Автор: Денис Аветисян
В новой работе представлена методика совместной разработки аппаратного и программного обеспечения для достижения оптимальной производительности больших языковых моделей непосредственно на пользовательских устройствах.
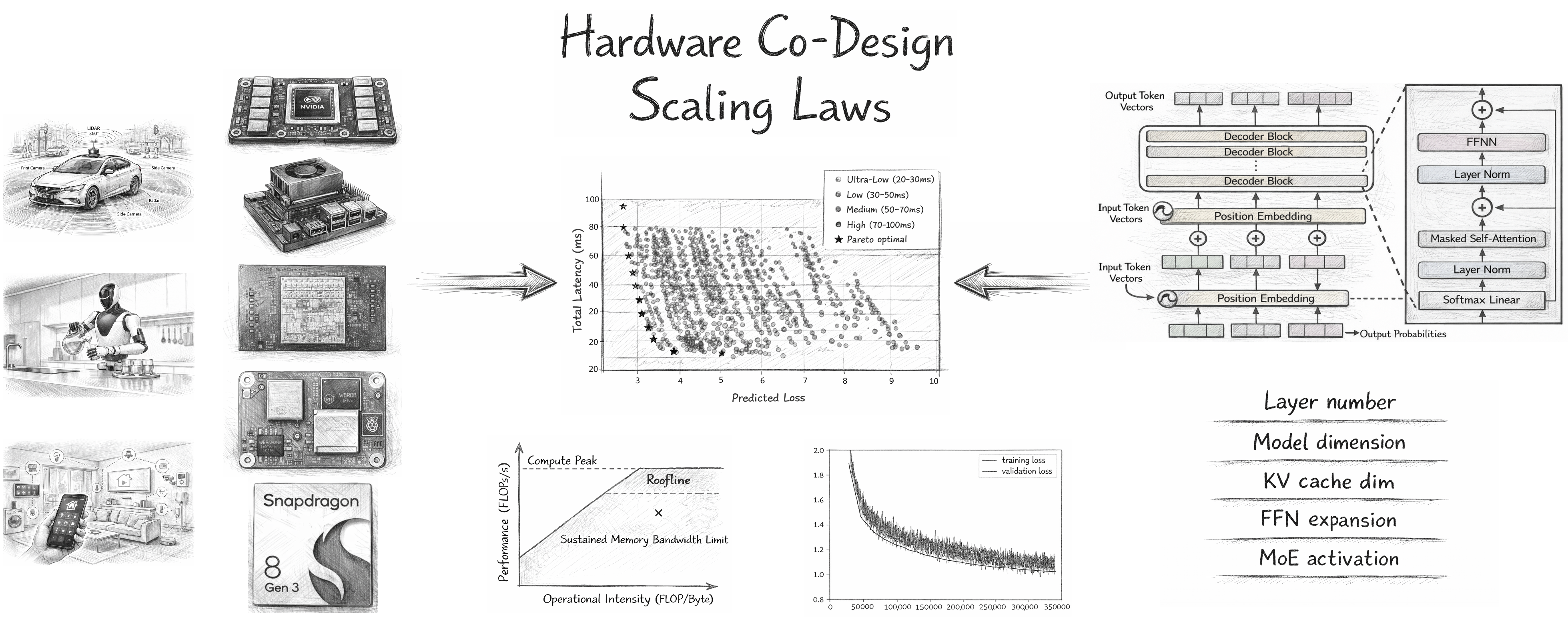
Исследование использует анализ Roofline и парето-оптимизацию для выявления наилучших архитектур, учитывающих ограничения аппаратной части и требования к точности.
Разработка эффективных моделей искусственного интеллекта для периферийных устройств требует компромисса между точностью и аппаратными ограничениями. В работе ‘Hardware Co-Design Scaling Laws via Roofline Modelling for On-Device LLMs’ предложен подход к совместному проектированию аппаратного и программного обеспечения, позволяющий выявить оптимальные архитектуры больших языковых моделей (LLM) для работы на устройствах. Авторы установили прямую связь между точностью, задержкой и архитектурными параметрами, используя анализ roofline и методы парето-оптимизации для создания моделей, превосходящих существующие аналоги по эффективности. Сможет ли предложенный фреймворк ускорить разработку и развертывание LLM для широкого спектра периферийных приложений?
Закономерности и Узкие Места в Больших Языковых Моделях
Несмотря на впечатляющую способность больших языковых моделей (БЯМ) обрабатывать и генерировать текст, их производительность часто ограничивается вычислительными узкими местами, возникающими как в процессе обучения, так и при практическом применении — инференсе. Эти ограничения связаны с тем, что для выполнения сложных операций, необходимых для работы БЯМ, требуется значительное количество вычислительных ресурсов, в особенности — пропускная способность памяти и интенсивность арифметических операций. Когда объемы данных и сложность моделей растут, эти узкие места становятся все более выраженными, замедляя скорость обработки и увеличивая задержки, что препятствует эффективному развертыванию БЯМ в реальных приложениях и ограничивает их масштабируемость. Поэтому, оптимизация вычислительной эффективности БЯМ является ключевой задачей для дальнейшего развития и широкого внедрения данной технологии.
Традиционные методы масштабирования больших языковых моделей, заключающиеся в увеличении их размера, сталкиваются с законом убывающей доходности. Это связано с ограничениями пропускной способности памяти и вычислительной интенсивности. По мере роста модели, объём данных, которые необходимо перемещать между памятью и процессором, увеличивается, создавая узкое место. Performance = f(ModelSize, MemoryBandwidth, ArithmeticIntensity) При этом, увеличение арифметической интенсивности — количества операций над данными — не успевает за ростом объёма данных. В результате, прирост производительности с каждым новым увеличением размера модели становится всё менее значительным, а потребление энергии продолжает расти. Данное явление препятствует дальнейшему развитию и широкому внедрению больших языковых моделей, особенно на устройствах с ограниченными ресурсами.
Ограничения в вычислительных ресурсах существенно препятствуют развертыванию больших языковых моделей (LLM) на периферийных устройствах, таких как смартфоны или встроенные системы. Необходимость обработки огромных объемов данных и выполнения сложных вычислений требует значительных энергетических затрат, что делает LLM менее доступными для широкого круга пользователей и ограничивает их применение в сценариях, где энергоэффективность критически важна. В результате, потенциал LLM для решения задач в реальном времени и обеспечения персонализированных услуг на устройствах пользователей остается нереализованным, а зависимость от централизованных облачных вычислений сохраняется, что создает дополнительные сложности для конфиденциальности и надежности.
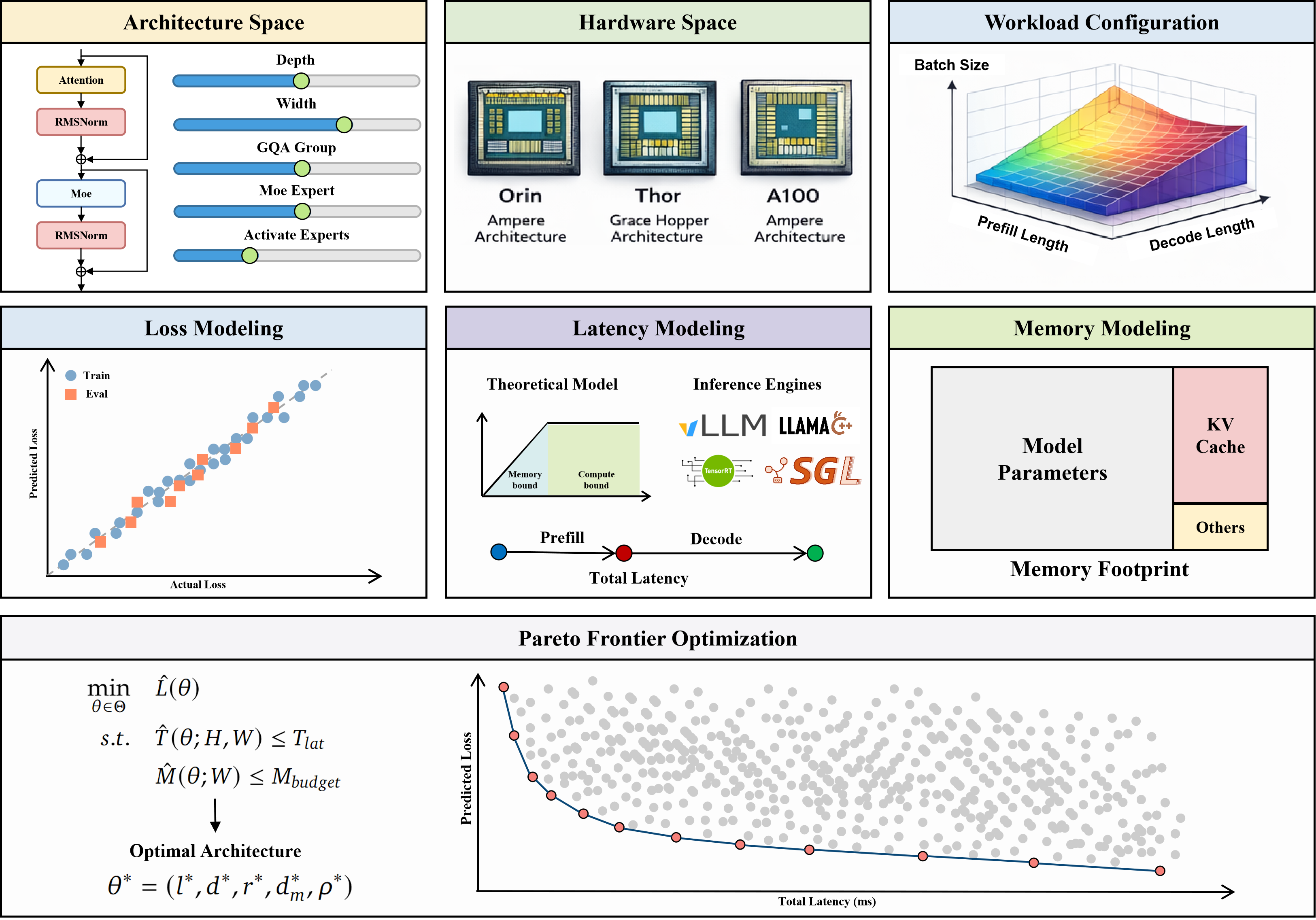
Совместная Оптимизация: Гармония Аппаратного и Программного Обеспечения
Совместная оптимизация аппаратного и программного обеспечения представляет собой подход к преодолению ограничений производительности больших языковых моделей (LLM) путем одновременной настройки обоих компонентов системы. Традиционно, разработка LLM фокусировалась преимущественно на программной стороне — архитектуре модели и алгоритмах обучения. Однако, дальнейшее повышение производительности требует учета характеристик аппаратного обеспечения, включая типы процессоров, память и пропускную способность. Совместный подход позволяет добиться синергии, где изменения в аппаратной части дополняются соответствующими оптимизациями в программном обеспечении, что приводит к более эффективному использованию ресурсов и улучшению ключевых показателей, таких как скорость обработки и энергопотребление. Это особенно важно для развертывания LLM в средах с ограниченными ресурсами, где традиционные подходы могут быть неэффективными.
Совместные методы оптимизации, основанные на анализе Парето-фронтов и законах масштабирования потерь, позволяют разработчикам эффективно преодолевать ограничения производительности больших языковых моделей. Парето-фронты представляют собой набор решений, демонстрирующих количественные компромиссы между точностью (loss) и задержкой (latency), позволяя определить оптимальные конфигурации, учитывающие специфические требования к производительности. Законы масштабирования потерь (Loss = a * N^{-b}, где N — количество параметров модели, a и b — константы) позволяют прогнозировать влияние изменения размера модели на ее точность и задержку, что критически важно для выбора оптимальной архитектуры и размера модели при заданных вычислительных ресурсах. Комбинируя эти подходы, разработчики могут систематически исследовать пространство параметров и находить решения, обеспечивающие наилучший баланс между точностью и скоростью работы модели.
Совместная разработка аппаратного и программного обеспечения открывает возможности для развертывания больших языковых моделей (LLM) на устройствах с ограниченными ресурсами, таких как мобильные телефоны и встраиваемые системы. Это достигается за счет оптимизации как архитектуры модели, так и специализированного аппаратного обеспечения для выполнения вычислений с пониженной точностью и эффективным использованием памяти. Развертывание LLM на периферийных устройствах позволяет снизить задержку, повысить конфиденциальность данных, поскольку обработка происходит локально, и расширить доступ к технологиям обработки естественного языка для пользователей, не имеющих постоянного доступа к облачным сервисам. Данный подход особенно важен для приложений, требующих работы в режиме реального времени, таких как голосовые помощники и системы машинного перевода.
Ключ к Эффективности: Управление Памятью KV-Cache
Кэш KV (KVCache) является ключевым компонентом механизма внимания в больших языковых моделях (LLM), поскольку хранит промежуточные результаты вычислений, необходимые для последующих шагов. Эффективное управление этим кэшем критически важно для производительности, так как размер кэша KV напрямую влияет на потребление памяти и скорость доступа к данным. Неоптимальное управление может привести к значительному увеличению задержки декодирования и снижению пропускной способности, особенно при обработке длинных последовательностей. Поэтому, оптимизация KVCache является приоритетной задачей при развертывании LLM, особенно на устройствах с ограниченными ресурсами.
Для снижения задержки доступа к памяти и повышения пропускной способности в процессе вывода больших языковых моделей (LLM) применяются такие методы, как KVLink и GQA, а также оптимизированные структуры кэша, в том числе использующие разреженную активацию. KVLink позволяет объединять запросы и ключи в кэше, уменьшая количество обращений к памяти. GQA (Grouped-query attention) снижает вычислительную нагрузку и требования к памяти за счет группировки запросов. Оптимизированные структуры кэша, использующие разреженную активацию, эффективно хранят только наиболее релевантные данные, минимизируя объем передаваемой информации. Все эти оптимизации напрямую влияют на задержку декодирования (decode latency), где термин «KV-Cache» явно учитывается как критический параметр производительности.
Оптимизации, направленные на повышение эффективности управления KVCache, оказывают прямое влияние на время инференса и энергопотребление. Уменьшение задержки доступа к памяти, достигаемое за счет таких методов, как KVLink и GQA, позволяет существенно сократить общее время обработки запроса. Особенно заметен эффект на периферийных устройствах (edge devices) с ограниченными ресурсами, где снижение энергопотребления критически важно для продления срока службы батареи и снижения тепловыделения. Сокращение времени инференса, в свою очередь, повышает пропускную способность системы и позволяет обслуживать больше запросов в единицу времени, что особенно важно для приложений реального времени.
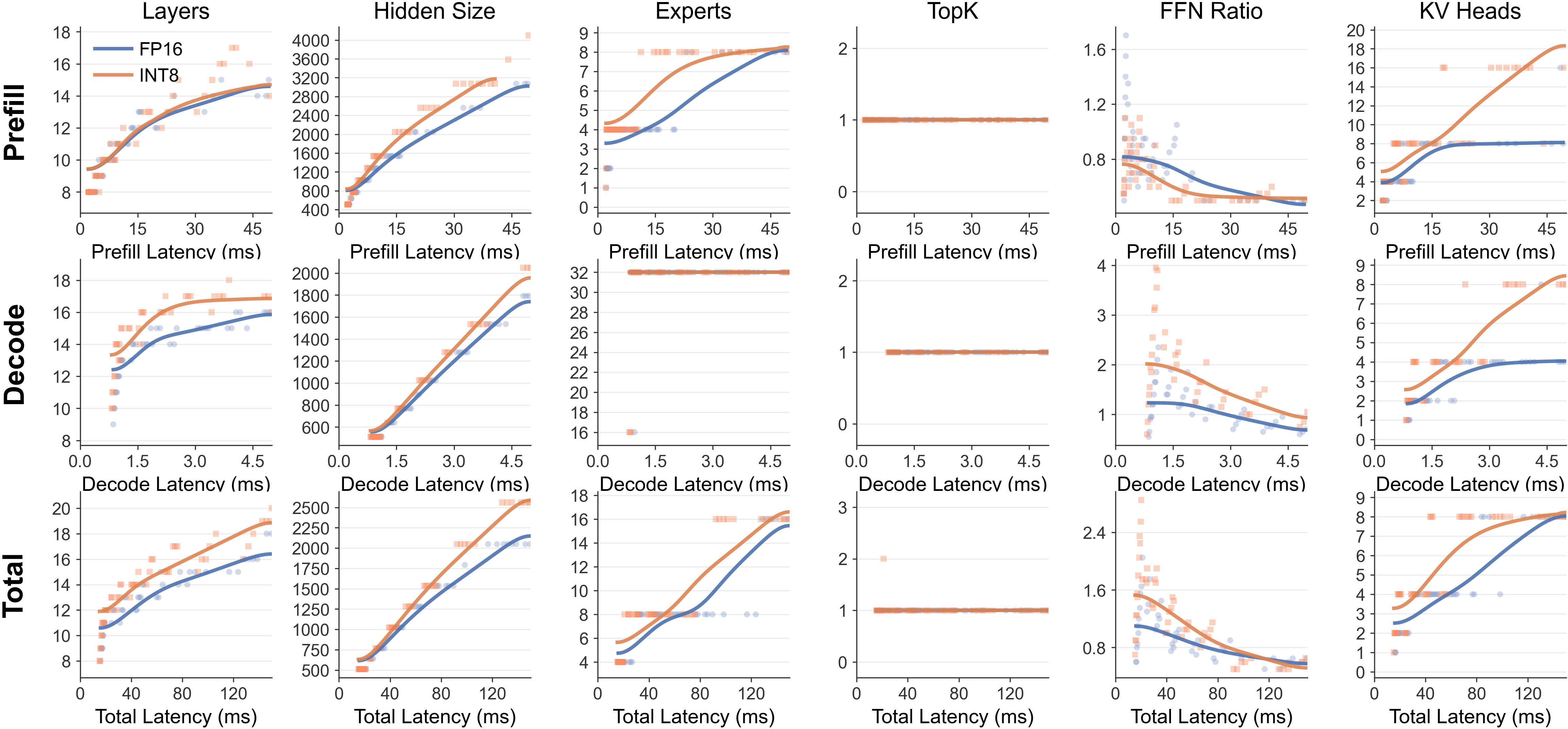
Архитектурные Инновации: Развертывание на Устройствах с Ограниченными Ресурсами
Исследования демонстрируют, что гибкое изменение точности вычислений, в сочетании с архитектурными решениями, такими как масштабирование глубины и ширины нейронных сетей, предоставляет эффективный инструмент для оптимизации соотношения между точностью модели и ее вычислительными затратами. Это позволяет разработчикам сознательно жертвовать незначительной частью точности в пользу существенного снижения потребляемых ресурсов, что особенно важно при развертывании моделей на устройствах с ограниченными возможностями. Такой подход позволяет адаптировать размер и сложность модели к конкретным требованиям задачи и аппаратной платформе, открывая возможности для более эффективного использования вычислительных ресурсов и снижения энергопотребления, не теряя при этом ключевой функциональности.
Методы квантования, такие как AWQ и GPTQ, а также использование малых языковых моделей (SLM), представляют собой эффективные стратегии для существенного снижения требований к памяти и вычислительным ресурсам без заметной потери ключевых функциональных возможностей. Квантование позволяет уменьшить точность представления весов и активаций нейронной сети, что приводит к уменьшению размера модели и ускорению вычислений. В то же время, SLM, будучи более компактными версиями больших языковых моделей, сохраняют способность к пониманию и генерации текста, предлагая оптимальный баланс между производительностью и эффективностью. Сочетание этих подходов открывает возможности для развертывания сложных моделей обработки естественного языка на устройствах с ограниченными ресурсами, таких как мобильные телефоны и встроенные системы.
Новейшие достижения в области оптимизации больших языковых моделей (LLM) открывают возможности для их развертывания непосредственно на периферийных устройствах, таких как смартфоны и носимые гаджеты. Это позволяет осуществлять мгновенный вывод данных и создавать персонализированный пользовательский опыт без необходимости подключения к облачным серверам. Ключевым фактором, обеспечивающим такую возможность, является разработанный закон масштабирования ширины и разреженности, который позволяет точно настраивать размер и сложность модели в зависимости от вычислительных ресурсов устройства. Благодаря этому, LLM могут эффективно функционировать и экономично, обеспечивая быструю реакцию и конфиденциальность данных пользователя, что особенно важно для приложений, требующих обработки информации в реальном времени и сохранения личной информации на устройстве.
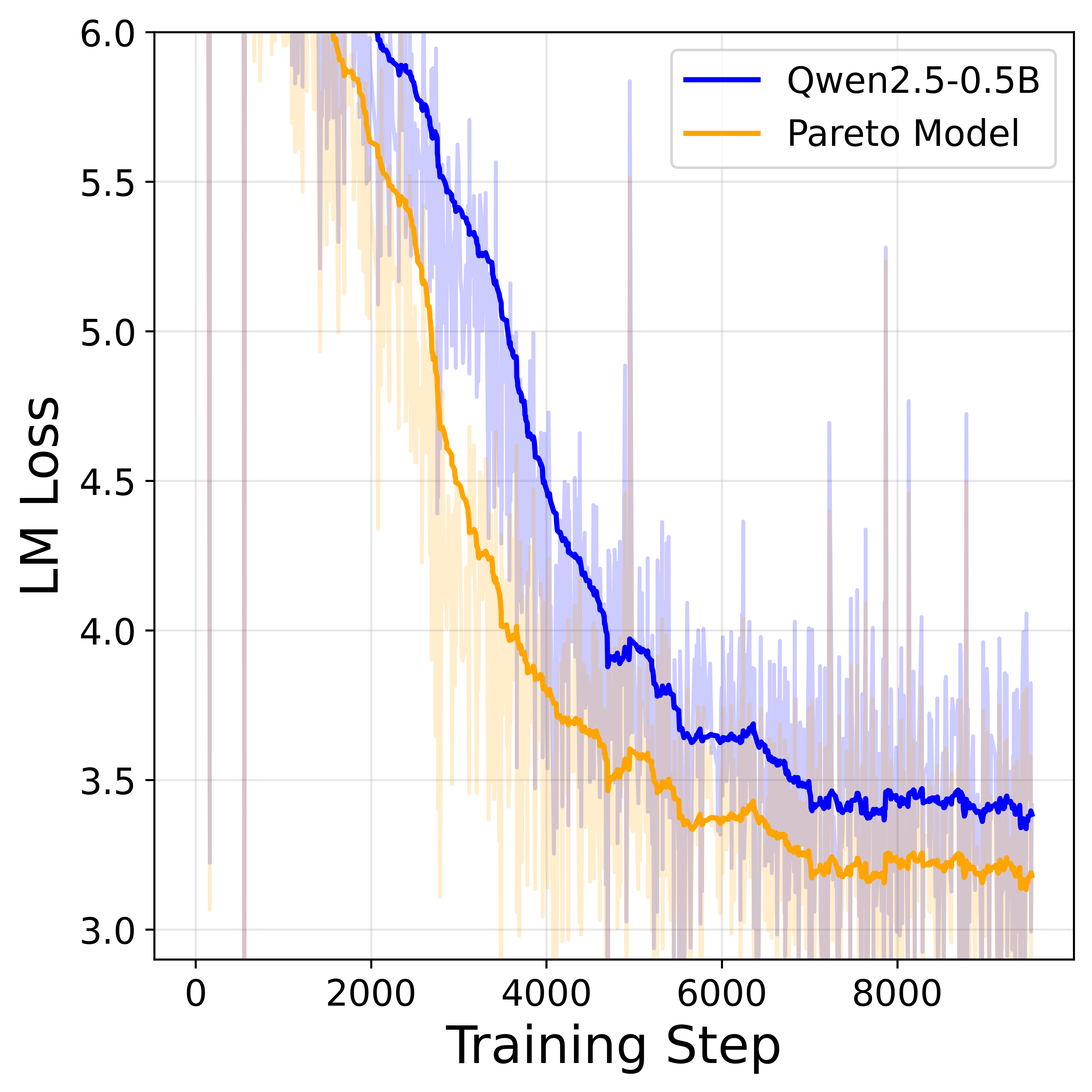
Будущее На Устройствах: Эффективный Вывод и Персонализированный ИИ
Компиляция моделей машинного обучения (MLCLLM) и системы вроде PowerInfer играют ключевую роль в преобразовании теоретических оптимизаций моделей в ощутимый прирост производительности на периферийных устройствах. Эти инструменты не просто оптимизируют код модели, но и адаптируют его к конкретным аппаратным характеристикам, таким как доступная память и вычислительные возможности. Оптимизации включают квантование, прунинг и дистилляцию, позволяющие значительно уменьшить размер модели и сложность вычислений без существенной потери точности. Благодаря MLCLLM, сложные языковые модели, ранее доступные лишь на мощных серверах, становятся применимыми на смартфонах, носимых устройствах и других устройствах с ограниченными ресурсами, открывая новые возможности для локальной обработки данных и повышения конфиденциальности.
Исследования линейных механизмов внимания и оптимизация локальности данных на чипе представляют собой ключевое направление в снижении энергопотребления и ускорении работы больших языковых моделей на устройствах. Ученые стремятся минимизировать обращения к памяти, что является узким местом в производительности. Разработанная формула активации ρ^* = 3η_p bw r α_{attn} (2 - η_p bw) + 6r позволяет более точно оценивать скорость активации и, следовательно, оптимизировать архитектуру моделей и способы доступа к данным. Этот подход позволяет не только повысить эффективность работы моделей, но и значительно снизить их энергопотребление, открывая возможности для их широкого внедрения в мобильные устройства и другие системы с ограниченными ресурсами.
Предстоит эпоха, когда большие языковые модели (LLM) станут неотъемлемой частью повседневной жизни, питая интеллектуальные приложения на любом устройстве. Благодаря прогрессу в области машинного обучения, включая оптимизацию компиляции и системы наподобие PowerInfer, а также исследования линейных механизмов внимания, LLM смогут эффективно функционировать непосредственно на пользовательских устройствах, без необходимости подключения к облачным серверам. Эффективность этой интеграции будет определяться точной настройкой параметров, где коэффициенты \frac{\partial \xi_F}{\partial r} = 6 и \frac{\partial \xi_W^{dec}}{\partial r} = 3 служат ключевыми ориентирами для оптимизации производительности и энергопотребления. Подобная оптимизация позволит LLM бесшовно интегрироваться в широкий спектр приложений — от персональных помощников и систем перевода до инструментов для творчества и образовательных платформ, делая искусственный интеллект более доступным и удобным для каждого.
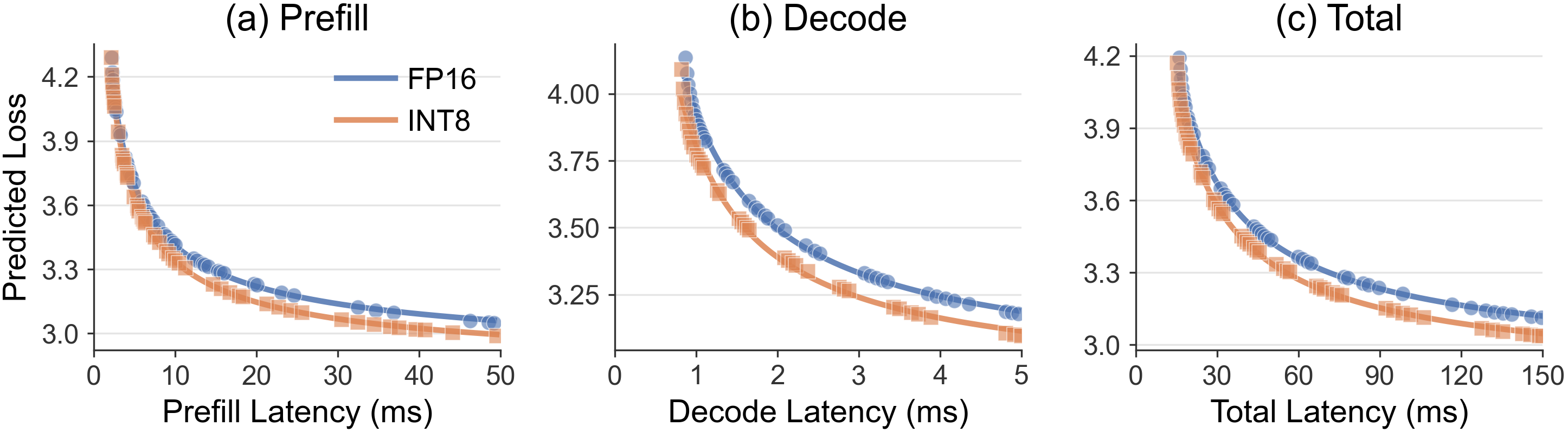
Исследование демонстрирует, что стремление к оптимизации больших языковых моделей на аппаратном обеспечении неизбежно приводит к сложным взаимосвязям между различными компонентами системы. Авторы предлагают подход, основанный на анализе Pareto-оптимальности и Roofline, чтобы найти баланс между точностью и эффективностью. Этот процесс напоминает выращивание экосистемы, где каждый архитектурный выбор формирует будущее поведение системы. Как однажды заметил Анри Пуанкаре: «Наука не есть собирание фактов, как листьев, а построение логически связанных теорий». В данном случае, теория аппаратного и программного со-проектирования стремится объяснить и предсказать поведение системы в условиях ограниченных ресурсов, признавая, что даже самое тщательное проектирование не может полностью исключить возможность сбоев в будущем.
Куда Ведет Эта Дорога?
Представленная работа, фокусируясь на со-проектировании аппаратного и программного обеспечения для больших языковых моделей, лишь приоткрывает завесу над сложной экосистемой. Поиск оптимальных архитектур посредством Pareto-оптимизации и roofline-анализа — это не столько решение, сколько формулировка вопроса. Гарантий стабильной производительности не существует, лишь соглашение с вероятностью. Следующим шагом видится не столько повышение точности, сколько признание неизбежности хаоса в системах подобного масштаба. Хаос — это не сбой, это язык природы.
Особое внимание следует уделить адаптивности. Архитектуры, жёстко привязанные к конкретному оборудованию, обречены на быстрое устаревание. Необходим переход к самообучающимся системам, способным динамически перестраивать свою структуру в ответ на меняющиеся условия и ограничения. Стабильность — это просто иллюзия, которая хорошо кэшируется, и её стоимость может оказаться непомерно высокой.
В конечном счете, настоящая проблема заключается не в масштабировании моделей, а в понимании пределов их применимости. Попытки создать универсальный искусственный интеллект — это утопия. Более реалистичным подходом представляется создание специализированных систем, адаптированных к конкретным задачам и окружению. Системы — это не инструменты, а экосистемы. Их нельзя построить, только вырастить.
Оригинал статьи: https://arxiv.org/pdf/2602.10377.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Предел возможностей: где большие языковые модели теряют разум?
- Улучшение точности квантовых сенсоров: новый подход к подавлению шумов
- Резонансы в тандеме: Управление светом в микрорезонаторах
- Квантовый шум: за пределами стандартных моделей
- Виртуальная примерка без границ: EVTAR учится у образов
- Искусственный разум и квантовые данные: новый подход к синтезу табличных данных
- Моделирование спектроскопии электронного пучка: новый подход
- Квантовое программирование: Карта развивающегося мира
- За пределами стандартной точности: новая структура эффективной теории
- Сердце музыки: открытые модели для создания композиций
2026-02-21 16:39