Автор: Денис Аветисян
Новый алгоритм позволяет эффективно вычислять наименьшие сингулярные значения и векторы для очень высоких и узких матриц, что критически важно для анализа больших объемов данных.
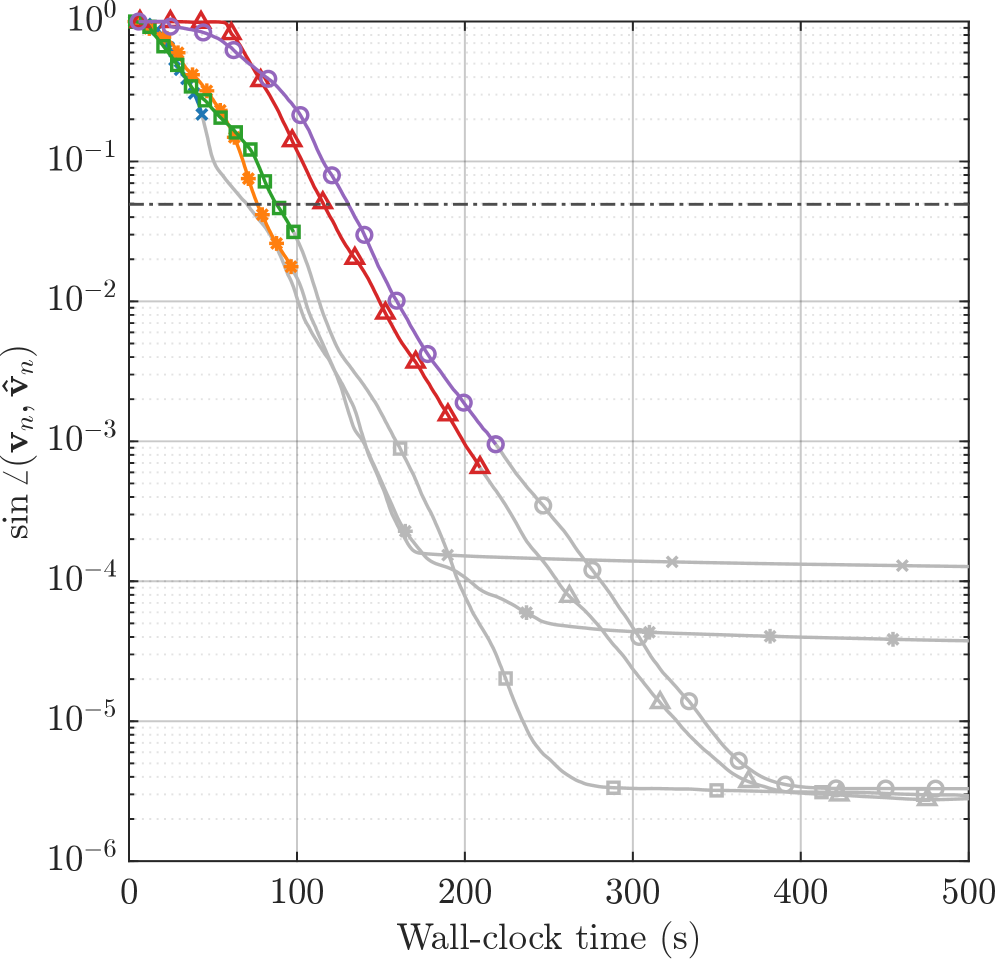
Представлен RLOBPCG — рандомизированный алгоритм, сочетающий предварительную обработку с LOBPCG для повышения скорости и надежности вычислений.
Вычисление сингулярных значений и векторов для больших, “узких” матриц часто представляет собой вычислительную проблему, особенно при стремлении к высокой точности. В статье ‘Fast, High-Accuracy, Randomized Nullspace Computations for Tall Matrices’ предложен новый эффективный алгоритм RLOBPCG, сочетающий в себе рандомизированное предварительное обусловливание и итерационный решатель LOBPCG. Данный подход обеспечивает геометрическую сходимость к минимальному сингулярному вектору при умеренном разрыве между двумя наименьшими сингулярными значениями, демонстрируя значительное ускорение по сравнению с классическими методами, вплоть до 12 раз. Возможно ли дальнейшее расширение области применения RLOBPCG для решения задач, связанных с обработкой данных в режиме реального времени и крупномасштабным машинным обучением?
Вызов Высокой Размерности: Преодолевая Сложность Данных
Во многих областях науки и техники анализ данных часто сводится к работе с так называемыми “вытянутыми” матрицами — наборами данных, где число строк значительно превосходит число столбцов. Подобные структуры встречаются повсеместно: в задачах обработки изображений, где строки представляют пиксели, а столбцы — признаки, в геномике, где строки соответствуют генам, а столбцы — образцам, и в машинном обучении, где строки — это наблюдения, а столбцы — признаки. m \gg n — типичное соотношение размеров для таких матриц, где m обозначает число строк, а n — число столбцов. Их анализ, хотя и предоставляет богатые возможности для извлечения информации, требует специфических подходов и вычислительных ресурсов, поскольку стандартные методы оказываются неэффективными при работе с огромными объемами данных.
Традиционные методы анализа «высоких» матриц, такие как сингулярное разложение (SVD), сталкиваются с серьезными вычислительными трудностями при увеличении объемов данных. Алгоритм SVD, хотя и мощный, требует порядка O(n^3) операций для матрицы размера n \times n, что делает его непрактичным для обработки матриц с огромным количеством строк. По мере роста размерности данных, потребность в вычислительных ресурсах и времени обработки экспоненциально увеличивается, препятствуя проведению анализа в разумные сроки. Это особенно критично в областях, где требуется оперативная обработка больших объемов информации, таких как обработка изображений, геномика и анализ социальных сетей, где традиционные подходы становятся узким местом в конвейере обработки данных.
Возникающие трудности с обработкой больших объемов данных существенно замедляют прогресс в различных научных и инженерных областях. Например, в геномике анализ огромных массивов данных о генах требует колоссальных вычислительных ресурсов, ограничивая возможности выявления ключевых генетических факторов заболеваний. В обработке изображений, особенно в задачах распознавания образов и компьютерного зрения, увеличение разрешения и объема данных приводит к экспоненциальному росту вычислительной нагрузки. Аналогичные проблемы возникают в астрономии при анализе данных, полученных с современных телескопов, и в машинном обучении, где эффективность алгоритмов напрямую зависит от скорости обработки данных. Таким образом, преодоление этого вычислительного барьера является ключевой задачей для дальнейшего развития многих передовых направлений науки и техники, позволяя извлекать ценную информацию из постоянно растущих массивов данных.
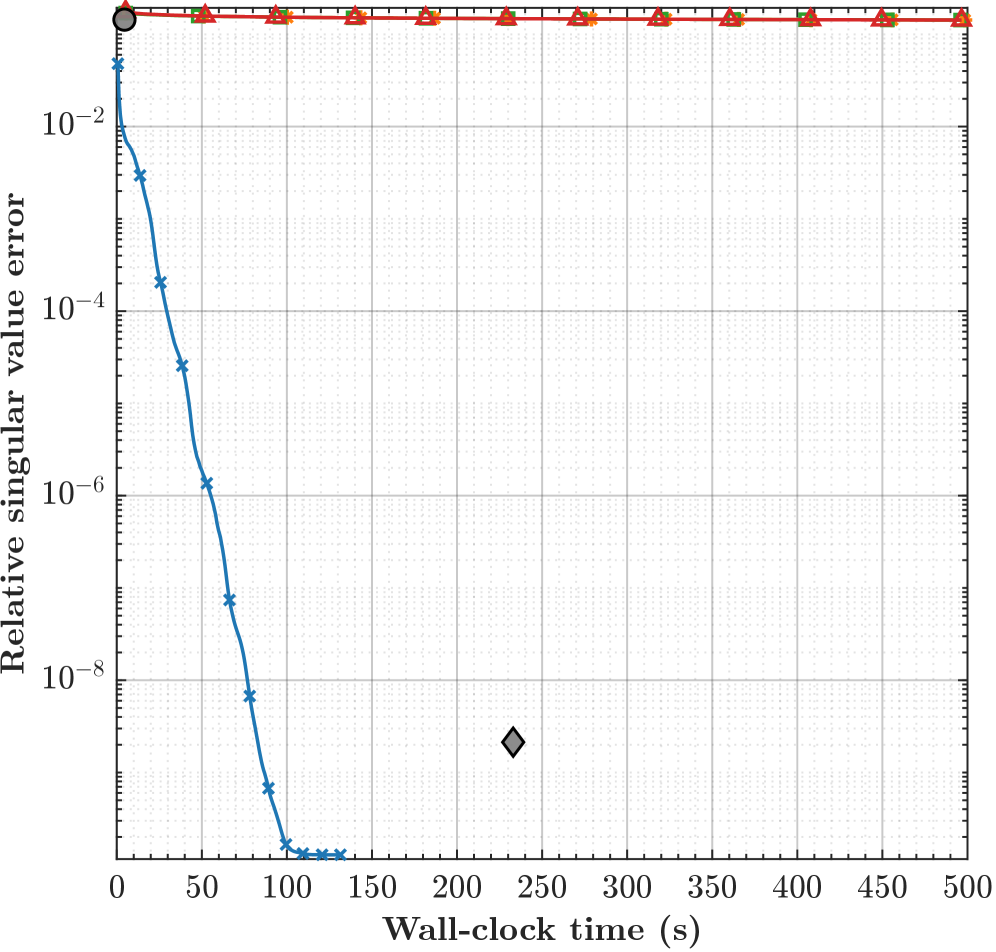
Рандомизированное Предварительное Обусловливание: Уменьшение Сложности Данных
Рандомизированное предварительное обусловливание (Randomized Preconditioning) предоставляет возможность эффективного анализа высоких матриц путем снижения их размерности. Это достигается за счет сокращения числа переменных, необходимых для представления данных, без существенной потери информации. В контексте анализа больших данных и машинного обучения, обработка высоких матриц часто является вычислительно дорогостоящей задачей. Рандомизированное предварительное обусловливание позволяет уменьшить вычислительную сложность, представляя исходную матрицу в пространстве меньшей размерности, сохраняя при этом наиболее важные характеристики для последующего анализа. Это особенно полезно в задачах, где требуется решение систем линейных уравнений или вычисление собственных значений и собственных векторов.
Метод случайного предобуславливания использует технику «скетчирования» — метод понижения размерности, направленный на создание подпространства меньшей размерности, сохраняющего ключевую информацию исходных данных. Скетчирование предполагает проектирование исходного вектора или матрицы на случайную матрицу меньшего размера. При этом, благодаря свойствам случайных матриц, с высокой вероятностью сохраняется структура данных, необходимая для последующих вычислений. Важно отметить, что скетчирование не стремится к точному восстановлению исходных данных, а фокусируется на сохранении информации, релевантной для конкретной задачи, например, для решения систем линейных уравнений или выполнения операций линейной алгебры.
Проецирование исходной матрицы в пониженное подпространство, реализуемое посредством вложения подпространства (subspace embedding), значительно снижает вычислительную нагрузку. Этот процесс заключается в преобразовании матрицы из исходного пространства высокой размерности в пространство меньшей размерности, сохраняя при этом наиболее важную информацию. Степень снижения вычислительной сложности напрямую зависит от размерности нового подпространства и свойств используемого вложения. В частности, для матриц размером m \times n, где m > n, снижение размерности до k, где k << n, позволяет сократить время вычислений, связанных с разложением матрицы или решением систем линейных уравнений, пропорционально отношению n/k. Важно отметить, что выбор метода вложения подпространства влияет на точность представления исходной матрицы в пониженном пространстве.
RLOBPCG: Новый Итеративный Решатель для Высоких Матриц
Метод RLOBPCG представляет собой новую методику, объединяющую преимущества рандомизированного предварительного обусловливания и локально оптимального блочного метода сопряженных градиентов (LOBPCG). Рандомизированное предварительное обусловливание позволяет эффективно снизить вычислительную сложность решения системы линейных уравнений, особенно для больших разреженных матриц. Интеграция с LOBPCG обеспечивает быструю сходимость к собственным векторам, соответствующим наименьшим сингулярным числам, за счет локальной оптимизации подпространства. Такое сочетание позволяет RLOBPCG эффективно вычислять собственные векторы больших матриц, сохраняя при этом высокую точность и скорость сходимости.
Метод RLOBPCG эффективно вычисляет собственные векторы, соответствующие наименьшим сингулярным числам, для «высоких» матриц (матриц, у которых количество строк значительно больше количества столбцов). Это вычисление критически важно для анализа структуры данных и выявления основных закономерностей. При определенных условиях, в частности при достаточно большом разрыве между сингулярными числами, метод демонстрирует геометрическую скорость сходимости, что означает, что ошибка на каждой итерации уменьшается в геометрической прогрессии. Геометрическая сходимость обеспечивает быстрое и надежное приближение к истинным собственным векторам, что делает RLOBPCG полезным инструментом для задач анализа данных и машинного обучения. Скорость сходимости, как правило, определяется как O(\rho^k), где \rho < 1 — коэффициент уменьшения ошибки, а k — номер итерации.
Эффективность метода RLOBPCG напрямую зависит от величины спектрального зазора — разницы между последовательными сингулярными числами матрицы. Меньший спектральный зазор, указывающий на близкое расположение сингулярных чисел, может приводить к замедлению сходимости алгоритма. Это связано с тем, что RLOBPCG использует информацию о сингулярных числах для построения эффективного предваряющего оператора. Таким образом, чувствительность RLOBPCG к спектральному зазору подчеркивает важность анализа характеристик данных при выборе и настройке численных методов для решения задач, связанных с большими матрицами.
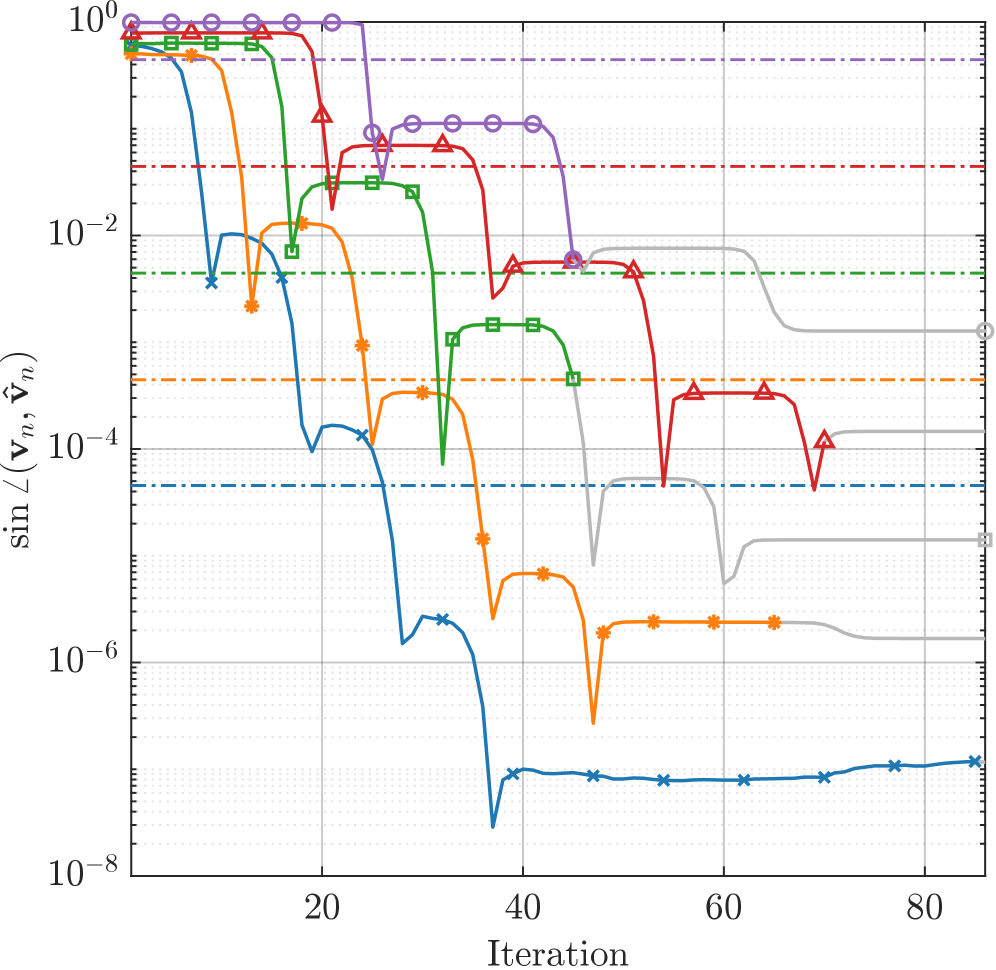
Влияние и Перспективы Развития: Ключ к Эффективному Анализу Данных
Число обусловленности матрицы оказывает существенное влияние на скорость сходимости итерационных решателей, таких как RLOBPCG. Высокое число обусловленности указывает на то, что матрица близка к вырожденной, что приводит к замедлению сходимости алгоритма и увеличению вычислительных затрат. Понимание этой взаимосвязи критически важно для обеспечения устойчивой и эффективной работы решателя, особенно при работе с большими и сложными задачами. Недооценка числа обусловленности может привести к неточным результатам или даже к расходимости алгоритма, что требует применения методов предварительной обработки или выбора альтернативных решателей. Таким образом, анализ числа обусловленности является неотъемлемой частью процесса решения задач линейной алгебры и необходим для достижения надежной и точной работы итерационных методов.
Улучшение производительности итеративного решателя RLOBPCG достигается за счёт применения алгоритма AAA-Lawson для рациональной аппроксимации. Исследования показали, что данный подход позволяет вдвое ускорить вычисления по сравнению со стандартным алгоритмом AAA-Lawson, реализованным в MATLAB с использованием сингулярного разложения svd. Эффективность достигается за счет более точного и быстрого приближения к решению, что особенно важно при работе с плохо обусловленными матрицами. Подобное ускорение существенно расширяет возможности анализа больших и сложных наборов данных, открывая перспективы для прорывов в областях машинного обучения и научных вычислений.
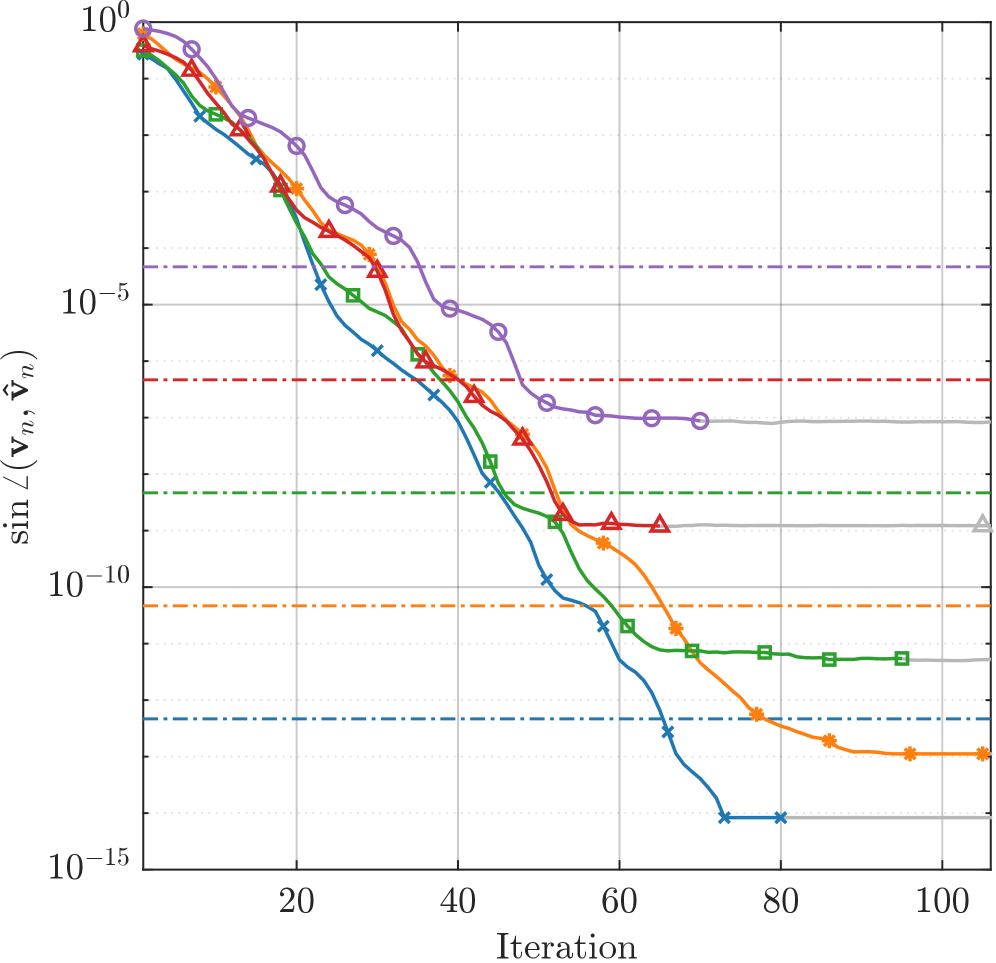
Разработанный метод открывает новые возможности для анализа всё более крупных и сложных наборов данных, потенциально приводя к прорывам в областях машинного обучения и научных вычислений. Благодаря оптимизированным алгоритмам, достигается значительное снижение вычислительных затрат при решении сложных задач, что позволяет исследовать данные, ранее недоступные для анализа из-за ограничений по ресурсам. В частности, наблюдается формирование почти круговых кривых ошибок ≈ (near-circular error curves), свидетельствующих о стабильном и эффективном процессе сходимости, а также снижение ошибки примерно в 2.5 раза при использовании проверок на застой, что существенно повышает надежность и точность получаемых результатов.
Представленная работа демонстрирует стремление к лаконичности и эффективности в вычислениях, что находит отклик в словах Вильгельма Рентгена: «Я не ищу новых элементов, я лишь использую известные». Алгоритм RLOBPCG, предложенный в статье, подобно рентгеновскому излучению, проникает сквозь сложность «высоких» матриц, выявляя их ключевые особенности — наименьшие сингулярные значения и векторы. Удаление избыточности и концентрация на существенном — вот принцип, объединяющий как открытие Рентгена, так и данный подход к вычислениям. В стремлении к оптимальному решению, разработчики, подобно гениальному физику, избегают ненужных усложнений, фокусируясь на точности и скорости.
Что Дальше?
Представленный алгоритм, RLOBPCG, безусловно, представляет собой шаг к упрощению вычислений сингулярных значений для «высоких» матриц. Однако, увлечение скоростью не должно заслонять фундаментальную сложность задачи. Устойчивость метода к структуре матрицы остается областью для дальнейшего исследования. Полагаться на случайность — удобно, но не всегда элегантно. Очевидно, что поиск детерминированных аналогов, сохраняющих эффективность, является следующим логичным шагом.
Особое внимание следует уделить анализу сходимости в условиях, когда матрица далека от идеальной «тонкой» формы. Рациональные приближения, используемые в алгоритме, — инструмент мощный, но требующий осторожности. Их поведение при экстремальных значениях сингулярных чисел требует более детального изучения. Более того, практическая реализация, способная эффективно использовать современные архитектуры параллельных вычислений, является нетривиальной задачей.
В конечном счете, цель не в том, чтобы просто ускорить вычисления, а в том, чтобы глубже понять природу сингулярного разложения. Простота — вот высшая форма сложности. Истина редко лежит на поверхности, но всегда скрыта в деталях. Путь к совершенству лежит через отбрасывание всего лишнего, а не через добавление новых слоев абстракции.
Оригинал статьи: https://arxiv.org/pdf/2602.16797.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Предел возможностей: где большие языковые модели теряют разум?
- Улучшение точности квантовых сенсоров: новый подход к подавлению шумов
- Резонансы в тандеме: Управление светом в микрорезонаторах
- Реальность и Кванты: Где Встречаются Теория и Эксперимент
- Моделирование спектроскопии электронного пучка: новый подход
- Квантовое программирование: Карта развивающегося мира
- За пределами стандартной точности: новая структура эффективной теории
- Сердце музыки: открытые модели для создания композиций
- Тандем топ-кварков и бозона Хиггса: новые горизонты точности
- Квантовый скачок: от лаборатории к рынку
2026-02-22 14:23