Автор: Денис Аветисян
Новая система SimulatorCoder использует возможности больших языковых моделей для автоматической генерации и оптимизации кода симуляторов ускорителей глубокого обучения.
Представлена система, основанная на больших языковых моделях, для автоматического создания и оптимизации кода симуляторов DNN-ускорителей с использованием методов prompt engineering и chain-of-thought.
Разработка и оптимизация симуляторов для ускорителей глубоких нейронных сетей (DNN) традиционно требует значительных временных и трудовых затрат. В данной работе представлена система ‘SimulatorCoder: DNN Accelerator Simulator Code Generation and Optimization via Large Language Models’, использующая агента на основе больших языковых моделей (LLM) для автоматической генерации и оптимизации кода симуляторов по естественным описаниям. Эксперименты показывают, что предложенный подход позволяет создавать симуляторы, демонстрирующие высокую точность и производительность, сравнимую с ручной реализацией. Может ли автоматизация процесса разработки симуляторов на основе LLM существенно ускорить инновации в области аппаратного обеспечения для искусственного интеллекта?
Вызов Сложности: Оптимизация Ускорителей Глубоких Нейронных Сетей
Разработка и оптимизация ускорителей глубоких нейронных сетей (DNN) становится критически важной задачей в современной области искусственного интеллекта. Однако, традиционные методы проектирования, основанные на ручном анализе и итеративной настройке, сталкиваются с растущей сложностью. По мере увеличения масштабов DNN и разнообразия архитектур, ручное проектирование требует всё больше времени и ресурсов, становясь неэффективным и подверженным ошибкам. Поиск оптимальной конфигурации аппаратного обеспечения для конкретной нейронной сети требует учета множества факторов, включая пропускную способность памяти, вычислительные возможности и энергопотребление, что делает процесс крайне трудоемким и ограничивает возможности для инноваций в данной сфере.
Существующие инструменты оценки, такие как аналитические модели, зачастую оказываются неспособными адекватно отразить сложное взаимодействие между аппаратным и программным обеспечением при работе с глубокими нейронными сетями. Это приводит к неточностям в прогнозировании производительности, поскольку аналитические модели, как правило, упрощают реальные процессы, не учитывая такие факторы, как особенности кэш-памяти, конфликты доступа к памяти и динамическое изменение нагрузки. В результате, оптимизация аппаратных ускорителей для глубокого обучения становится более сложной и требует значительных затрат времени и ресурсов на экспериментальную проверку различных конфигураций, поскольку теоретические предсказания могут существенно отличаться от практических результатов. Недостаточная точность оценок затрудняет выбор оптимальной архитектуры и параметров аппаратного обеспечения для конкретной нейронной сети и задачи.
Автоматизация Симуляции: SimulatorCoder на Основе LLM
Представляем SimulatorCoder — агента на базе больших языковых моделей (LLM), предназначенного для автоматической генерации цикльно-точного симуляционного кода для ускорителей глубоких нейронных сетей (DNN). Система способна создавать код, моделирующий поведение аппаратного обеспечения на уровне тактов, что необходимо для точной оценки производительности и энергоэффективности разрабатываемых ускорителей. Генерация кода осуществляется посредством анализа архитектурных спецификаций и целевых показателей производительности, позволяя создавать симуляционные модели без ручного кодирования. SimulatorCoder ориентирован на автоматизацию процесса верификации и оптимизации аппаратных решений для задач машинного обучения.
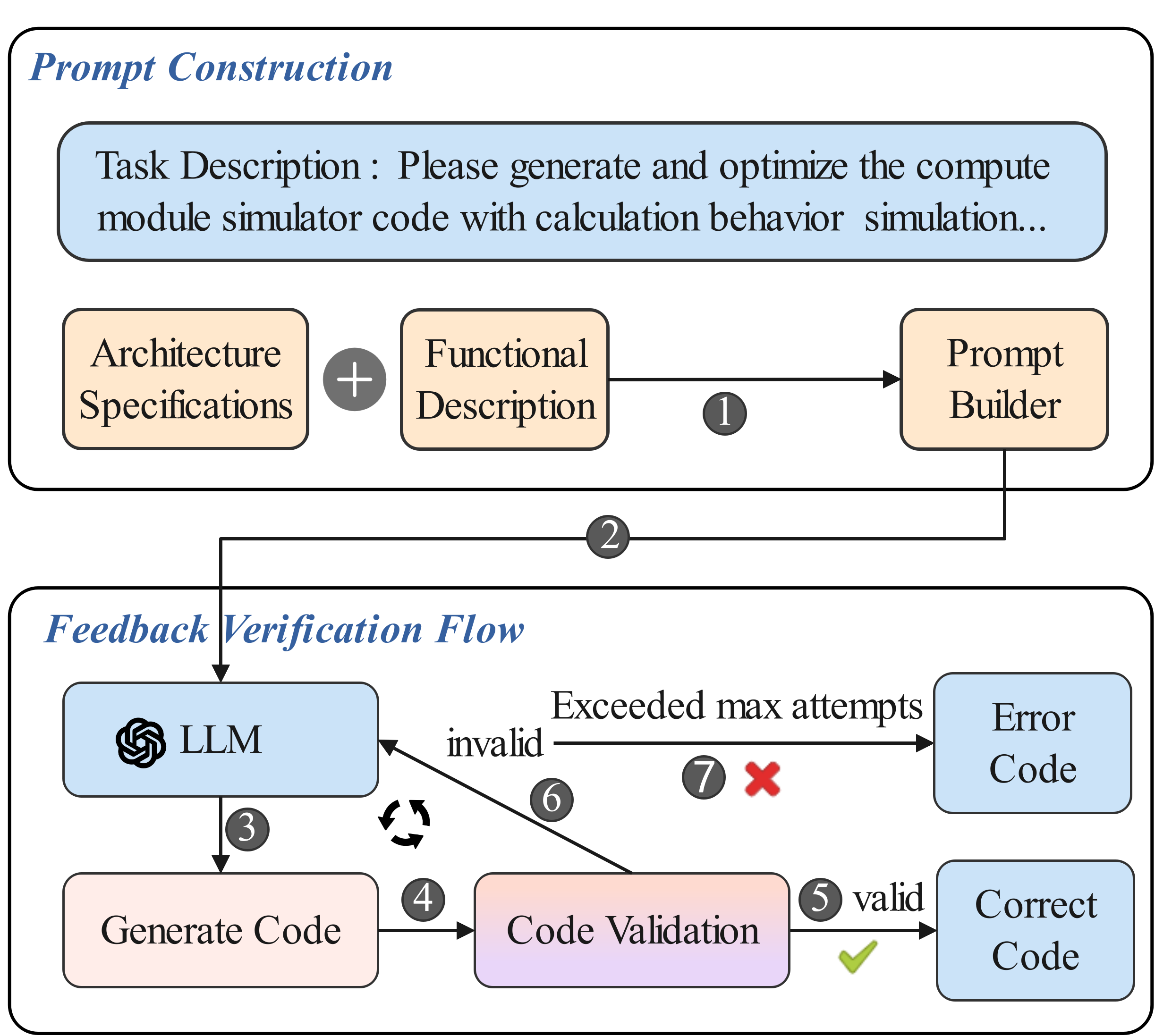
SimulatorCoder использует методику промт-инжиниринга для управления процессом генерации кода, что позволяет обеспечить соответствие генерируемого кода архитектурным спецификациям и целевым показателям производительности. В частности, промпты структурированы таким образом, чтобы явно указывать требования к архитектуре ускорителя, такие как ширина шины данных, размер кэша и организация памяти. Кроме того, промпты включают метрики производительности, такие как задержка и энергопотребление, которые служат ориентирами для оптимизации генерируемого кода. Использование детализированных и структурированных промптов позволяет LLM генерировать код, соответствующий заданным ограничениям и целям, минимизируя необходимость ручной корректировки и отладки.
Ключевым элементом системы является итеративный цикл обратной связи, предназначенный для улучшения сгенерированного кода симуляции. Этот цикл включает в себя запуск симуляции с использованием текущей версии кода, анализ результатов симуляции и сигналов об ошибках, и последующую корректировку кода на основе полученных данных. Процесс повторяется до достижения требуемого уровня точности и соответствия архитектурным спецификациям. Получаемые сигналы об ошибках служат индикаторами несоответствий между ожидаемым и фактическим поведением симулятора, что позволяет агенту целенаправленно оптимизировать код и устранять обнаруженные дефекты. Данный подход обеспечивает автоматическую верификацию и улучшение качества сгенерированного кода.
Модульная Архитектура: Точность и Детализация Симуляции
Архитектура SimulatorCoder построена на базе модульных компонентов, включающих модуль отображения (Mapping Module), модуль межсоединений (Interconnection Network Module) и модуль хранения (Storage Module). Данный подход позволяет детально моделировать особенности потоков данных и вычислений в различных вычислительных системах. Модуль отображения отвечает за распределение операций по вычислительным блокам, модуль межсоединений — за маршрутизацию данных между ними, а модуль хранения — за управление доступом к памяти. Разделение на модули обеспечивает гибкость и масштабируемость системы, позволяя точно воспроизводить характеристики сложных архитектур и анализировать влияние различных параметров на производительность.
Для оценки SimulatorCoder использовался широкий спектр рабочих нагрузок, включающий глубокие нейронные сети (DNN) ResNet50, YOLOv2 и AlphaGo Zero. Данный подход позволил продемонстрировать адаптивность системы к различным архитектурам и сложностям DNN, а также подтвердить её точность в моделировании поведения этих сетей. Использование разнообразных рабочих нагрузок позволило оценить производительность SimulatorCoder в различных сценариях и подтвердить его применимость к широкому классу задач машинного обучения.
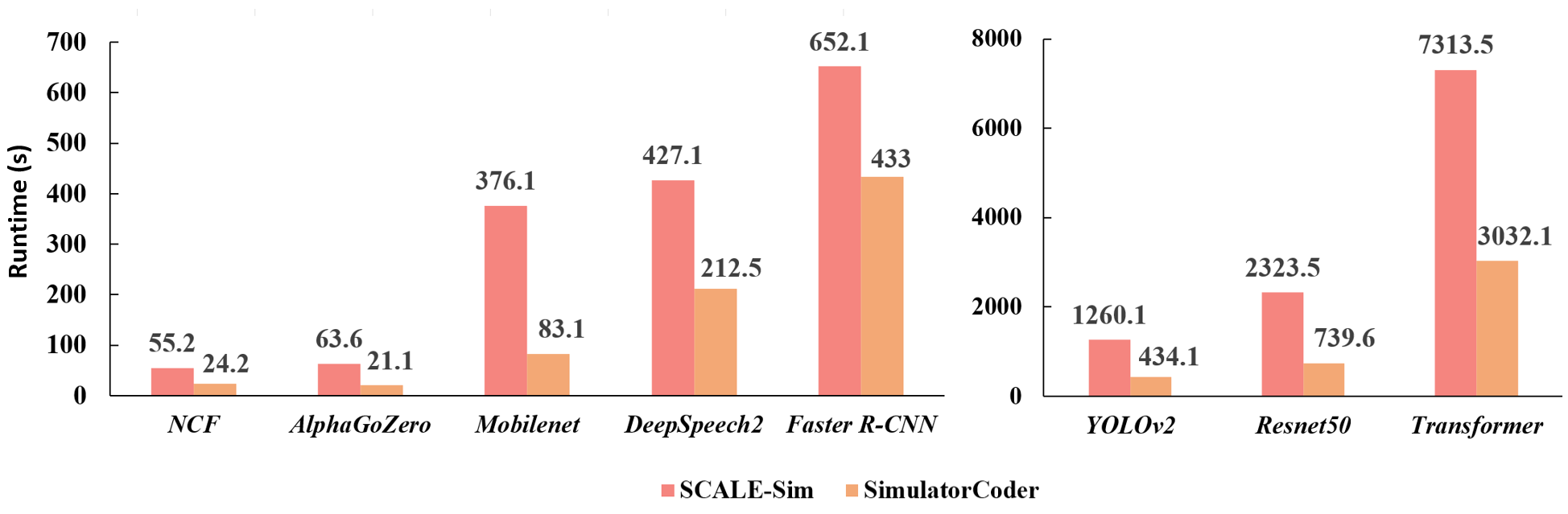
Для валидации производительности SimulatorCoder использовались большие языковые модели (LLM), такие как DeepSeek-V3 и GPT-4o. Оценка качества генерируемого кода проводилась с помощью метрики Pass@kk, которая показала последовательное улучшение результатов при использовании различных стратегий запросов. При сравнении с SCALE-Sim, SimulatorCoder демонстрирует погрешность в подсчете циклов менее 1% для восьми репрезентативных моделей. Для моделей NCF, AlphaGo Zero и YOLOv2 погрешность в подсчете циклов составила 0.00%, что подтверждает высокую точность симуляции и генерации кода.

Универсальность и Перспективы: От Простоты к Совершенству
Универсальность SimulatorCoder проявляется в его способности эффективно работать с широким спектром задач глубокого обучения. Исследования демонстрируют успешное применение данного инструмента для ускорения этапов проектирования в отношении таких архитектур, как Transformer, MobileNet, Neural Collaborative Filtering (NCF) и DeepSpeech2. Эта адаптивность существенно расширяет возможности исследователей и инженеров в области разработки нейронных сетей, позволяя им более оперативно исследовать различные конфигурации и оптимизировать производительность, значительно сокращая время, необходимое для поиска оптимальных решений в пространстве возможных вариантов.
Автоматизация процесса генерации симуляторов позволяет исследователям и инженерам сосредоточиться на инновациях в архитектуре и оптимизации производительности, значительно сокращая время разработки и связанные с ней затраты. В отличие от традиционных методов, SimulatorCoder не только упрощает создание симуляторов для различных типов глубоких нейронных сетей, включая Transformer, MobileNet и Neural Collaborative Filtering, но и зачастую демонстрирует более высокую скорость работы по сравнению с SCALE-Sim. Это достигается за счет эффективной автоматизации и оптимизации процесса моделирования, что позволяет быстрее оценивать различные варианты архитектур и находить оптимальные решения для аппаратного ускорения.
Дальнейшие исследования направлены на интеграцию аппаратных ограничений и моделей энергопотребления непосредственно в процесс симуляции. Это позволит создавать более реалистичные и всесторонние модели ускорителей, учитывающие не только производительность, но и практические аспекты, такие как тепловыделение и ограничения по питанию. Такой подход позволит разработчикам не просто оптимизировать архитектуру для скорости, но и проектировать энергоэффективные решения, полностью соответствующие требованиям реального оборудования и обеспечивающие баланс между производительностью и энергопотреблением.
Представленная работа демонстрирует стремление к предельной ясности в сложной области разработки чипов. Авторы, словно хирурги, удаляют избыточные абстракции, автоматизируя генерацию и оптимизацию кода симулятора DNN-ускорителей. Этот подход, основанный на больших языковых моделях, позволяет достичь высокой точности и эффективности. В этом контексте особенно уместна фраза Пауля Эрдеша: «Математика — это искусство не усложнять». Подобно тому, как математик стремится к элегантности решения, так и данное исследование направлено на упрощение процесса разработки, делая его более понятным и доступным, что является ключевым элементом для дальнейшего прогресса в области аппаратного обеспечения.
Что дальше?
Представленная работа демонстрирует, что автоматизация генерации кода для симуляторов DNN-ускорителей посредством больших языковых моделей — не просто техническая возможность, но и неизбежность. Однако, триумф автоматизации не должен заслонять собой остающиеся вопросы. Текущая реализация, будучи эффективной, ограничена рамками конкретной задачи — симуляции. Расширение области применения за пределы симуляторов, к непосредственному синтезу аппаратного обеспечения, представляется сложной, но необходимой целью. Оптимизация, достигнутая посредством LLM, не является универсальной; она контекстуальна и требует дальнейшего исследования методов адаптации к различным архитектурам и технологическим процессам.
Особое внимание следует уделить проблеме верификации. Автоматически сгенерированный код требует надежных методов проверки, превосходящих традиционные подходы. Простое сравнение результатов симуляций недостаточно; необходимы формальные методы верификации, способные гарантировать корректность и безопасность аппаратного обеспечения. Ирония заключается в том, что для контроля над автоматизированным процессом требуется еще более сложная автоматизация.
В конечном итоге, успех подобных систем зависит не только от мощности языковых моделей, но и от качества данных, на которых они обучаются. Разработка стандартизированных, хорошо документированных наборов данных для аппаратного дизайна представляется не менее важной задачей, чем совершенствование алгоритмов. И, возможно, самое сложное — это признать, что истинное упрощение достигается не добавлением сложности, а её осознанным удалением.
Оригинал статьи: https://arxiv.org/pdf/2602.17169.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Предел возможностей: где большие языковые модели теряют разум?
- Улучшение точности квантовых сенсоров: новый подход к подавлению шумов
- Резонансы в тандеме: Управление светом в микрорезонаторах
- Реальность и Кванты: Где Встречаются Теория и Эксперимент
- Моделирование спектроскопии электронного пучка: новый подход
- Квантовое программирование: Карта развивающегося мира
- За пределами стандартной точности: новая структура эффективной теории
- Сердце музыки: открытые модели для создания композиций
- Тандем топ-кварков и бозона Хиггса: новые горизонты точности
- Квантовый скачок: от лаборатории к рынку
2026-02-22 22:52