Автор: Денис Аветисян
Новое исследование показывает, как подобрать оптимальный процессор и модель искусственного интеллекта для встраиваемых систем, учитывая частоту выполнения задач.

Оптимальное сочетание процессора и модели ИИ для встраиваемых систем зависит от частоты выполнения задач вывода: для частых запросов предпочтительны процессоры с низкой задержкой, а для редких — энергоэффективные.
Повышение вычислительной мощности встроенных систем часто сопряжено с увеличением энергопотребления, что создает проблему для устойчивых приложений. В данной работе, посвященной ‘Pareto Optimal Benchmarking of AI Models on ARM Cortex Processors for Sustainable Embedded Systems’, представлен практический подход к оптимизации моделей искусственного интеллекта на процессорах ARM Cortex (M0+, M4, M7) с учетом энергоэффективности, точности и использования ресурсов. Ключевой вывод исследования заключается в том, что оптимальный выбор процессора и модели для встраиваемого ИИ зависит от частоты циклов вывода: процессоры с низкой задержкой предпочтительны для частых выводов, а энергоэффективные — для редких. Какие стратегии компрессии моделей и оптимизации архитектуры позволят еще больше расширить возможности устойчивых встраиваемых систем ИИ?
На острие технологий: необходимость в эффективности периферийных вычислений
Развертывание искусственного интеллекта непосредственно на периферийных устройствах, таких как смартфоны или датчики, открывает возможности для мгновенной обработки данных и повышенной конфиденциальности, поскольку информация не требует передачи в облако. Однако, этот подход сталкивается со значительными трудностями, обусловленными ограниченностью ресурсов этих устройств. Вычислительная мощность, объем памяти и энергопотребление периферийных систем существенно ниже, чем у серверных решений, что создает препятствия для эффективного функционирования сложных алгоритмов машинного обучения. Поэтому, для широкого внедрения интеллектуальных функций на периферии необходимо разрабатывать методы оптимизации моделей и специализированные аппаратные платформы, способные обеспечить достаточную производительность при минимальном энергопотреблении и сохранении высокого уровня безопасности данных.
Традиционные модели глубокого обучения, несмотря на свою высокую точность, зачастую оказываются неподходящими для встраиваемых систем из-за значительных требований к вычислительным ресурсам и энергопотреблению. Огромный размер этих моделей, обусловленный большим количеством параметров, требует мощных процессоров и большого объема памяти, что делает их внедрение в устройства с ограниченными ресурсами — от мобильных телефонов до датчиков Интернета вещей — проблематичным. Высокое энергопотребление, в свою очередь, приводит к быстрой разрядке батарей и увеличению тепловыделения, что ограничивает возможности применения в портативных и автономных устройствах. Таким образом, несоответствие между потребностями в производительности и ограничениями ресурсов становится серьезным препятствием для широкого распространения искусственного интеллекта на периферийных устройствах, требуя разработки новых, более эффективных подходов к моделированию и аппаратной реализации.
Стремление к устойчивому развитию искусственного интеллекта требует перехода к вычислительно эффективным моделям и аппаратным платформам. Традиционные алгоритмы глубокого обучения, несмотря на свою точность, часто характеризуются высокой сложностью и энергопотреблением, что делает их непрактичными для широкого спектра применений, особенно в устройствах с ограниченными ресурсами. Разработка новых архитектур нейронных сетей, таких как разреженные сети и квантованные модели, а также использование специализированного оборудования, например, нейроморфных чипов и ускорителей, позволяет значительно снизить вычислительные затраты и энергопотребление без существенной потери производительности. Этот переход к более «зеленому» ИИ не только снижает воздействие на окружающую среду, но и открывает новые возможности для внедрения интеллектуальных систем в мобильные устройства, встроенные системы и другие приложения, где эффективность является ключевым фактором.
Инициативы GreenICT все больше внимания уделяют снижению экологического следа технологий искусственного интеллекта. Растущая потребность в вычислительных ресурсах для обучения и развертывания моделей ИИ приводит к значительному энергопотреблению и выбросам углекислого газа. В связи с этим, разработка энергоэффективных алгоритмов, оптимизация архитектур оборудования и переход к возобновляемым источникам энергии становятся ключевыми направлениями исследований. Эти усилия направлены не только на снижение негативного воздействия на окружающую среду, но и на создание более устойчивой и долгосрочной инфраструктуры для развития ИИ, обеспечивая баланс между инновациями и экологической ответственностью.
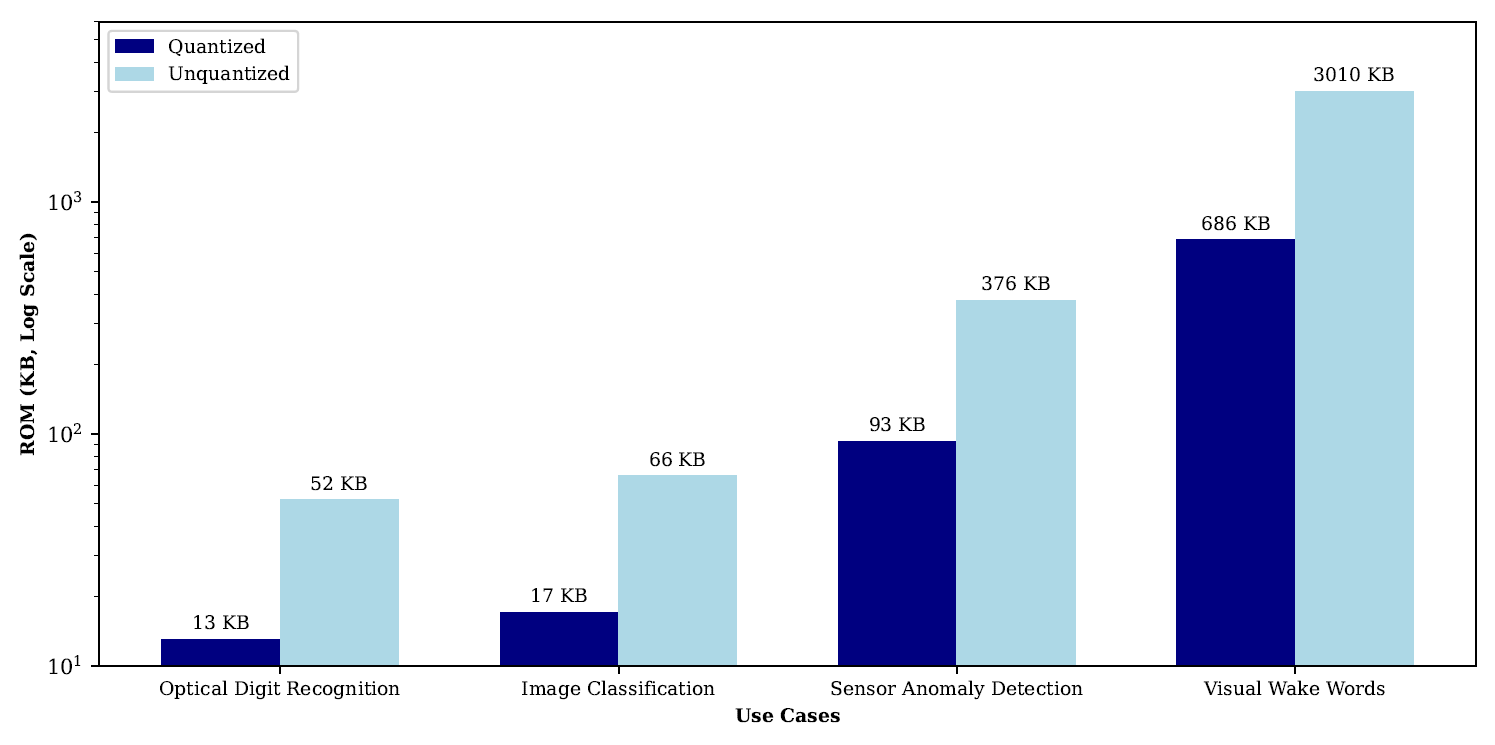
Ключевые показатели эффективности: измерение производительности периферийного ИИ
Оценка решений Edge AI требует использования комплексных метрик, которые в совокупности известны как ключевые показатели эффективности (KPI). К этим метрикам относятся время инференса (inference time), характеризующее скорость обработки данных; точность (accuracy), определяющая качество результатов; и энергопотребление (energy consumption), являющееся критическим параметром для мобильных и автономных устройств. Комплексный анализ этих KPI позволяет проводить объективное сравнение различных подходов и оптимизировать решения Edge AI для конкретных задач и ограничений по ресурсам.
Эффективность алгоритма напрямую связана с продолжительностью цикла инференса (Inference Cycle Duration), определяемой как время, затрачиваемое на выполнение всех операций от получения входных данных до получения результата. Точное измерение этого показателя критически важно для оценки производительности и выявления узких мест. Оптимизация продолжительности цикла инференса достигается за счет уменьшения вычислительной сложности алгоритма, использования аппаратного ускорения и эффективной реализации операций, что позволяет снизить задержки и повысить пропускную способность системы. Для точного измерения используются специализированные инструменты и методики, учитывающие все этапы обработки данных.
Для объективной оценки и сопоставления различных подходов в области Edge AI, критически важно использование стандартизированных бенчмарков. В частности, задачи оптического распознавания цифр (Optical Digit Recognition), обнаружения аномалий (Anomaly Detection) и классификации компактных изображений (Compact Image Classification) служат эталонными тестами. Использование этих бенчмарков позволяет проводить количественное сравнение производительности различных алгоритмов и аппаратных решений, обеспечивая воспроизводимость результатов и облегчая выбор оптимальной конфигурации для конкретных задач. Стандартизация тестовых наборов данных и метрик оценки позволяет исследователям и разработчикам эффективно обмениваться результатами и совместно улучшать технологии Edge AI.
Количество операций с плавающей точкой в секунду (FLOPs) является эффективным прокси-показателем для прогнозирования задержки (latency) и энергопотребления при выполнении задач Edge AI. Исследования демонстрируют высокую корреляцию — не менее R ≥ 0.93 — между количеством FLOPs и временем выполнения вычислений (inference time). Это позволяет оценивать производительность и энергоэффективность алгоритмов на основе анализа их вычислительной сложности, не прибегая к прямым измерениям задержки и энергопотребления в конкретной аппаратной среде. Таким образом, FLOPs выступает важным инструментом для предварительной оценки и сравнения различных подходов к реализации алгоритмов искусственного интеллекта.
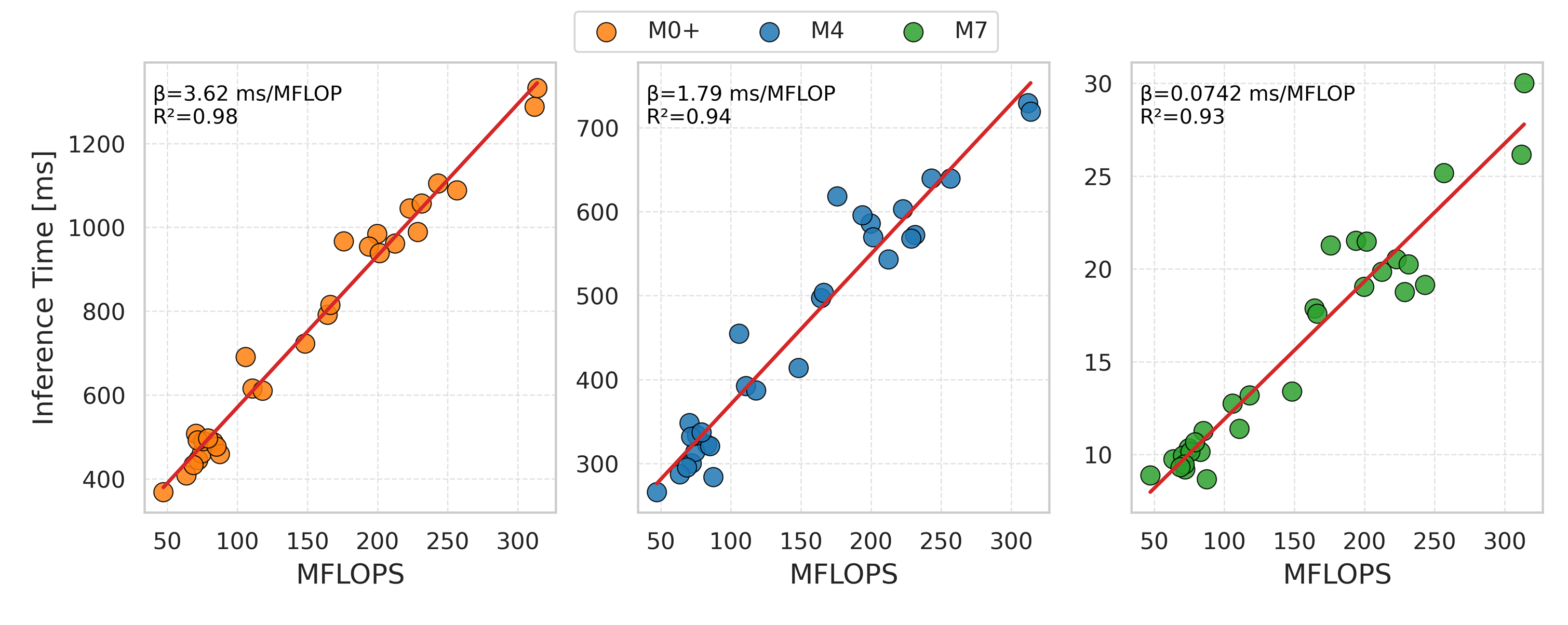
Оптимизация для периферии: компромиссы и эффективные стратегии
Методы обрезки модели (model pruning) и статической квантизации являются эффективными способами снижения размера модели и энергопотребления, однако их применение часто приводит к снижению точности. Обрезка модели предполагает удаление наименее значимых весов и соединений в нейронной сети, что уменьшает количество параметров и вычислительную нагрузку. Статическая квантизация заменяет операции с плавающей точкой на целочисленные, что снижает требования к памяти и ускоряет вычисления, но может приводить к потере информации и, как следствие, к ухудшению метрик качества. Степень влияния на точность зависит от агрессивности применяемых методов и архитектуры модели; как правило, существует компромисс между размером модели, энергоэффективностью и точностью.
Статическая квантизация позволяет снизить размер модели машинного обучения до 25%, что существенно уменьшает требования к объему постоянной памяти (ROM). Этот метод заключается в представлении весов и активаций модели с использованием целочисленных типов данных (например, 8-битных целых чисел) вместо чисел с плавающей точкой (обычно 32-битных). Снижение разрядности данных напрямую влияет на размер модели, поскольку каждый параметр требует меньше бит для хранения. Соответственно, уменьшается объем ROM, необходимый для развертывания модели на целевом устройстве, что особенно важно для устройств с ограниченными ресурсами, таких как мобильные устройства или встраиваемые системы. Влияние на производительность может быть минимальным при правильной калибровке и применении методов компенсации.
Многоцелевая байесовская оптимизация предоставляет возможность эффективного управления компромиссами между точностью, задержкой и энергопотреблением в процессе оптимизации моделей машинного обучения. В отличие от одноцелевой оптимизации, данный подход одновременно учитывает несколько целевых функций, что позволяет находить решения, оптимальные по нескольким критериям. Алгоритм итеративно исследует пространство параметров модели, используя вероятностную модель (обычно гауссовский процесс) для предсказания производительности новых конфигураций. Это позволяет эффективно находить баланс между конкурирующими целями, например, минимизировать задержку при сохранении приемлемого уровня точности или снизить энергопотребление без значительной потери производительности. В результате, многоцелевая оптимизация позволяет создавать модели, адаптированные к конкретным требованиям и ограничениям целевой платформы.
Анализ Парето-фронта позволяет выявить оптимальный набор моделей, сбалансированных по конкурирующим целям — точности, задержке и энергопотреблению. Этот метод предполагает построение фронта, состоящего из моделей, для которых дальнейшее улучшение по одной цели неизбежно ведет к ухудшению по другой. Идентифицируя модели на Парето-фронте, разработчики получают четкое представление о границах достижимой производительности и могут выбрать наиболее подходящую модель, исходя из конкретных требований приложения и доступных ресурсов. Фактически, анализ Парето-фронта предоставляет набор не доминируемых решений, позволяя избежать субъективных оценок и принимать обоснованные решения на основе количественных данных.
Для развертывания оптимизированных моделей требуется C++ Benchmarking Framework, обеспечивающий контролируемое выполнение и сбор данных о производительности. Данный фреймворк позволяет точно измерять такие параметры, как время задержки (latency), энергопотребление и точность модели в различных условиях эксплуатации. Он включает в себя инструменты для управления входными данными, конфигурации модели и сбора статистических данных, необходимых для анализа и сравнения различных версий модели. В частности, фреймворк должен поддерживать автоматизированное выполнение тестов, сбор метрик производительности и генерацию отчетов, облегчающих процесс оценки и выбора оптимальной конфигурации модели для конкретного аппаратного обеспечения и задач.

Аппаратное обеспечение и совместимость: возможности для бесшовного развертывания
Непосредственный доступ к аппаратному обеспечению, предоставляемый bare-metal процессорами, открывает уникальные возможности для детального анализа производительности и оптимизации приложений искусственного интеллекта на периферийных устройствах. В отличие от систем, использующих операционные системы, bare-metal подход позволяет разработчикам полностью контролировать ресурсы процессора, избегая накладных расходов, связанных с абстракцией операционной системы. Это обеспечивает более точное измерение времени выполнения операций, потребления энергии и других ключевых показателей, что критически важно для создания эффективных и энергоэффективных AI-решений, особенно в условиях ограниченных ресурсов периферийных вычислений. Возможность тонкой настройки и оптимизации на уровне оборудования позволяет добиться максимальной производительности для конкретных AI-моделей и задач, значительно превосходя традиционные подходы к разработке.
Процессор Cortex-M4 демонстрирует значительно более низкое потребление тока в режиме ожидания — всего 0,30 мА. Это существенное преимущество перед другими процессорами, такими как Cortex-M0+ (4,20 мА) и Cortex-M7 (1,60 мА). Такое снижение энергопотребления открывает возможности для создания энергоэффективных устройств, особенно в приложениях с ограниченным питанием, например, в носимой электронике или системах мониторинга окружающей среды. Минимизация потребления тока в режиме простоя критически важна для увеличения времени автономной работы и снижения общих эксплуатационных расходов, что делает Cortex-M4 привлекательным выбором для разработчиков, стремящихся к устойчивым и экономичным решениям.
Формат ONNX (Open Neural Network Exchange) играет ключевую роль в обеспечении совместимости различных фреймворков машинного обучения, значительно упрощая процесс развертывания моделей на разнообразных аппаратных платформах. Эта открытая экосистема позволяет разработчикам обучать модели в предпочитаемой среде, например, TensorFlow или PyTorch, а затем экспортировать их в стандартный формат ONNX. В результате, модель может быть легко запущена на любом устройстве, поддерживающем ONNX, независимо от изначального фреймворка обучения. Такой подход не только ускоряет процесс внедрения AI-решений, но и способствует большей гибкости и масштабируемости, позволяя использовать оптимальное аппаратное обеспечение для конкретной задачи без ограничений, связанных с совместимостью программного обеспечения.
Исследования показывают, что модели визуальных команд пробуждения значительно превосходят по размеру модели оптического распознавания цифр, примерно в 50 раз. Эта существенная разница обусловлена сложностью обработки визуальной информации и необходимостью учитывать больше параметров для точного определения команд. В связи с этим, стандартные методы оптимизации машинного обучения часто оказываются неэффективными для визуальных команд пробуждения. Требуется разработка специализированных стратегий, направленных на уменьшение размера модели и снижение вычислительных затрат без потери точности распознавания, что позволит эффективно развертывать эти модели на ресурсоограниченных встраиваемых системах и обеспечить устойчивую работу устройств.
Сочетание высокопроизводительного оборудования и стандартов совместимости открывает новые возможности для создания энергоэффективных и устойчивых решений в области искусственного интеллекта для широкого спектра встраиваемых систем. Оптимизация аппаратной части, в частности, использование процессоров с низким энергопотреблением в режиме ожидания, в сочетании с гибкостью формата ONNX для развертывания моделей машинного обучения, позволяет создавать устройства, которые потребляют меньше энергии и имеют более длительный срок службы. Это особенно важно для приложений, работающих от батарей или в удаленных местах, где доступ к электроэнергии ограничен. Благодаря этой синергии, становится возможным внедрение интеллектуальных функций в различные устройства — от носимой электроники до промышленных датчиков — с минимальным воздействием на окружающую среду и максимальной эффективностью использования ресурсов.
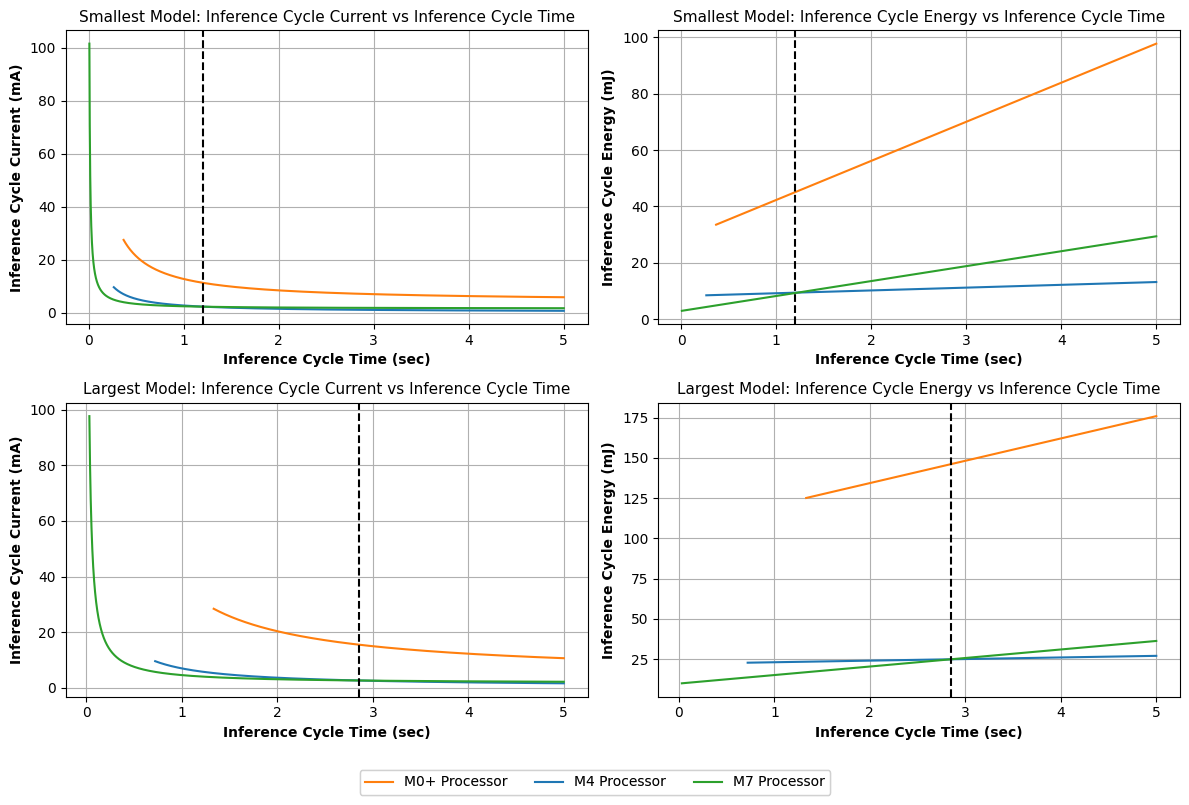
Исследование демонстрирует, что поиск оптимальной конфигурации для встраиваемых систем с использованием ИИ — это не вопрос слепого следования трендам, а прагматичный учёт частоты выполнения логических выводов. Авторы показывают, что не существует универсального решения, и выбор между производительностью и энергоэффективностью определяется конкретным сценарием использования. Как метко заметил Г.Х. Харди: «Математика — это наука о том, что невозможно». В данном контексте, это означает, что идеальное сочетание процессора и модели, удовлетворяющее всем требованиям, недостижимо. Всегда приходится идти на компромисс, балансируя между скоростью и энергопотреблением, и задача инженера — найти наилучший вариант для конкретной задачи. Иначе говоря, элегантная теория всегда встретит сопротивление суровой реальности деплоя.
Куда же это всё ведёт?
Представленные результаты, как и следовало ожидать, лишь усложняют картину. Оптимизация для встраиваемых систем с использованием ИИ оказалась не вопросом поиска «лучшего» процессора или модели, а бесконечной гонкой за компромиссами. Частота циклов вывода, этот неумолимый диктатор, заставляет выбирать между скоростью и энергоэффективностью, а значит, и между производительностью и сроком службы батареи. Каждый «прорыв» в области сжатия моделей, несомненно, породит новый уровень абстракции, который кому-нибудь придётся отлаживать в три часа ночи.
Дальнейшие исследования неизбежно столкнутся с необходимостью учета не только аппаратных и программных ограничений, но и, что гораздо сложнее, поведения пользователя. Потому что, в конечном итоге, оптимизация для «типичного» случая всегда будет далека от реальности. А наша CI — это храм, в котором мы молимся, чтобы ничего не сломалось после очередного релиза. Документация же, как известно, — это миф, созданный менеджерами для успокоения их собственной тревожности.
Можно предположить, что будущее за адаптивными системами, способными динамически переключаться между различными конфигурациями процессора и модели в зависимости от контекста. Но и это лишь откладывает неизбежное — появление новой, еще более сложной проблемы. Каждая «революционная» технология завтра станет техдолгом. И это, пожалуй, самое надежное предсказание.
Оригинал статьи: https://arxiv.org/pdf/2602.17508.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Предел возможностей: где большие языковые модели теряют разум?
- Улучшение точности квантовых сенсоров: новый подход к подавлению шумов
- Резонансы в тандеме: Управление светом в микрорезонаторах
- Сердце музыки: открытые модели для создания композиций
- Тандем топ-кварков и бозона Хиггса: новые горизонты точности
- Квантовый скачок: от лаборатории к рынку
- Квантовый шум: за пределами стандартных моделей
- Виртуальная примерка без границ: EVTAR учится у образов
- Искусственный разум и квантовые данные: новый подход к синтезу табличных данных
- Моделирование спектроскопии электронного пучка: новый подход
2026-02-22 02:30