Зрячий агент: новый подход к поиску объектов на изображениях

Исследователи разработали систему, которая активно анализирует изображения, чтобы находить редкие объекты, не полагаясь на сложные языковые модели.
Исследователи разработали систему, которая активно анализирует изображения, чтобы находить редкие объекты, не полагаясь на сложные языковые модели.
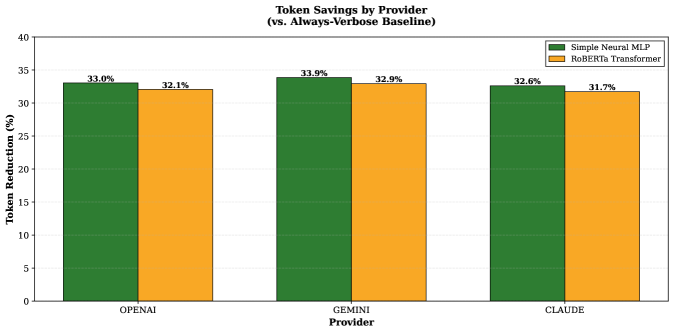
Новый подход к динамическому выбору шаблонов позволяет снизить стоимость работы с большими языковыми моделями, не жертвуя качеством генерируемого текста.

Новое исследование показывает, как крупные языковые модели справляются с ограничениями, связанными с орфографией, при решении словесных головоломок.
Новый подход позволяет переносить мощные трехмерные модели искусственного интеллекта на устройства с ограниченными ресурсами, открывая возможности для применения в реальном времени.
Новый подход к построению предварителей алгебраической многосеточной схемы позволяет существенно повысить скорость решения систем линейных уравнений, возникающих при дискретизации эллиптических уравнений методом изогометрического анализа.

Исследователи разработали метод и инструмент для выявления потенциально небезопасных этапов в процессе рассуждений мультимодальных моделей, а не только оценки конечного результата.

Новое исследование анализирует, насколько точно и беспристрастно большие языковые модели воспроизводят культурные особенности в сгенерированных повествованиях.
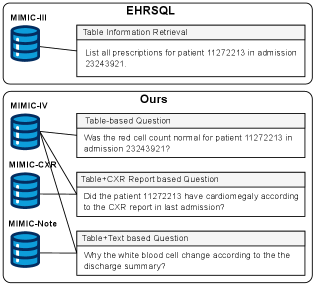
Новая разработка позволяет преобразовывать текстовые запросы врачей в SQL-запросы для работы с данными электронных медицинских карт, объединяя текстовую и табличную информацию.

Новый алгоритм позволяет быстрее и эффективнее извлекать полезную информацию из видеопотоков с камер наблюдения за дорожным движением.

В статье представлен инновационный метод реконструкции формы и свойств электромагнитных препятствий по данным рассеянного поля, основанный на глубоком обучении.