Автор: Денис Аветисян
Ученые представили BABE — комплексный тест, позволяющий оценить способность искусственного интеллекта к логическому мышлению и анализу биологических данных.
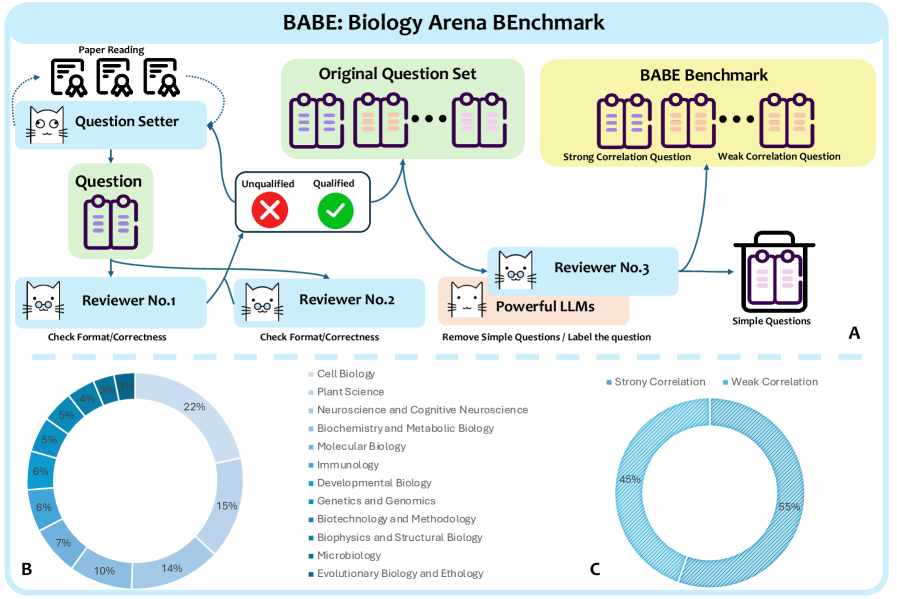
BABE — это новый бенчмарк для оценки возможностей больших языковых моделей в области экспериментального мышления и интеграции знаний в биологии.
Несмотря на стремительное развитие больших языковых моделей (LLM), оценка их способности к комплексному научному мышлению в биологии остается сложной задачей. В настоящей работе представлена новая методика — ‘BABE: Biology Arena BEnchmark’, предназначенная для всесторонней оценки навыков экспериментального рассуждения биологических AI-систем. BABE уникален тем, что задачи построены на основе рецензируемых научных статей и реальных биологических исследований, требуя от моделей не только анализа данных, но и интеграции экспериментальных результатов с контекстными знаниями. Сможем ли мы с помощью BABE создать действительно надежные инструменты искусственного интеллекта для поддержки и ускорения биологических исследований?
Биологическое мышление и искусственный интеллект: где кроется подвох?
Современные большие языковые модели (LLM) демонстрируют впечатляющую способность к распознаванию закономерностей в данных, однако интерпретация сложных биологических экспериментов представляет для них значительную трудность. В то время как LLM успешно справляются с задачами, требующими выявления статистических корреляций, глубокое понимание биологического контекста, причинно-следственных связей и умение интегрировать разрозненные данные для формирования обоснованных выводов остаются за пределами их возможностей. Это связано с тем, что биологические исследования часто требуют не просто идентификации паттернов, а оценки достоверности результатов, учета множества переменных и способности к абстрактному мышлению, что выходит за рамки возможностей моделей, основанных исключительно на статистическом анализе больших объемов текста. Таким образом, LLM, хотя и полезны для автоматизации рутинных задач, не способны заменить экспертов-биологов в области анализа и интерпретации экспериментальных данных.
Существующие стандартные тесты для оценки искусственного интеллекта в биологии зачастую не отражают сложности реальных научных исследований, что приводит к завышенным оценкам эффективности. Эти тесты, как правило, концентрируются на отдельных фактах или простых корреляциях, игнорируя необходимость последовательного логического анализа и учета контекста, характерного для биологических экспериментов. В реальной науке, результаты одного исследования служат основой для последующих, требуя от исследователя интеграции новой информации с уже существующими знаниями и пересмотра первоначальных гипотез. Отсутствие подобной многоступенчатой логики в традиционных бенчмарках приводит к тому, что ИИ может успешно решать упрощенные задачи, но терпит неудачу при столкновении с комплексными сценариями, требующими глубокого понимания биологических процессов и способности к критическому мышлению.
Остро стоит необходимость в создании специализированных тестов, способных достоверно оценить способность искусственного интеллекта объединять результаты экспериментов с существующими биологическими знаниями для формирования обоснованных выводов. Существующие методики часто упрощают сложность биологических процессов, не требуя от ИИ глубокого понимания контекста и последовательности логических шагов, необходимых для интерпретации научных данных. Такие тесты должны не просто проверять способность к сопоставлению фактов, но и оценивать умение строить гипотезы, выявлять причинно-следственные связи и учитывать множество взаимосвязанных факторов, характерных для живых систем. Разработка подобных бенчмарков позволит более точно определить текущие ограничения ИИ в области биологических наук и стимулировать создание более интеллектуальных и надежных систем, способных к действительному научному познанию.
BABE: Новый эталон для оценки биологического интеллекта
Бенчмарк BABE (Biological Assessment of Biological Expertise) построен на задачах, непосредственно извлеченных из опубликованных, рецензируемых биологических исследований. Это обеспечивает высокую экологическую валидность и релевантность бенчмарка реальным научным задачам, с которыми сталкиваются исследователи. В отличие от синтетических бенчмарков, BABE использует данные, полученные в результате экспериментальных исследований, опубликованных в авторитетных научных журналах, что гарантирует соответствие задач практическим потребностям биологической науки и позволяет оценивать способность моделей к решению проблем, возникающих в реальной научной практике.
В составе эталонного набора BABE используются вопросы двух типов, предназначенные для всесторонней оценки навыков рассуждения. Вопросы “сильной корреляции” требуют последовательного логического вывода, когда ответ зависит от последовательного анализа нескольких экспериментальных данных и их взаимосвязи. В то время как вопросы “слабой корреляции” оценивают способность к параллельному извлечению информации — то есть, выделению и сопоставлению релевантных фактов из нескольких источников данных, не требующих строгой последовательности. Комбинация этих двух типов вопросов позволяет комплексно оценить способность системы к как последовательному, так и параллельному анализу биологической информации.
В отличие от задач, основанных на простом сопоставлении шаблонов, BABE (Benchmark for Experimental Insight) ставит перед системами задачи, требующие интеграции результатов экспериментов с контекстуальными знаниями. Это означает, что для успешного решения необходимо не просто распознать закономерности в данных, но и понимать биологический смысл эксперимента, его цели и взаимосвязь с существующими научными знаниями. Такой подход позволяет оценить способность системы к действительному биологическому осмыслению, а не просто к формальному анализу данных, что является критически важным для решения реальных научных задач.
Улучшение LLM: контекст, рассуждения и многократный вывод
Для достижения высоких результатов в задачах, подобных BABE, недостаточно использования стандартных архитектур больших языковых моделей (LLM). Критически важным является применение методов “контекстного обоснования” (Contextual Grounding), обеспечивающих LLM необходимым фоновым объемом информации. Этот подход позволяет модели опираться на внешние источники знаний, дополняя ее внутренние представления и повышая точность рассуждений, особенно в случаях, когда требуются специализированные или редко встречающиеся данные, отсутствующие в процессе предварительного обучения модели.
В рамках разработки “глубоких исследовательских агентов” показана эффективность подхода “генерация, дополненная извлечением” (Retrieval-Augmented Generation). Данный метод позволяет динамически включать релевантные данные в процесс рассуждений языковой модели. Вместо использования исключительно внутренних знаний, система извлекает информацию из внешних источников на основе текущего запроса и использует её для формирования ответа. Это позволяет значительно повысить точность и обоснованность рассуждений, особенно в задачах, требующих доступа к актуальной или специализированной информации, не содержащейся в параметрах самой модели.
Метод многократного вывода (Multi-Trial Inference) позволяет повысить надежность и точность больших языковых моделей (LLM) за счет агрегации результатов, полученных из нескольких независимых прогонов. В частности, для моделей, демонстрирующих сильные навыки рассуждения, данный подход обеспечивает прирост производительности до 30 баллов. При дальнейшем увеличении количества прогонов наблюдается тенденция к асимптотическому улучшению результатов, достигающему порядка 30 баллов, что указывает на стабилизацию прироста эффективности.
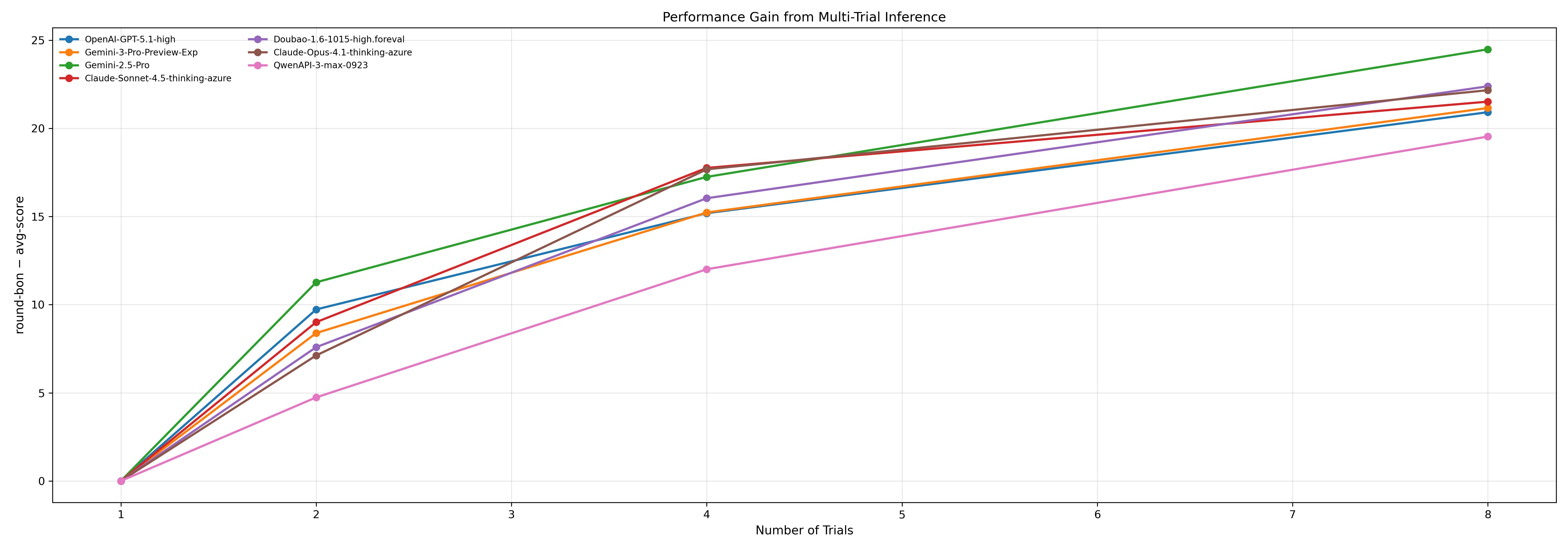
Результаты и перспективы развития ИИ в биологии: где мы сейчас и куда движемся?
Оценка производительности современных языковых моделей, таких как ‘GPT-5.1’ и ‘Gemini-3-Pro’, с использованием нового эталона BABE, выявила существенные различия в их способностях к биологическому рассуждению. В частности, модель OpenAI-GPT-5.1-high продемонстрировала наивысший средний балл, составив 52.31, однако и это значение указывает на сохраняющиеся трудности в достижении надежного и глубокого понимания биологических процессов. Данные результаты подчеркивают, что, несмотря на значительный прогресс в области искусственного интеллекта, создание систем, способных к комплексному анализу и интерпретации биологических данных, остается сложной задачей, требующей дальнейших исследований и разработки новых подходов к обучению и моделированию.
Бенчмарк BABE расширяет существующие биологические тесты, делая акцент на более тонкой и реалистичной оценке навыков экспериментального мышления. В отличие от предыдущих подходов, BABE оценивает не только знание фактов, но и способность к логическому выводу и интерпретации результатов, приближая оценку к реальным задачам, стоящим перед учеными-биологами. Результаты тестирования модели OpenAI-GPT-5.1-high демонстрируют высокий уровень корреляции — 51.79 по сильным корреляциям и 52.86 по слабым корреляциям — что указывает на потенциал современных языковых моделей в решении задач биологического анализа, но также подчеркивает необходимость дальнейшего развития в области понимания нюансов и неполноты экспериментальных данных.
Полученные результаты подчеркивают необходимость дальнейших исследований в области методов закрепления знаний, усиления способностей к рассуждению и разработки систем искусственного интеллекта, способных решать сложные биологические исследовательские задачи. Очевидно, что для достижения существенного прогресса в биологии с помощью ИИ требуется не просто накопление биологических данных, но и развитие алгоритмов, способных эффективно интегрировать эти данные, делать логические выводы и генерировать новые гипотезы. Усилия должны быть направлены на создание ИИ, который может не только распознавать биологические закономерности, но и понимать их контекст, а также применять эти знания для решения новых, ранее не встречавшихся проблем. Перспективными направлениями являются разработка более сложных моделей рассуждений, основанных на причинно-следственных связях, и создание методов обучения ИИ, позволяющих ему приобретать знания из различных источников и адаптироваться к новым данным.
Вновь появляется иллюзия прогресса. Создатели BABE, конечно, воодушевлены новой площадкой для оценки языковых моделей в биологии, но для опытного наблюдателя это лишь очередная попытка измерить нечто сложное линейными метриками. В статье акцент делается на оценке способности моделей интегрировать экспериментальные данные с фоновыми знаниями — звучит неплохо, но в реальности, как показывает практика, каждая новая библиотека, каждая новая «инновация» в области ИИ лишь добавляет слоев абстракции, которые рано или поздно приведут к неразрешимым проблемам. Как говорил Давид Гильберт: «В математике нет рая, нет конечной цели, есть лишь новые возможности для исследования». И в данном случае, BABE — это не решение, а лишь очередная возможность усложнить задачу.
Что дальше?
Представленный бенчмарк BABE, несомненно, станет очередным элементом в постоянно растущем арсенале тестов для больших языковых моделей. Однако, за кажущейся строгостью оценки биологического рассуждения скрывается неизбежный вопрос: насколько хорошо модель «понимает» биологию, и насколько просто воспроизводит паттерны, найденные в обучающих данных? Время покажет, как быстро продакшен найдёт способы обойти даже самые продуманные метрики.
В конечном счёте, BABE — это лишь снимок текущего состояния дел. Настоящая проблема заключается не в том, чтобы заставить модель правильно отвечать на вопросы, а в создании систем, способных к настоящему экспериментальному мышлению — к формулированию гипотез, проектированию экспериментов и интерпретации результатов с учётом неопределённости и шума. И, разумеется, к признанию, когда гипотеза оказалась неверной.
Можно предположить, что в ближайшем будущем бенчмарки станут ещё сложнее, ещё многограннее, и ещё более подвержены эксплуатации. И это хорошо. Ведь каждое новое поколение тестов — это напоминание о том, что идеальных систем не существует, и что в конечном итоге мы не чиним продакшен — мы просто продлеваем его страдания.
Оригинал статьи: https://arxiv.org/pdf/2602.05857.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Самообучающиеся агенты: новый подход к автономным системам
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Графы и действия: новый подход к планированию для роботов
- Визуальный след: Сжатие рассуждений для мощных языковых моделей
- Визуальный разум: Как видеомодели научились понимать текст и создавать изображения
- Ожившие скелеты: Редактируемая 4D-генерация объектов
- Искусственный интеллект на службе карьеры: STEM-образование нового поколения
- Ожившие Миры: Новая Эра Видеогенерации
- Третья Разновидность ИИ: Как модели, думающие «про себя», оставят позади GPT и CoT
- Квантовые маршруты и гравитационные сенсоры: немного иронии от физика
2026-02-06 14:51