Автор: Денис Аветисян
В статье предлагается инновационная модель принятия решений для беспилотных автомобилей, использующая принципы квантовой теории игр для повышения безопасности и эффективности маневрирования.
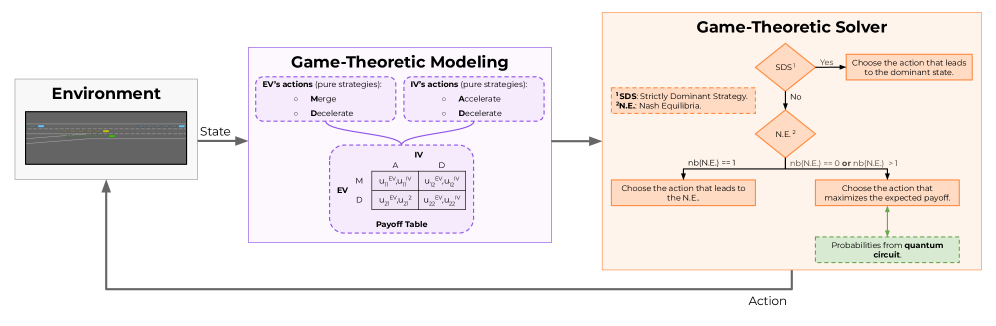
Разработана модель многопользовательской квантовой игры для учета взаимодействия между автономными транспортными средствами и оптимизации стратегий принятия решений.
Несмотря на значительный прогресс в области принятия решений для автономного вождения, адекватное моделирование взаимодействия с другими участниками дорожного движения остается сложной задачей. В данной работе, посвященной разработке ‘Multi-Player, Multi-Strategy Quantum Game Model for Interaction-Aware Decision-Making in Autonomous Driving’, предложена новая модель принятия решений, объединяющая принципы классической теории игр и квантовой механики для учета многопользовательских стратегий взаимодействия. Полученные результаты демонстрируют, что предложенный подход позволяет существенно повысить вероятность успешного маневра и снизить риск столкновений, особенно в условиях высокой плотности движения. Способна ли квантовая теория игр стать основой для создания действительно интеллектуальных и безопасных систем автономного вождения?
Изящный Вызов: Автономность в Неопределенности
Для достижения подлинной автономности транспортного средства недостаточно простого планирования маршрута. Эффективное управление требует надежных механизмов принятия решений в условиях неопределенности, поскольку реальный дорожный трафик характеризуется непредсказуемостью и сложностью. Автономная система должна не только определять оптимальный путь, но и оценивать риски, учитывать вероятные действия других участников движения и адаптироваться к меняющейся обстановке. Это предполагает разработку алгоритмов, способных обрабатывать неполную и противоречивую информацию, прогнозировать поведение окружающих и выбирать наиболее безопасные и эффективные действия, даже в ситуациях, когда идеальное решение отсутствует. В конечном итоге, надежность автономного вождения определяется способностью системы принимать обоснованные решения в сложных и непредсказуемых условиях, а не просто следовать заранее заданному плану.
Традиционные методы, используемые в системах автономного управления, зачастую испытывают трудности при моделировании сложных взаимодействий с другими участниками дорожного движения, что приводит к неоптимальным и даже небезопасным решениям. Эти подходы, как правило, сосредоточены на планировании собственного маршрута без достаточного учета намерений и возможных действий окружающих транспортных средств и пешеходов. В результате, автомобиль может совершать маневры, кажущиеся логичными с его точки зрения, но представляющие угрозу для других, или упускать возможности для более эффективного и безопасного передвижения. Неспособность адекватно прогнозировать поведение других агентов в динамичной среде существенно ограничивает возможности достижения подлинной автономности и требует разработки принципиально новых алгоритмов, способных учитывать многообразие возможных сценариев взаимодействия.
Для достижения полной автономности транспортных средств недостаточно простого планирования маршрута; критически важной является способность предвидеть действия других участников дорожного движения. Современные подходы к разработке систем автономного вождения зачастую не учитывают сложность взаимодействия с другими агентами, что приводит к неоптимальным и даже опасным ситуациям. Исследования показывают, что существующие алгоритмы, как правило, полагаются на упрощенные модели поведения, не способные адекватно отразить непредсказуемость реального дорожного трафика. Способность прогнозировать намерения других водителей, пешеходов и велосипедистов является ключевым фактором, определяющим безопасность и эффективность автономного вождения, и именно эта способность пока остается слабым местом большинства существующих систем.
Существующие системы автономного управления зачастую базируются на упрощенных моделях окружающей среды, что серьезно ограничивает их эффективность в реальных условиях. Эти модели, как правило, игнорируют сложность и непредсказуемость поведения других участников дорожного движения, а также динамические изменения в инфраструктуре и погодных условиях. В результате, алгоритмы, прекрасно работающие в лабораторных условиях, демонстрируют существенные трудности при столкновении с непредвиденными ситуациями на дороге. Например, система может неверно интерпретировать намерения пешехода или не учесть влияние скользкой дороги, что приводит к принятию неоптимальных или даже опасных решений. Поэтому, для достижения надежной автономии, необходима разработка более сложных и адаптивных моделей, способных учитывать все факторы, влияющие на поведение транспортного средства в динамичной среде.
Искусство Взаимодействия: Теория Игр для Интеллектуального Управления
Теория игр предоставляет формальный аппарат для описания стратегических взаимодействий, возникающих в сценариях автономного вождения. В контексте беспилотных автомобилей, каждое взаимодействие с другими транспортными средствами, пешеходами и инфраструктурой можно рассматривать как игру, где каждый участник преследует собственные цели и учитывает возможные действия других. Это позволяет формализовать такие ситуации, как обгон, проезд перекрестков, соблюдение дистанции и прогнозирование поведения других участников дорожного движения. Применение теории игр обеспечивает структурированный подход к анализу этих взаимодействий и разработке стратегий принятия решений для автономных систем, учитывающих рациональность и потенциальные реакции других агентов. Формализация взаимодействия через модели игры позволяет оценивать риски, оптимизировать поведение и обеспечивать безопасность в сложных дорожных условиях.
Представление взаимодействия между автономным транспортным средством и другими участниками дорожного движения в виде игр позволяет явно моделировать убеждения, намерения и потенциальные действия этих участников. В рамках данной модели, каждое транспортное средство или пешеход рассматривается как игрока, стремящегося к определенной цели. Убеждения моделируются как вероятностные оценки относительно намерений других игроков, а потенциальные действия — как набор доступных стратегий. Формализация этих элементов позволяет использовать математический аппарат теории игр для прогнозирования поведения и разработки стратегий принятия решений, учитывающих возможные реакции со стороны других участников дорожного движения. Например, при перестроении, система может оценить вероятность того, что соседний автомобиль ускорит или затормозит, и скорректировать свое действие соответствующим образом.
Классическая теория игр, в частности концепция равновесия Нэша, предоставляет основу для прогнозирования устойчивых стратегий взаимодействия между агентами. Однако, применительно к сложным и динамичным сценариям, таким как автономное вождение, стандартные методы часто оказываются недостаточными. Равновесие Нэша предполагает, что все участники взаимодействия знают стратегии друг друга и действуют рационально, что не всегда соответствует реальности. В условиях неполной информации, временных задержек и постоянного изменения окружающей среды, классические модели не способны адекватно отразить вероятностный характер действий и предсказать поведение агентов, особенно в ситуациях, требующих адаптации к непредсказуемым событиям. Это ограничивает их применимость к задачам, где необходимо учитывать неопределенность и динамику окружающей среды.
Интеграция теории игр с подходами, учитывающими взаимодействие, такими как частично наблюдаемые марковские процессы принятия решений (POMDP), позволяет создавать более сложные и адаптивные системы принятия решений. В то время как классическая теория игр предоставляет инструменты для анализа статических стратегий и предсказания равновесий, POMDP позволяют моделировать неопределенность и динамику взаимодействия с другими участниками дорожного движения, учитывая неполную информацию о их намерениях и состоянии. Комбинирование этих подходов позволяет агенту не только прогнозировать вероятные действия других, но и оценивать их влияние на собственную стратегию, оптимизируя решения в реальном времени и адаптируясь к изменяющимся условиям. Это особенно важно в сложных сценариях, где поведение других участников непредсказуемо или зависит от действий самого агента.
Квантовый Скачок: Новая Парадигма в Стратегическом Взаимодействии
Квантовая теория игр расширяет классическую теорию игр путем интеграции принципов квантовой механики, таких как суперпозиция и запутанность. В классической теории игр стратегии игроков определены однозначно, тогда как в квантовой версии стратегии представляются как квантовые состояния, что позволяет игроку находиться в суперпозиции нескольких стратегий одновременно. Это достигается путем представления стратегий как векторов в гильбертовом пространстве, а вероятности выбора стратегии определяются квадратом амплитуды соответствующего вектора. Запутанность, в свою очередь, позволяет создать корреляции между стратегиями игроков, которые невозможны в классической теории. Математически это выражается использованием операторов плотности ρ для описания смешанных стратегий и применением унитарных преобразований для моделирования эволюции стратегий в процессе игры.
Принцип суперпозиции в квантовой теории игр позволяет агентам одновременно рассматривать несколько стратегий, в отличие от классической теории игр, где агент выбирает одну конкретную стратегию. Это достигается путем представления стратегий агента в виде квантовых состояний, что позволяет им находиться в когерентной комбинации этих стратегий до момента измерения (принятия решения). В результате, агент может оценить потенциальные исходы, соответствующие всем возможным стратегиям, параллельно, что потенциально повышает эффективность и устойчивость процесса принятия решений, особенно в сложных и неопределенных сценариях. Использование суперпозиции позволяет агентам избегать локальных оптимумов и находить глобально оптимальные решения, недоступные в классических моделях.
Формализм Эйзерта-Вилькенса-Льюэнштейна (EWL) представляет собой конкретный протокол для реализации квантовой теории игр в сценариях автономного вождения. Он основан на представлении стратегий игроков в виде квантовых состояний и использовании унитарных преобразований для моделирования эволюции игры. Протокол EWL позволяет игрокам использовать квантовую суперпозицию и запутанность для достижения более эффективных стратегий, чем в классических играх. В контексте автономного вождения, этот протокол может быть использован для моделирования взаимодействия между несколькими автономными транспортными средствами, например, при принятии решений о слиянии, обгоне или объезде препятствий. Ключевым элементом является представление действий каждого транспортного средства в виде квантовых битов (кубитов) и использование квантовых гейтов для реализации стратегий принятия решений, что позволяет исследовать пространства стратегий, недоступные в классической теории игр. Реализация протокола EWL требует использования квантовых вычислений или их эмуляции на классических компьютерах.
Применение принципов квантовой механики в теории игр позволяет моделировать ситуации с неполной информацией и иррациональным поведением участников, что значительно повышает реалистичность процесса принятия решений. В классической теории игр предполагается, что игроки обладают полной информацией о стратегиях и выигрышах оппонентов, и действуют рационально, максимизируя свою выгоду. Квантовое моделирование позволяет учитывать вероятностные стратегии, основанные на суперпозиции состояний, где игрок одновременно рассматривает несколько вариантов действий. Это особенно актуально в сценариях, где информация ограничена или ненадежна, а поведение игроков подвержено когнитивным искажениям или эмоциям. Использование квантовых стратегий позволяет создавать более сложные и правдоподобные модели взаимодействия, что важно для анализа и прогнозирования поведения в различных областях, включая экономику, политику и искусственный интеллект.
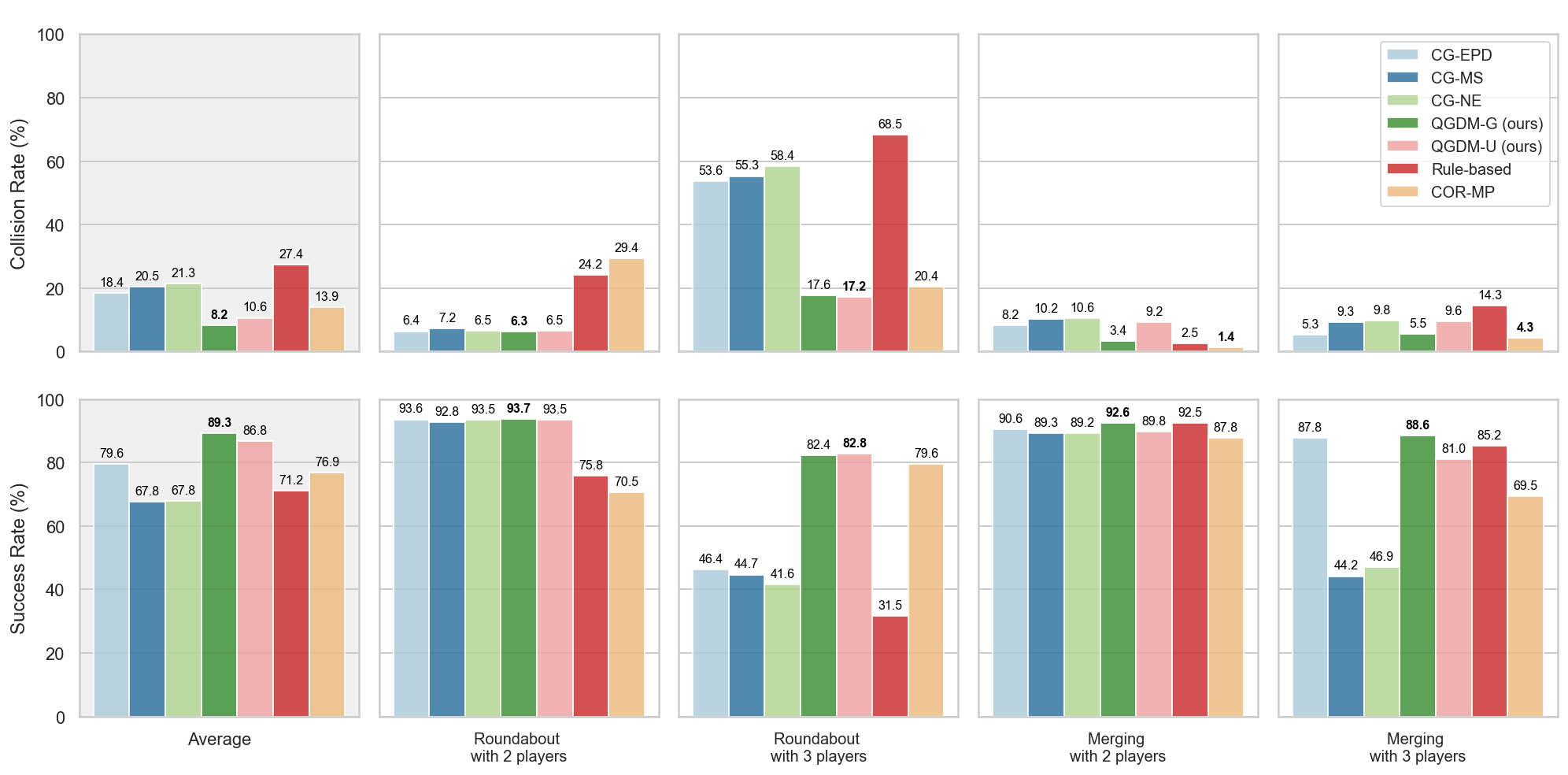
Симуляция и Валидация в Сложной Среде: Подтверждение Эффективности
Для всестороннего тестирования предложенной структуры принятия решений, основанной на квантовой теории игр, используется симулятор Highway-Env, предоставляющий высокореалистичную и сложную среду моделирования дорожного движения. Этот симулятор позволяет создавать разнообразные сценарии, включающие различные типы транспортных средств, погодные условия и дорожные ситуации, что позволяет оценить эффективность алгоритмов в условиях, максимально приближенных к реальным. Highway-Env генерирует динамичные и непредсказуемые взаимодействия между участниками дорожного движения, создавая серьезные вызовы для систем автономного управления и обеспечивая надежную платформу для проверки их способности к адаптации и принятию оптимальных решений в сложных условиях. Реалистичность симулятора заключается в детальной проработке физических моделей движения, поведения водителей и инфраструктуры, что позволяет получить достоверные результаты и оценить потенциал квантовой теории игр для повышения безопасности и эффективности автономных транспортных средств.
Для создания реалистичных функций полезности, отражающих предпочтения водителей, была предпринята интеграция модели сохранения ресурсов (Conservation of Resources Model) в рамки квантовой теории игр. Данный подход позволяет учитывать не только непосредственные выгоды от маневра, но и “стоимость” ресурсов, таких как время, энергия и риск, которые водитель неявно оценивает при принятии решений. Модель сохранения ресурсов, применяемая к планированию маневров, позволяет определить, какие действия водитель сочтет наиболее предпочтительными, учитывая ограниченность ресурсов и необходимость их эффективного использования. В контексте квантовой теории игр, это приводит к более точному моделированию поведения участников дорожного движения и позволяет разрабатывать стратегии, учитывающие не только рациональные, но и психологические аспекты принятия решений, что повышает реалистичность симуляций и позволяет более эффективно оценивать разработанные системы автономного управления.
Для эффективной подготовки агентов к навигации в сложных дорожных ситуациях и оптимизации стратегий принятия решений применяются методы Монте-Карло поиска по дереву (Monte Carlo Tree Search) и обучение с подкреплением (Reinforcement Learning). Монте-Карло поиск по дереву позволяет агенту исследовать различные варианты действий, оценивая их потенциальную выгоду посредством многократных симуляций. Обучение с подкреплением, в свою очередь, позволяет агенту совершенствовать свои навыки посредством получения вознаграждения за правильные действия и наказания за ошибки. Сочетание этих методов обеспечивает агентам возможность адаптироваться к динамично меняющимся условиям дорожного движения, эффективно планировать маневры и принимать оптимальные решения, направленные на повышение безопасности и эффективности вождения. Данный подход позволяет агентам не только осваивать базовые навыки вождения, но и разрабатывать сложные стратегии, учитывающие различные факторы, такие как поведение других участников дорожного движения и ограничения дорожной инфраструктуры.
Экспериментальные исследования, проведенные в симулированной среде сложного дорожного движения, демонстрируют значительный потенциал применения квантовой теории игр для улучшения ключевых характеристик автономных транспортных средств. Полученные результаты указывают на возможность повышения безопасности за счет более точного прогнозирования действий других участников движения, оптимизации траекторий для минимизации рисков столкновений и повышения общей эффективности вождения. Кроме того, разработанный подход демонстрирует повышенную устойчивость к неопределенностям и помехам в дорожной обстановке, что критически важно для надежной работы автономных систем в реальных условиях. Повышенная способность к адаптации и принятию оптимальных решений в сложных сценариях подтверждает перспективность использования квантовой теории игр для создания более безопасных, эффективных и надежных автономных транспортных средств.
Исследование, представленное в данной работе, демонстрирует стремление к созданию более совершенных систем принятия решений для автономных транспортных средств. Авторы предлагают подход, объединяющий классическую и квантовую теорию игр, что позволяет учитывать взаимодействие с другими участниками дорожного движения и преодолевать ограничения традиционных методов. Как отмечал Джон Маккарти: «Искусственный интеллект — это изучение того, как сделать так, чтобы машины вели себя разумно». Эта фраза отражает суть представленной работы — стремление к созданию интеллектуальных систем, способных эффективно взаимодействовать в сложных условиях, а именно, учитывать поведение других агентов для достижения оптимального равновесия Нэша в процессе планирования маневров.
Куда дальше?
Предложенная модель, объединяющая классическую и квантовую теорию игр, безусловно, открывает новые перспективы для планирования маневров автономных транспортных средств. Однако, следует признать, что взаимодействие с другими участниками дорожного движения, даже смоделированное с применением самых передовых инструментов, остается областью, полной непредсказуемости. Акцент на равновесии Нэша, хотя и оправдан, не гарантирует оптимального решения в ситуациях, когда поведение агентов отклоняется от рациональности — а такое случается, как показывает опыт, значительно чаще, чем хотелось бы.
Будущие исследования, вероятно, будут сосредоточены на преодолении этой разницы между теоретическими моделями и реальным миром. Интересным направлением представляется интеграция методов машинного обучения, позволяющих транспортному средству адаптироваться к непредсказуемому поведению других участников движения. Не менее важным представляется разработка более эффективных алгоритмов для учета неопределенности и риска, а также для оценки стоимости различных стратегий в условиях ограниченной информации.
В конечном итоге, хорошая архитектура незаметна, пока не ломается, и только тогда видна настоящая цена решений. Представленная работа — важный шаг вперед, но истинная проверка ждет впереди — на дорогах, где взаимодействие с другими — это не математическая игра, а реальность, полная неожиданностей и компромиссов.
Оригинал статьи: https://arxiv.org/pdf/2602.03571.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Самообучающиеся агенты: новый подход к автономным системам
- BOOM: Визуальный перевод лекций: новый уровень доступности
- Визуальное мышление машин: проверка на прочность
- Искусственный интеллект в медицине: новый уровень самостоятельности
- Графы и действия: новый подход к планированию для роботов
- Многокритериальная оптимизация: взгляд на народные методы
- Квантовые хроники: Последние новости в области квантовых исследований и разработки.
- Языковые барьеры рушатся: новые горизонты многоязыкового перевода
2026-02-04 19:01