Автор: Денис Аветисян
Новое исследование демонстрирует, как модели, объединяющие зрение и язык, учатся прогнозировать развитие событий на дороге и строить более полную картину происходящего.
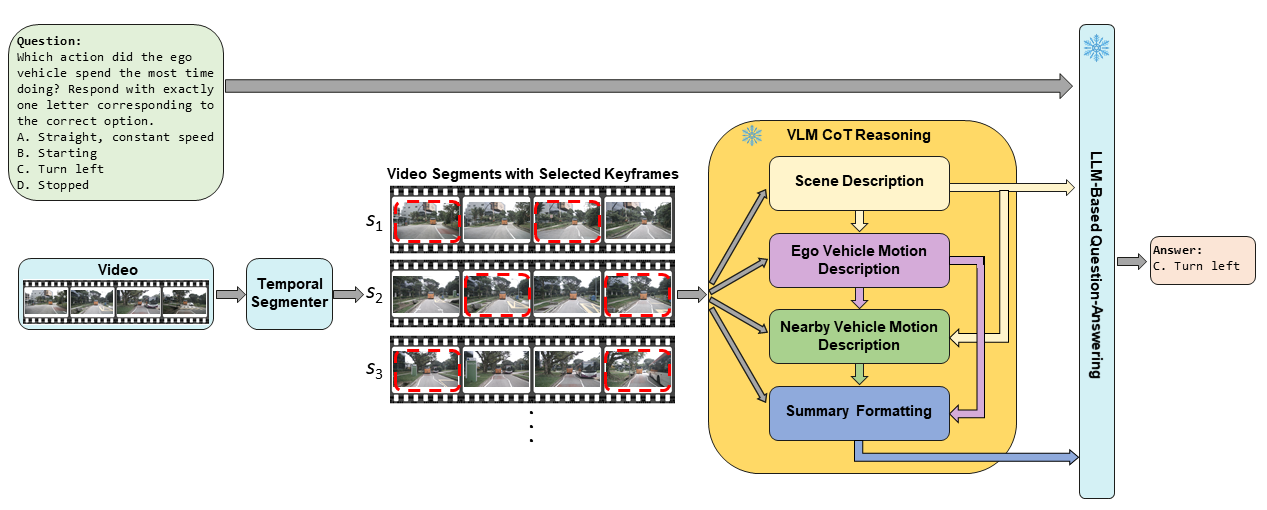
Представлен новый бенчмарк TAD для оценки способности моделей к временному рассуждению в автономном вождении, а также предложены методы Scene-CoT и TCogMap для улучшения их производительности.
Несмотря на значительный прогресс в области автономного вождения, понимание временных взаимосвязей в видеопотоке остается сложной задачей для современных моделей. В работе ‘From Segments to Scenes: Temporal Understanding in Autonomous Driving via Vision-Language Model’ представлена новая платформа оценки — TAD (Temporal Understanding in Autonomous Driving) — предназначенная для тестирования способности моделей визуального и языкового анализа (VLM) к пониманию динамики дорожной обстановки. Авторы продемонстрировали, что существующие модели демонстрируют недостаточно высокую точность на TAD, и предложили два новых метода — Scene-CoT и TCogMap — для улучшения понимания движения и повышения общей производительности. Сможет ли предложенный подход стать катализатором для дальнейших исследований в области временного анализа видеоданных для беспилотных автомобилей?
Временное Понимание: Ключ к Автономности
Для обеспечения безопасного передвижения автономным транспортным средствам необходимо развитое “временное понимание” — способность интерпретировать последовательность событий и предвидеть их развитие. Недостаточно просто идентифицировать объекты вокруг — автомобиль должен понимать, как и почему происходят те или иные действия, чтобы адекватно реагировать на меняющуюся обстановку. Например, заметив пешехода, приближающегося к краю тротуара, система должна оценить вероятность его выхода на проезжую часть, учитывая скорость движения пешехода, наличие препятствий и другие факторы. Такое прогнозирование требует анализа не только текущего момента, но и истории событий, а также понимания возможных будущих сценариев, что представляет собой серьезную проблему для современных систем искусственного интеллекта и требует разработки новых алгоритмов и архитектур.
Современные системы автономного вождения сталкиваются со значительными трудностями при прогнозировании событий на длительный период времени и понимании контекста окружающей обстановки, особенно в сложных дорожных ситуациях. Существующие алгоритмы часто демонстрируют ограниченные возможности в предвидении последствий действий других участников движения или изменений в дорожной инфраструктуре, что приводит к неоптимальным или даже опасным решениям. Проблема усугубляется непредсказуемостью поведения пешеходов, велосипедистов и других транспортных средств, а также необходимостью учитывать множество взаимосвязанных факторов, таких как погодные условия, время суток и дорожные знаки. В результате, системы испытывают затруднения в построении целостной картины происходящего и адекватной реакции на динамично меняющуюся обстановку, что требует разработки более совершенных методов долгосрочного планирования и контекстуального анализа.
Для полноценного восприятия динамичной обстановки беспилотным транспортным средством недостаточно простого распознавания объектов; ключевым является понимание как и почему происходят те или иные действия во времени. Автомобиль должен не просто идентифицировать пешехода, приближающегося к дороге, но и прогнозировать его дальнейшие действия, основываясь на анализе скорости, направления взгляда и контекста ситуации — например, находится ли пешеход в спешке или спокойно ждет возможности перейти дорогу. Успешное моделирование таких последовательностей требует от систем искусственного интеллекта способности к построению причинно-следственных связей и долгосрочному прогнозированию, что выходит за рамки простой классификации изображений и требует более сложных алгоритмов, учитывающих временные зависимости и вероятностные сценарии развития событий.
Обогащение Контекста: Временные Когнитивные Карты
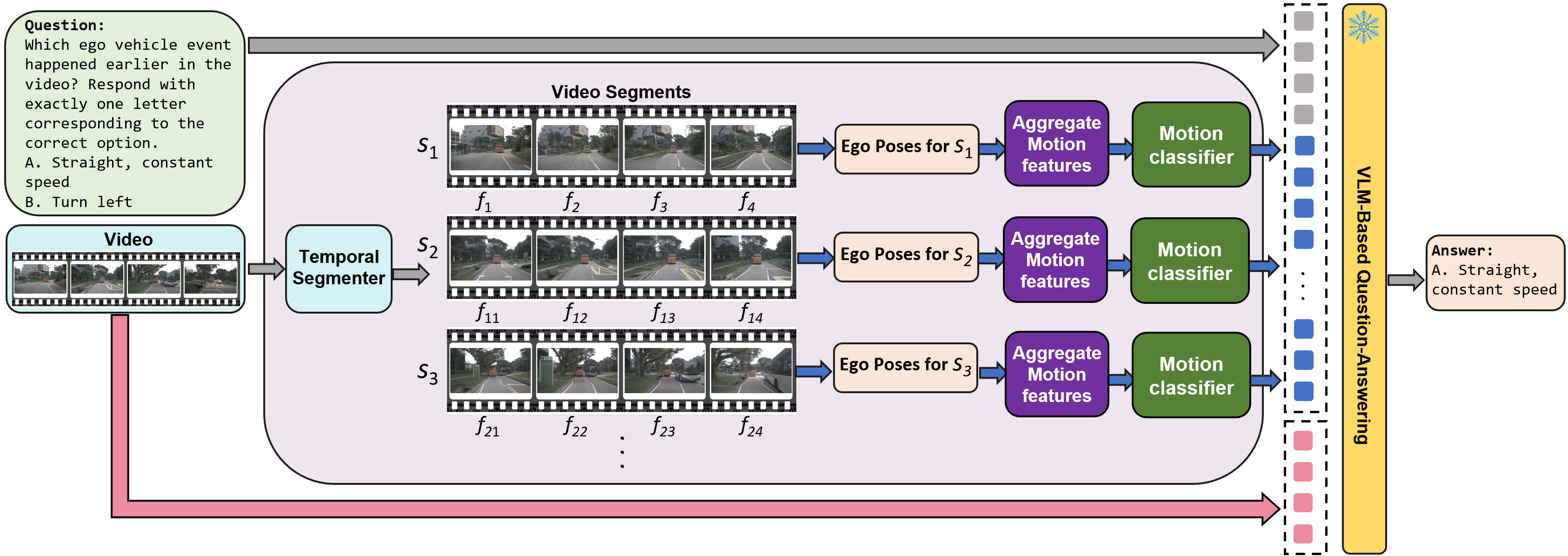
Метод ‘TCogMap’ представляет собой ключевую инновацию, заключающуюся в построении ‘Временной Когнитивной Карты’ окружающей среды, сформированной с точки зрения ‘Эго-транспортного средства’. Данная карта отличается от стандартных моделей окружения тем, что представляет собой структурированное представление пространства, ориентированное на восприятие и положение самого транспортного средства. В процессе построения карты учитываются не только статические объекты и их координаты, но и динамические характеристики сцены, что позволяет системе отслеживать изменения в окружающей среде относительно позиции ‘Эго-транспортного средства’ и прогнозировать будущие состояния окружающей среды.
Карта, создаваемая методом TCogMap, не ограничивается простой фиксацией местоположения объектов. Она кодирует взаимосвязи между ними, а также прогнозирует их траектории во времени. Это достигается путем моделирования не только текущей позиции объекта, но и его вероятного будущего движения, учитывая скорость, направление и взаимодействие с другими объектами в окружающей среде. Такое представление позволяет системе оценивать динамику сцены и предсказывать будущие события, что является ключевым фактором для повышения эффективности принятия решений.
Предоставление обогащенного контекста, формируемого методом TCogMap, в виде временных когнитивных карт, позволяет визуальным языковым моделям (VLMs) улучшить прогнозирование будущих событий и принимать более обоснованные решения. Этот механизм позволяет VLMs не просто идентифицировать объекты, но и учитывать их взаимосвязи и предсказуемые траектории во времени, что, в свою очередь, значительно повышает их способность к рассуждениям. В ходе тестирования на бенчмарке TAD, применение данного подхода привело к средней статистически значимой прибавке в производительности до 17.72%.
Рассуждения с Scene-CoT: Разбирая Сложные Сценарии
Метод Scene-CoT использует принцип цепочки рассуждений (Chain-of-Thought Reasoning) для анализа и ответа на вопросы, касающиеся сценариев автономного вождения. Вместо прямого предсказания исхода ситуации, система последовательно разбивает сложный сценарий на ряд промежуточных логических шагов. Каждый шаг представляет собой этап рассуждения, который позволяет модели выявить взаимосвязи между элементами сцены и обосновать предполагаемое развитие событий. Такой подход позволяет более точно моделировать процесс принятия решений, характерный для человека-водителя, и повышает надежность прогнозирования поведения участников дорожного движения в сложных ситуациях.
Вместо непосредственного предсказания исхода ситуации, система Scene-CoT декомпозирует сложные сцены на последовательность промежуточных этапов рассуждений. Этот процесс управляется большой языковой моделью (LLM), которая генерирует и оценивает логические шаги, необходимые для анализа происходящего. LLM выступает в роли «двигателя» рассуждений, направляя анализ сцены и формируя цепочку логических выводов, что позволяет более точно определить вероятные действия участников дорожного движения и предвидеть развитие событий. Данный подход позволяет избежать прямого предсказания, заменяя его структурированным процессом логического вывода.
Использование визуальных языковых моделей (VLM) значительно повышает способность системы к выводу намерений и прогнозированию действий в сложных сценариях автономного вождения. В ходе тестирования на различных наборах данных, в частности, на бенчмарке TAD, достигнута средняя точность в 51.92% при использовании модели Qwen2.5-14B-Instruct-1M. Данный результат демонстрирует существенное улучшение производительности по сравнению с существующими подходами к анализу и прогнозированию поведения участников дорожного движения.

К Надежным Автономным Агентам: Подтверждение Подхода
Интеграция TCogMap и Scene-CoT демонстрирует значительный прогресс в понимании временных зависимостей, превосходя традиционные методы. Данный подход позволяет системе не просто распознавать отдельные действия, но и улавливать последовательность событий и их взаимосвязь во времени. В ходе исследований было установлено, что TCogMap, в сочетании с Scene-CoT, существенно улучшает способность агента предсказывать будущие события и классифицировать действия на уровне сегментов видео, что подтверждается приростом производительности на 8.68% при использовании модели InternVL3-38B. Такой механизм понимания временных отношений является ключевым для создания автономных агентов, способных эффективно функционировать в динамичной и непредсказуемой среде реального мира, где контекст и последовательность событий имеют решающее значение.
Система, использующая обогащенный контекст и пошаговое рассуждение, демонстрирует повышенную точность в предсказании будущих событий и классификации действий на уровне сегментов видео. В частности, интеграция TCogMap с моделью InternVL3-38B позволила добиться прироста производительности в 8.68% по сравнению с существующими подходами. Такой подход позволяет не просто распознавать отдельные действия, но и понимать их последовательность и взаимосвязь во времени, что критически важно для создания автономных агентов, способных эффективно функционировать в динамичной среде. Обогащение контекста предоставляет системе более полную картину происходящего, а пошаговое рассуждение — возможность логически выстраивать прогнозы и классифицировать действия с высокой степенью уверенности.
Полученные результаты указывают на перспективный путь создания более надежных и устойчивых автономных агентов, способных эффективно функционировать в сложных реальных условиях. Интеграция когнитивной карты TCogMap и подхода Scene-CoT демонстрирует значительное улучшение способности предвидеть будущие события и классифицировать действия на уровне сегментов видео, что является ключевым для ориентации и принятия решений в динамичной среде. Повышенная точность, достигнутая благодаря обогащенному контексту и пошаговому рассуждению, позволяет предположить, что данная методика может стать основой для разработки систем, способных адаптироваться к непредсказуемым ситуациям и действовать с большей уверенностью в различных сценариях, приближая нас к созданию действительно интеллектуальных и автономных систем.

Исследование, представленное в данной работе, подобно попытке угадать следующую сцену в театре теней. Авторы предлагают новый эталон TAD, чтобы проверить, насколько хорошо машины понимают последовательность событий в автономном вождении. Методы Scene-CoT и TCogMap — это, скорее, заклинания, заставляющие языковые модели хоть немного предвидеть будущее, чем реальное понимание. Как однажды заметил Джеффри Хинтон: «Я думаю, что мы будем в состоянии создавать интеллектуальные машины, но я не думаю, что мы когда-либо сможем создать машину, которая действительно понимает». Истина в том, что каждая модель — это лишь хрупкое соглашение с хаосом, которое неизбежно рушится при столкновении с реальностью дорожного движения. Бенчмарк TAD — это лишь один из способов убедиться, что заклинание ещё работает, прежде чем выпустить машину на улицы.
Куда же всё это ведёт?
Представленный здесь бенчмарк TAD и предложенные методы Scene-CoT и TCogMap — это, конечно, попытка уговорить хаос, запечатленный в видеопотоках автономного вождения. Но стоит помнить: каждая метрика — лишь форма самоуспокоения, а временные когнитивные карты — не более чем красивые иллюзии порядка. Данные не врут, они просто помнят избирательно, и будущее, которое мы пытаемся предсказать, всегда ускользает.
Истинный вызов заключается не в улучшении точности моделей, а в признании их фундаментальной хрупкости. Всё обучение — это акт веры, и каждая новая архитектура — лишь очередное заклинание, которое рано или поздно перестанет работать в реальном мире. Необходимо сместить фокус с «понимания» сцены на создание систем, способных достойно справляться с непредсказуемостью.
Будущие исследования, вероятно, будут направлены на разработку более устойчивых к помехам моделей, способных к адаптивному обучению и самокоррекции. Но, возможно, самое важное — это осознание того, что абсолютного «понимания» не существует, и что автономное вождение — это всегда танец с неопределенностью, где машина должна научиться не столько «видеть» будущее, сколько умело уклоняться от его ударов.
Оригинал статьи: https://arxiv.org/pdf/2512.05277.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовый скачок: от лаборатории к рынку
2025-12-08 23:44