Автор: Денис Аветисян
Исследователи представили систему DrivePI, объединяющую возможности анализа изображений, языка и действий для более точного понимания дорожной обстановки и безопасного управления автомобилем.
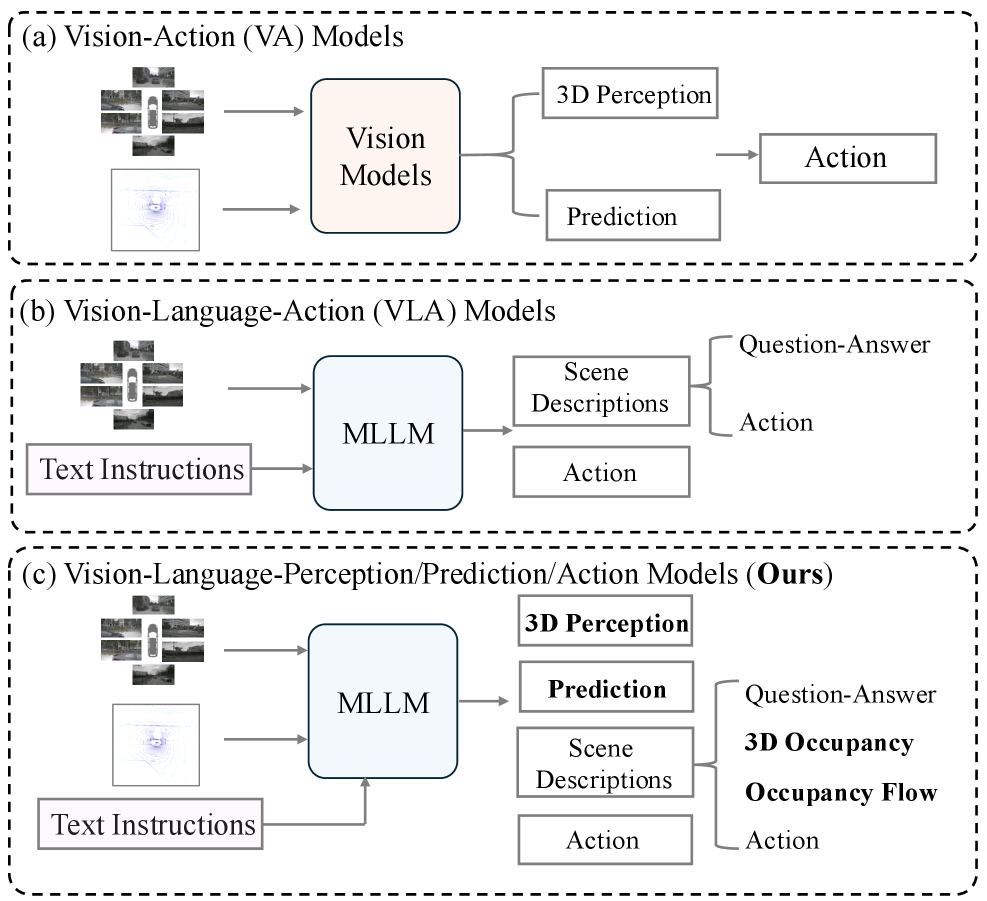
DrivePI — это компактная (0.5 млрд параметров) мультимодальная платформа, объединяющая визуальное восприятие, языковое понимание и планирование траектории для автономного вождения.
Несмотря на успехи мультимодальных больших языковых моделей в различных областях, их применение для детального 3D-восприятия и прогнозирования в задачах автономного вождения остаётся недостаточно изученным. В настоящей работе представлена система DrivePI — инновационный 4D MLLM, объединяющий пространственное понимание, 3D-восприятие, прогнозирование и планирование в единую архитектуру Vision-Language-Action. Достигнуто превосходство над существующими VLA и специализированными VA моделями, причем с компактной моделью MLLM всего в 0.5B параметров. Возможно ли дальнейшее масштабирование и оптимизацию DrivePI для создания полностью автономных и безопасных транспортных средств?
Понимание Окружения: От Восприятия к Рассуждению
Традиционные системы автономного вождения сталкиваются с серьезными трудностями при объединении богатого восприятия окружающей среды с процессами высокоуровневого рассуждения и планирования. В существующих архитектурах часто наблюдается разделение на отдельные конвейеры для обработки сенсорных данных и принятия решений, что препятствует адекватному реагированию на сложные и непредсказуемые дорожные ситуации. Эта фрагментация приводит к задержкам в обработке информации и снижает способность транспортного средства к оперативному принятию взвешенных решений, особенно в условиях ограниченной видимости или при наличии большого количества динамических объектов. В результате, системы оказываются неспособными эффективно интерпретировать контекст и предвидеть потенциальные опасности, что ограничивает их надежность и безопасность в реальных условиях эксплуатации. Необходимость интеграции этих двух ключевых компонентов — восприятия и планирования — является центральной задачей в развитии действительно автономных транспортных средств.
В существующих системах автономного вождения часто наблюдается разделение процессов восприятия окружающей среды и планирования действий, что создает значительные трудности при взаимодействии со сложными дорожными ситуациями. Вместо единой, интегрированной системы, информация от датчиков, таких как камеры и лидары, обрабатывается в отдельном конвейере восприятия, после чего результаты передаются в модуль планирования. Такое разделение приводит к задержкам в обработке информации и затрудняет оперативное реагирование на неожиданные события, ведь планировщик не получает мгновенный и полный доступ к текущей картине мира. В результате, система может испытывать трудности при интерпретации неоднозначных ситуаций, принятии быстрых решений и адаптации к динамично меняющимся условиям, что снижает общую безопасность и эффективность автономного вождения.
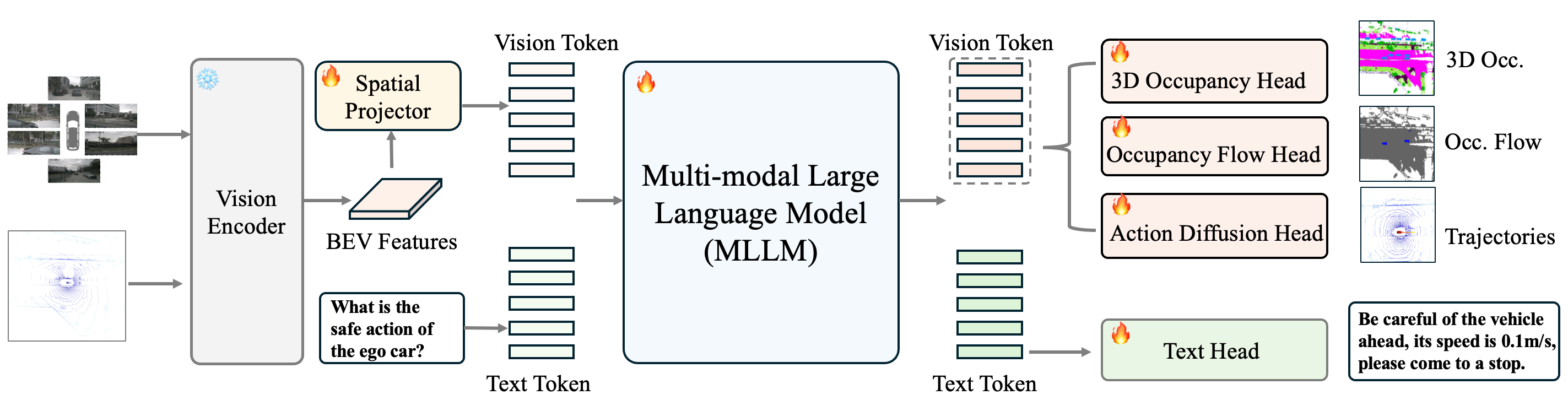
DrivePI: Объединяя Восприятие и Язык для Автономности
DrivePI представляет собой новую структуру, использующую мультимодальные большие языковые модели (MLLM) для объединения визуального восприятия и лингвистического рассуждения. В отличие от традиционных систем, обрабатывающих визуальную и текстовую информацию раздельно, DrivePI интегрирует эти модальности в единую нейронную сеть. Это позволяет модели не только распознавать объекты и сцены на изображениях и данных LiDAR, но и генерировать осмысленные описания и делать прогнозы, основанные на понимании контекста и взаимосвязей между элементами сцены. Такой подход обеспечивает более полное и эффективное представление окружающей среды для задач автономной навигации и взаимодействия с миром.
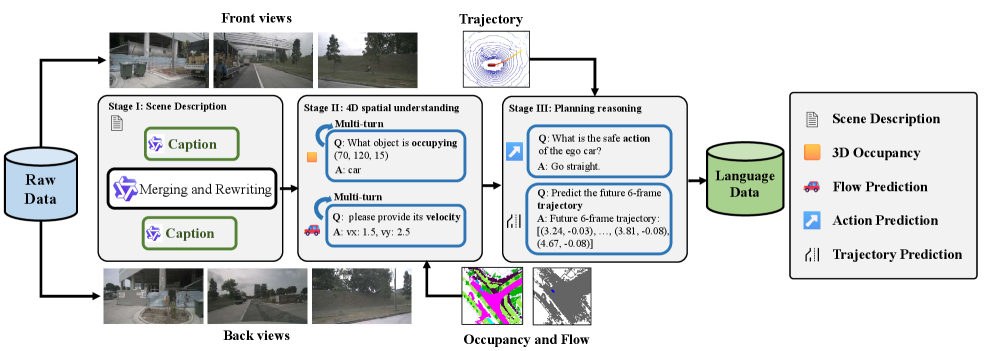
В рамках DrivePI, интеграция данных лидара и визуальных признаков позволяет формировать детальные описания окружения и прогнозы развития ситуации. Данные лидара предоставляют точную трехмерную информацию о геометрии объектов и их расположении, в то время как визуальные признаки дополняют картину, предоставляя информацию о текстурах, цветах и категориях объектов. Комбинируя эти данные, DrivePI генерирует комплексные представления сцены, необходимые для принятия обоснованных решений в задачах автономного вождения и робототехники. Представления включают в себя не только статичные характеристики окружения, но и динамические параметры, такие как скорость и траектории движения других участников дорожного движения, что повышает точность прогнозирования и безопасность системы.
В основе архитектуры DrivePI лежат большие мультимодальные языковые модели Qwen2.5 и InternVL3, обеспечивающие обработку и генерацию как визуальной, так и текстовой информации. Qwen2.5 специализируется на обработке текста и генерации ответов, в то время как InternVL3 отвечает за восприятие и анализ визуальных данных, включая изображения и данные LiDAR. Интеграция этих моделей позволяет DrivePI эффективно сопоставлять визуальные признаки с лингвистическими описаниями, что необходимо для понимания сцены и прогнозирования поведения объектов. Модели используют архитектуру трансформеров для обработки данных, обеспечивая масштабируемость и эффективность в задачах пространственного восприятия и лингвистического анализа.
Детальное Понимание Сцены: Занятость, Поток и Траектории
Архитектура DrivePI включает в себя три специализированных модуля — 3D Occupancy, Occupancy Flow и Action Diffusion — для точного анализа сцены и прогнозирования. Модуль 3D Occupancy отвечает за предсказание пространственной компоновки окружения, определяя занятые и свободные области. Occupancy Flow прогнозирует динамику движения объектов в пространстве, отслеживая их перемещение. Action Diffusion, используя механизм DiffusionDrive, обеспечивает надежное планирование действий и предсказание траекторий в сложных ситуациях, что позволяет системе понимать и предвидеть поведение объектов в сцене.
В архитектуре DrivePI для анализа и прогнозирования сцены используется специализированный модуль 3D Occupancy, базирующийся на методах, таких как FlashOcc, который предсказывает пространственную компоновку окружения. Параллельно функционирует модуль Occupancy Flow, предназначенный для прогнозирования динамики движения объектов в пространстве. Вместе эти модули обеспечивают комплексное понимание сцены, определяя не только статичную структуру, но и прогнозируя перемещения объектов, что критически важно для планирования траектории и безопасной навигации.
Прогнозирование траекторий в DrivePI осуществляется посредством Action Diffusion Head, использующего DiffusionDrive для надежного планирования в сложных сценариях. Данный модуль предсказывает будущие перемещения объектов, основываясь на анализе текущей сцены и вероятностном моделировании возможных траекторий. DiffusionDrive позволяет генерировать разнообразные и правдоподобные траектории, учитывая динамику окружающей среды и потенциальные взаимодействия между объектами. Метод обеспечивает устойчивость к шумам и неопределенностям, что критически важно для безопасного и эффективного автономного вождения в реальных условиях.
В архитектуре DrivePI, признаки BEV (Bird’s Eye View) играют ключевую роль в работе Spatial Projector — модуля, обеспечивающего связь между визуальной и текстовой информацией. Spatial Projector использует признаки BEV для проецирования визуальных данных в пространство, совместимое с текстовыми запросами и предсказаниями, что позволяет системе эффективно интерпретировать сцену и планировать действия. Эти признаки, полученные из визуального потока, кодируют пространственную информацию об окружающей среде и передаются в модуль, где они объединяются с текстовым вводом для формирования комплексного понимания ситуации.
Фреймворк DrivePI, основанный на многомодальной большой языковой модели (MLLM) с 0.5 миллиардами параметров, демонстрирует передовые результаты в задаче трехмерного понимания окружения. Согласно результатам тестирования, DrivePI достигает показателя RayIoU (Intersection over Union, измеренного с помощью лучей) в 46.0%, что на 4.8% превосходит существующие аналогичные системы. Данный показатель свидетельствует о высокой точности предсказания трехмерной занимаемой области, что критически важно для задач автономной навигации и робототехники.

К Интеллектуальным Автономным Агентам: Новый Взгляд на Автономность
Система DrivePI значительно расширяет возможности 4D многомодальных больших языковых моделей (MLLM), выводя не только текстовое описание сцены, но и трехмерные данные об занятости пространства и потоках движения. Этот подход представляет собой существенный прогресс в области пространственно-временного рассуждения, поскольку позволяет модели не просто “видеть” окружение, но и прогнозировать его динамику. Вместо статического анализа изображения, DrivePI создает детальную карту окружения с учетом перемещения объектов и потенциальных препятствий, что критически важно для автономной навигации и принятия решений в реальном времени. Такое сочетание лингвистического понимания и пространственного анализа открывает новые возможности для создания по-настоящему интеллектуальных автономных агентов, способных эффективно взаимодействовать со сложными окружающими средами.
Система DrivePI совершает значительный шаг к более естественному взаимодействию автономных агентов с дорожной обстановкой, объединяя прогнозы о пространственном расположении объектов и их движении с лингвистическим планированием. Этот подход позволяет не просто “видеть” окружающий мир, но и формировать осмысленные описания и планы действий, которые можно интерпретировать как человекоподобные. Благодаря этому, DrivePI способна не только предсказывать поведение других участников дорожного движения, но и обосновывать свои собственные маневры, делая процесс управления автомобилем более предсказуемым и понятным для окружающих. Такое сочетание пространственного и лингвистического интеллекта открывает перспективы для создания действительно интеллектуальных автономных систем, способных эффективно и безопасно функционировать в сложных городских условиях.
Эффективность системы DrivePI была тщательно проверена на общепризнанных эталонных наборах данных, таких как OpenOcc и nuScenes Dataset, что подтверждает её применимость в реальных условиях эксплуатации. OpenOcc, ориентированный на оценку способности предсказывать трехмерную занятость пространства, позволил оценить точность модели в понимании геометрии окружения. В свою очередь, nuScenes Dataset, содержащий сложные сценарии вождения в реальном мире, продемонстрировал способность DrivePI эффективно взаимодействовать с динамичной обстановкой. Результаты, полученные на этих наборах данных, не только подтверждают теоретическую обоснованность подхода, но и указывают на перспективность его использования в разработке автономных транспортных средств и других интеллектуальных агентов, способных ориентироваться в сложных, непредсказуемых средах.
Система DrivePI демонстрирует значительное улучшение в прогнозировании динамической проходимости пространства, достигая средней абсолютной ошибки (mAVE) в 0.509 для оценки потока заполнения окружения. Этот показатель превосходит результаты, полученные с использованием предыдущих методов, на 0.047 единиц. Такая точность в предсказании свободных участков и потенциальных препятствий критически важна для безопасной и эффективной навигации автономных агентов, позволяя им принимать обоснованные решения в реальном времени и избегать столкновений. Улучшенное прогнозирование потока заполнения напрямую влияет на способность системы планировать траектории и взаимодействовать с окружающей средой, обеспечивая более плавное и предсказуемое поведение.
Система DrivePI продемонстрировала выдающиеся возможности в планировании траектории движения. В ходе тестирования удалось достичь показателя $L2$ ошибки в 0.40, что превосходит результат системы VAD на 0.03. При этом, вероятность столкновений составила всего 0.11%, что на 0.14% ниже, чем у модели OpenDriveVLA-7B. Данные результаты свидетельствуют о значительном прогрессе в обеспечении безопасности и эффективности автономной навигации, позволяя создавать более надежные и предсказуемые системы управления транспортными средствами.
Система DrivePI продемонстрировала впечатляющую способность к пониманию текста, достигая точности в 60.7% на бенчмарке nuScenes-QA. Этот результат превосходит показатели OpenDriveVLA-7B на 2.5%, что свидетельствует о значительном прогрессе в области обработки естественного языка для автономных агентов. Способность корректно интерпретировать текстовые запросы и инструкции критически важна для безопасной и эффективной навигации в сложных реальных условиях, позволяя системе адекватно реагировать на различные сценарии и принимать обоснованные решения.
Система DrivePI знаменует собой важный шаг на пути к созданию по-настоящему интеллектуальных автономных агентов, способных не только воспринимать окружающую среду, но и полноценно понимать её сложность. В отличие от предыдущих моделей, DrivePI объединяет возможности многомодального анализа с прогнозированием пространственных параметров и лингвистическим планированием, что позволяет агенту формировать более точные и обоснованные решения в динамичных условиях. Благодаря этому подходу, система демонстрирует значительные улучшения в задачах предсказания заполненности пространства и планирования траектории, а также в понимании текстовых запросов, приближая момент, когда автономные устройства смогут эффективно и безопасно взаимодействовать со сложным миром вокруг.
Исследование, представленное в данной работе, демонстрирует, как глубокое понимание пространственных закономерностей критически важно для создания эффективных систем автономного вождения. DrivePI, объединяя возможности визуального и языкового анализа, позволяет не только воспринимать окружающую среду, но и прогнозировать траектории движения, что соответствует принципам, заложенным в биологических системах ориентации. Как однажды заметила Фэй-Фэй Ли: «Искусственный интеллект должен помогать людям, а не заменять их». Эта фраза особенно актуальна в контексте автономного вождения, где система должна не просто имитировать действия человека, но и понимать их намерения и предвидеть возможные сценарии, используя строгую логику и креативные гипотезы для интерпретации визуальных данных.
Что дальше?
Представленная работа, несмотря на достигнутые успехи в области унифицированного восприятия, предсказания и планирования автономного вождения, лишь подчёркивает сложность истинного понимания пространства. Модель DrivePI, с её компактностью в 0.5 миллиарда параметров, демонстрирует впечатляющие результаты, но неизбежно сталкивается с ограничениями в обработке тонких нюансов реального мира. Вопрос не в увеличении количества параметров, а в разработке более элегантных алгоритмов, способных извлекать существенные признаки из многомерных данных.
Ключевым направлением дальнейших исследований представляется углублённое изучение принципов пространственного рассуждения. Необходимо выйти за рамки простого определения занятости пространства и перейти к пониманию намерений других участников дорожного движения, предвидению потенциальных опасностей и построению траекторий, учитывающих не только физические ограничения, но и социальные нормы. Интересно, сможет ли модель, лишенная телесного опыта, действительно «понять» контекст происходящего?
Очевидно, что будущее автономного вождения лежит в интеграции различных модальностей данных — не только зрения и языка, но и звука, тактильных ощущений, и даже, возможно, интуиции. Истинный прорыв произойдет тогда, когда машина научится не просто «видеть» мир, а «чувствовать» его, и действовать не по заданному алгоритму, а в соответствии с внутренней моделью реальности.
Оригинал статьи: https://arxiv.org/pdf/2512.12799.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовый оптимизатор: Новый подход к сложным задачам
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Квантовый взгляд на рак груди: новая точность диагностики
- 💸 Великобритания тратит 500 миллионов фунтов стерлингов на квантовые технологии – может быть, кот Шрёдингера только что разбогател?
- Кванты в Финансах: Не Шутка!
- Прогнозирование задержек контейнеров: Синергия ИИ и машинного обучения
- Взлом языковых моделей: эволюция атак, а не подсказок
2025-12-16 21:58