Большие языковые модели как судьи перевода: бюджет на размышления и калибровка реальности.

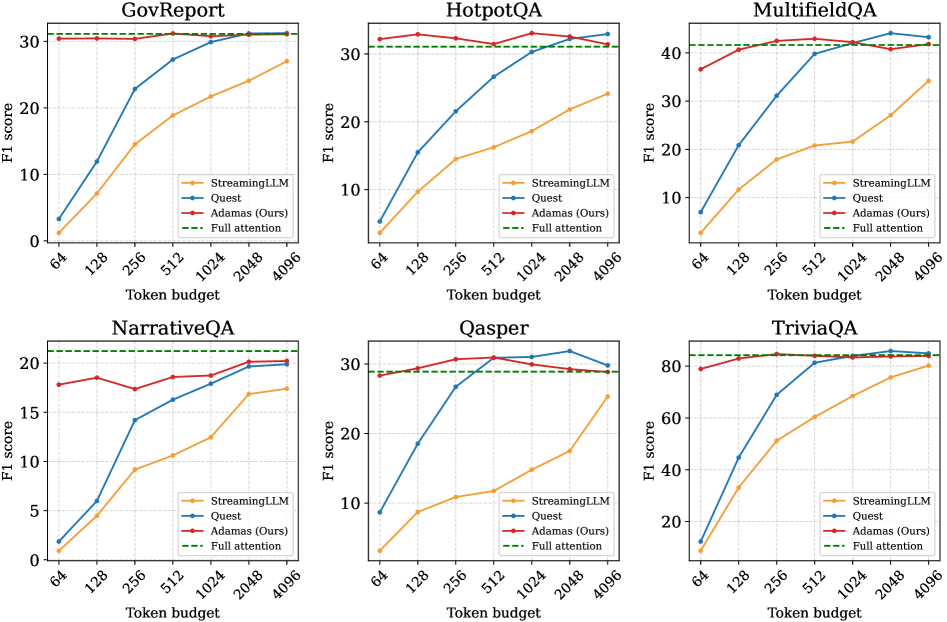
Уже давно стало аксиомой, что оценка машинного перевода требует колоссальных усилий человека, а автоматические метрики, как правило, далеки от реального восприятия качества. Но когда мы уже начали привыкать к этой рутине, появляется работа «Are Large Reasoning Models Good Translation Evaluators? Analysis and Performance Boost«, предлагающая взглянуть на проблему под новым углом – используя мощь больших языковых моделей не просто как генераторов, но и как судей. И возникает закономерный вопрос: действительно ли эти «разумные» модели способны объективно оценить нюансы перевода, или же мы просто возлагаем надежды на очередную технологическую иллюзию, скрывающую под собой всё те же старые ошибки?