенной схеме композиционного векторного квантования низкоразмерного кодекса входное изображение преобразуется в непрерывное латентное пространство [latex]zz[/latex], которое масштабируется билинейной интерполяцией с коэффициентом β, после чего каждый вектор признаков разделяется на [latex]m[/latex] блоков и квантуется с использованием общего кодекса [latex]\mathcal{C}[/latex], содержащего [latex]K[/latex] кодовекторов размерности [latex]d^* = d/m[/latex], а затем собранные и усреднённые блоки восстанавливают исходную форму [latex]zz[/latex], после чего декодер преобразует полученную карту признаков обратно в изображение.](https://arxiv.org/html/2601.00222v1/x2.png)
Исследователи представили LooC — инновационный метод векторной квантизации, позволяющий значительно уменьшить размер кодовых книг без потери качества реконструкции изображений.
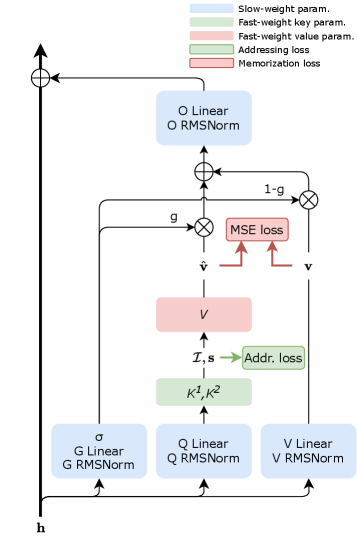
Исследователи представили инновационную архитектуру памяти, сочетающую в себе высокую емкость и способность к адаптации для эффективной обработки длинных последовательностей и улучшения эпизодической памяти.

Исследователи представляют открытый инструментарий для совместного проектирования электронно-фотонных систем с использованием искусственного интеллекта, ускоряя создание высокопроизводительных решений.
![Разработанная схема MORE-ML, объединяющая квантово-механические свойства молекулярных блоков с методами машинного обучения, позволяет предсказывать характеристики связывания, такие как [latex]E_{ads}[/latex], [latex]\Delta\phi[/latex] и [latex]\Delta Q[/latex], посредством регрессии и анализа объяснимости модели, при этом оптимизация гиперпараметров достигается через байесовскую оптимизацию с 100 итерациями и 10-кратной перекрестной проверкой, а предварительный отбор данных осуществляется с использованием обнаружения аномалий и метода farthest point sampling.](https://arxiv.org/html/2601.00503v1/FIG3_ML_workflow.png)
Новый подход объединяет расчеты квантовой механики и методы машинного обучения для создания более чувствительных и точных сенсоров, способных определять биомаркеры запаха тела.
Квантовый переход: не паниковать! Знаете, всегда забавно, когда банки начинают беспокоиться о квантовой физике. Как будто они вдруг решили, что деньги – это не просто цифры, а суперпозиция состояний! Но, если серьезно, это, конечно, разумный шаг. Представьте себе сейф, замок которого открывается сложной головоломкой. Сейчас эта головоломка настолько сложна, что взломать ее обычными средствами практически … Читать далее

Исследователи предлагают инновационный метод автоматической генерации разнообразных и достоверных задач для оценки возможностей больших языковых моделей.

Новое исследование сопоставляет стратегии предотвращения сговора, применяемые в экономике и юриспруденции, с задачами управления многоагентными системами искусственного интеллекта.