Автор: Денис Аветисян
Новый подход к поиску ближайших соседей позволяет значительно снизить затраты на ввод-вывод данных и повысить скорость работы с векторными представлениями текстов.
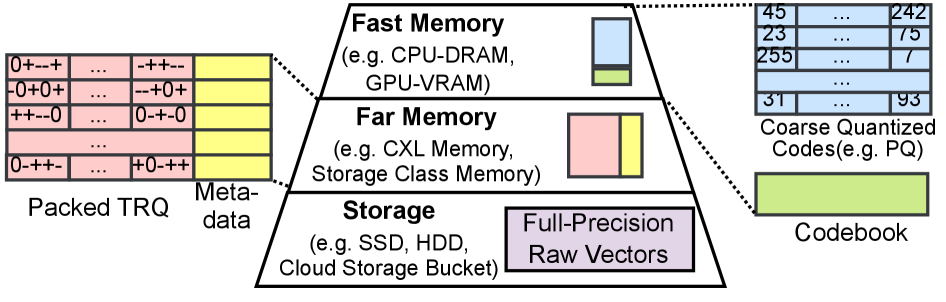
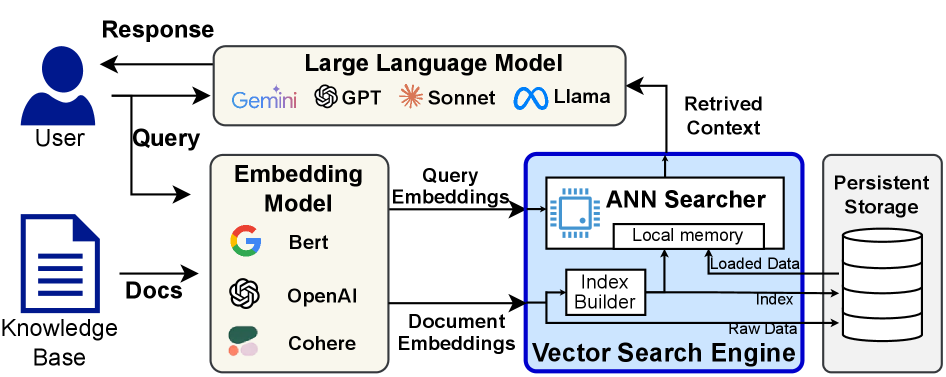
В статье представлена методика FaTRQ, использующая многоуровневую квантизацию остатков для эффективного поиска в системах с распределенной памятью.
Несмотря на успехи в области приближенного поиска ближайших соседей (ANNS), современные системы по-прежнему сталкиваются с узким местом, связанным с дорогостоящим доступом к данным в медленной памяти. В данной работе, ‘FaTRQ: Tiered Residual Quantization for LLM Vector Search in Far-Memory-Aware ANNS Systems’, предложен инновационный подход FaTRQ, использующий многоуровневую память и троичную квантизацию остатков для значительного снижения затрат на ввод-вывод и повышения пропускной способности поиска. Благодаря этому удается обойти необходимость загрузки полновесных векторов из медленной памяти, что позволяет ускорить процесс поиска в векторных базах данных. Какие перспективы открывает применение подобных технологий для создания еще более эффективных систем поиска и обработки больших объемов данных в будущем?
Проблема масштабируемости в поиске ближайших соседей
Современные приложения, такие как семантический поиск и системы рекомендаций, предъявляют всё более высокие требования к скорости и точности поиска ближайших соседей (NNS). От эффективности этого поиска напрямую зависит качество предоставляемых услуг: мгновенный поиск релевантных документов или товаров, персонализированные рекомендации, основанные на предпочтениях пользователя. Растущие объемы данных, с которыми приходится работать, делают задачу поиска ближайших соседей особенно сложной, требуя разработки новых алгоритмов и оптимизации существующих методов для обеспечения высокой производительности и точности даже при работе с огромными наборами данных. В результате, поиск ближайших соседей становится ключевым компонентом многих современных систем, определяя их скорость работы и качество предоставляемых услуг.
Традиционные методы точного поиска ближайших соседей (NNS) сталкиваются с серьезными ограничениями при работе с крупными объемами данных. Поиск ближайшего соседа в многомерном пространстве требует вычисления расстояния до каждого элемента в базе данных, что приводит к экспоненциальному росту вычислительных затрат с увеличением размера набора данных. В то время как наивные методы приближенного поиска ближайших соседей (ANNS) стремятся ускорить процесс, они часто достигают этого за счет существенной потери точности. Проще говоря, ускорение поиска достигается путем отбрасывания потенциально релевантных кандидатов, что может привести к возврату неоптимальных результатов. Таким образом, возникает дилемма: либо тратить непомерное количество времени на точный поиск, либо жертвовать качеством ради скорости, что особенно критично для приложений, где точность играет первостепенную роль.
Неуклонный рост объемов данных ставит перед исследователями задачу разработки инновационных подходов к поиску ближайших соседей, которые бы эффективно сочетались скорость и точность. Традиционные методы точного поиска становятся непрактичными при работе с большими наборами данных, а упрощенные алгоритмы приближенного поиска часто жертвуют качеством результатов. Это стимулирует активные исследования в области разработки новых структур данных, алгоритмов индексирования и методов квантования, направленных на преодоление ограничений существующих технологий. Современные разработки сосредоточены на создании алгоритмов, способных масштабироваться до петабайтов данных, сохраняя при этом высокую точность и низкую задержку, что критически важно для таких приложений, как семантический поиск, рекомендательные системы и анализ больших данных в реальном времени.
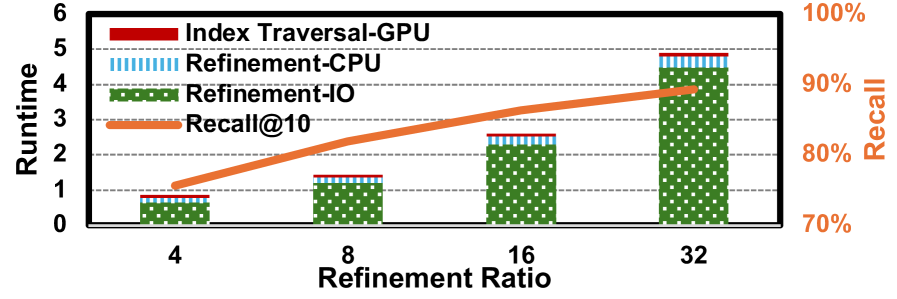
FaTRQ: Система уточнения с использованием дальней памяти
Система FaTRQ решает проблему узкого места ввода-вывода (I/O bottleneck) в алгоритмах приближенного поиска ближайших соседей (ANNS) за счет использования “far memory” — промежуточного слоя хранения данных, расположенного между оперативной памятью (DRAM) и твердотельными накопителями (SSD). Данный подход позволяет снизить нагрузку на высокоскоростную DRAM, перемещая менее критичные данные в более медленную, но существенно более емкую и экономичную “far memory”. Это достигается за счет оптимизации доступа к данным и минимизации объема передаваемых данных между различными уровнями памяти, что особенно важно при работе с большими объемами данных, характерными для современных задач ANNS. Использование «far memory» позволяет существенно снизить стоимость хранения и повысить пропускную способность системы по сравнению с использованием только DRAM.
Ключевой инновацией FaTRQ является техника Tiered Residual Quantization (многоуровневая остаточная квантизация), представляющая собой метод кодирования векторов посредством грубого приближения и последовательных компактных остаточных коррекций. Вектор изначально представляется в виде крупного квантованного значения, после чего к нему добавляются последовательные, все более мелкие, остаточные значения, кодирующие разницу между исходным вектором и его приближением. Такой подход позволяет эффективно представлять вектор с высокой точностью, при этом используя меньше памяти и вычислительных ресурсов для хранения и обработки. Каждый последующий остаток представляет собой уточнение предыдущего приближения, что позволяет добиться высокой точности представления при относительно небольшом размере данных.
Система FaTRQ значительно снижает объем перемещения данных и ускоряет процесс поиска за счет переноса вычислений остатков в «far memory» — промежуточный уровень хранения между оперативной памятью (DRAM) и твердотельными накопителями (SSD). В ходе тестирования, FaTRQ демонстрирует увеличение пропускной способности до 9.4 раза по сравнению с GPU-ускоренными алгоритмами Approximate Nearest Neighbors (ANN), такими как IVF-FAISS. Это достигается за счет эффективного использования более медленной, но более емкой «far memory» для хранения и обработки остаточных векторов, что снижает нагрузку на высокоскоростную DRAM и, как следствие, уменьшает задержки и повышает общую производительность системы.
Система FaTRQ использует и расширяет существующие методы приближенного поиска ближайших соседей (Approximate Nearest Neighbor Search, ANNS), такие как Inverted File Index (IVF) и Compact Aggregated Graph Representation Approach (CAGRA). В отличие от традиционных реализаций, FaTRQ адаптирует эти алгоритмы для эффективного использования “дальней памяти” — промежуточного уровня хранения между оперативной памятью (DRAM) и твердотельными накопителями (SSD). Это достигается за счет переноса части вычислительной нагрузки, связанной с обработкой векторов, в дальнюю память, что позволяет минимизировать перемещение данных между различными уровнями памяти и, как следствие, повысить общую производительность системы. Использование существующих методов в сочетании с оптимизацией для дальней памяти позволяет FaTRQ обеспечить значительное ускорение поиска без необходимости полной переработки существующих алгоритмов.
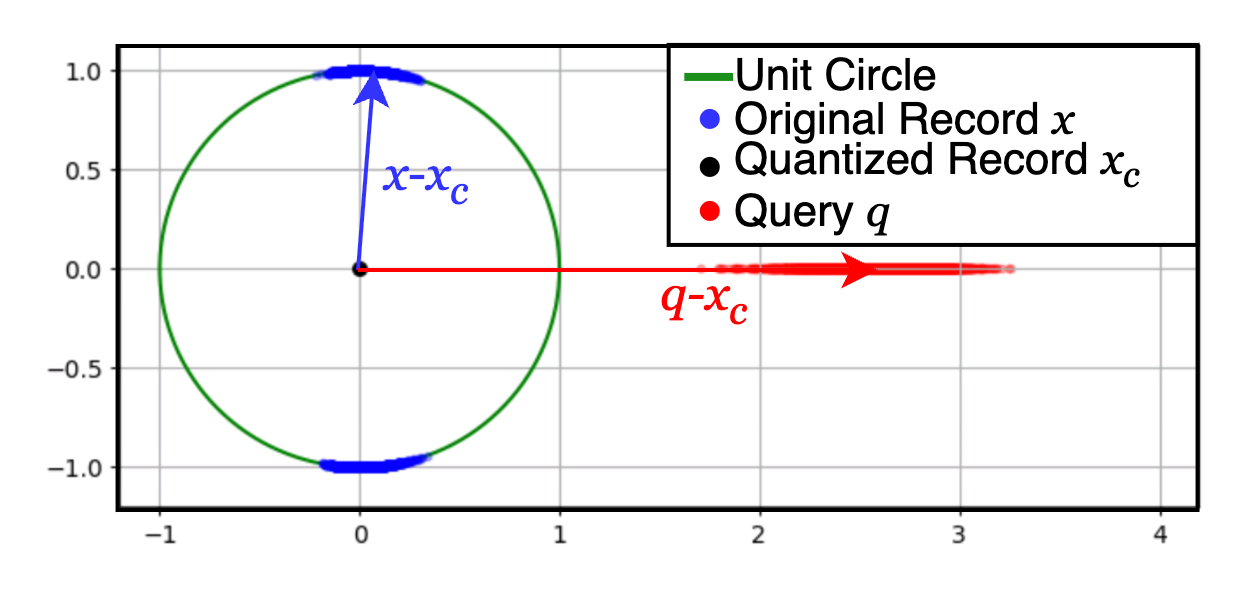
Многоуровневая остаточная квантизация: Кодирование точности с использованием троичных значений
Традиционный метод Residual Quantization (квантование остатков) расширен в Tiered Residual Quantization (FaTRQ) за счет использования троичного кодекса — набора значений {-1, 0, 1} — для представления векторов остатков. В отличие от традиционных методов, использующих, например, 3-битные коды, FaTRQ позволяет представлять информацию об остатках, используя лишь три возможных значения. Это упрощение позволяет добиться более компактного хранения данных и снизить вычислительные затраты на этапе уточнения, поскольку требуется меньше операций для обработки и декодирования кодов.
Использование троичного кодекса (значения {-1, 0, 1}) для представления остаточных векторов позволяет значительно уменьшить объем необходимой памяти и вычислительные затраты на этапе уточнения. Троичное представление данных требует меньше бит для кодирования информации по сравнению с традиционными методами, такими как 3-битный SQ, что напрямую снижает требования к пропускной способности памяти и объему хранения. Это особенно важно в задачах, где ресурсы ограничены или требуется высокая скорость обработки, поскольку уменьшение объема данных, подлежащих обработке, приводит к снижению энергопотребления и повышению общей производительности системы.
Процесс оценки расстояния в Tiered Residual Quantization (FaTRQ) осуществляется поэтапно, путем разложения L2-расстояния на составляющие. Вместо однократной оценки полного расстояния, FaTRQ последовательно уточняет его, используя остаточные коды из тернарного кодекса {-1, 0, 1}. На каждом этапе вычисляется вклад определенной компоненты в общее расстояние, и остаточный код применяется для корректировки текущей оценки. Такой инкрементальный подход позволяет эффективно использовать тернарное представление для постепенного приближения к истинному значению L2-расстояния, обеспечивая высокую точность при минимальных затратах на хранение и вычисления.
В ходе тестирования, FaTRQ демонстрирует значительное улучшение точности оценки расстояния, достигая средней квадратичной ошибки (MSE) в 0.0159. Это существенный прогресс по сравнению с 3-битными кодами SQ, где MSE составлял 0.258. Помимо повышения точности, FaTRQ также обеспечивает снижение объема операций ввода-вывода с твердотельного накопителя (SSD) в 2.8 раза, что способствует оптимизации производительности и энергоэффективности системы.
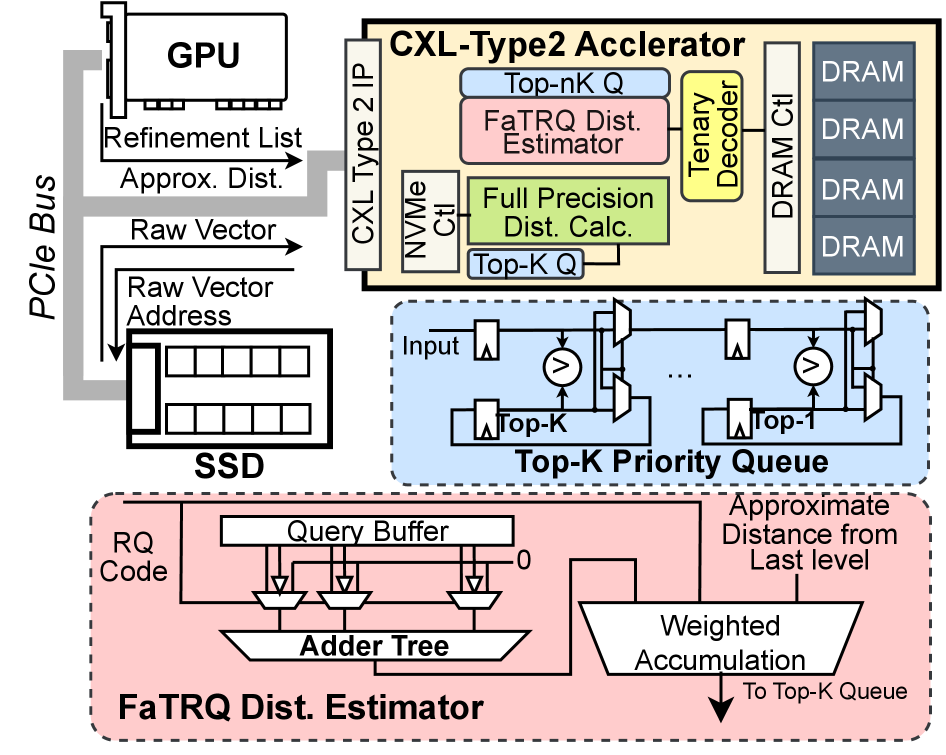
Аппаратное ускорение и перспективы развития
FaTRQ разработан для эффективного использования ускорителей CXL Type-2, что позволяет переносить вычислительные задачи и хранить данные непосредственно в памяти, подключенной по интерфейсу CXL. Такой подход позволяет существенно снизить задержки, связанные с передачей данных между центральным процессором и памятью, и повысить пропускную способность системы. Перенос вычислений на специализированные ускорители CXL Type-2 освобождает ресурсы центрального процессора, что особенно важно при работе с большими объемами данных и сложными нейронными сетями. Использование памяти, подключенной по CXL, предоставляет более быстрый доступ к данным, необходимым для вычислений, что приводит к значительному ускорению работы приложений и снижению энергопотребления по сравнению с традиционными системами, использующими только системную память.
Сочетание учета удаленной памяти и аппаратного ускорения открывает значительные преимущества в производительности для крупномасштабных приложений, использующих нейронные сети. Подход позволяет эффективно обрабатывать огромные объемы данных, перемещая вычисления ближе к памяти и минимизируя задержки, связанные с передачей данных между процессором и оперативной памятью. Благодаря такому решению, приложения, требующие интенсивных вычислений и работы с большими наборами данных — например, системы рекомендаций, поисковые движки и задачи анализа изображений — демонстрируют существенный прирост скорости и снижение энергопотребления. Подобная оптимизация особенно важна в сценариях, где доступ к памяти является узким местом, позволяя добиться максимальной эффективности и масштабируемости в работе с большими данными.
Подход FaTRQ демонстрирует значительный потенциал в усилении производительности семантического поиска за счет интеграции с передовыми моделями формирования векторных представлений, такими как SBERT и CLIP. Использование этих моделей позволяет преобразовывать запросы и данные в компактные векторные представления, что существенно ускоряет процесс поиска наиболее релевантной информации. FaTRQ, используя аппаратное ускорение и возможности CXL, оптимизирует вычисления, связанные с этими векторными представлениями, что приводит к повышению точности и скорости семантического поиска по сравнению с традиционными методами. Такая комбинация технологий открывает новые возможности для приложений, требующих эффективного анализа и извлечения информации из больших объемов данных, например, в областях обработки естественного языка и информационного поиска.
Разработанный специализированный процессорный блок, интегрированный в устройство CXL Type-2, демонстрирует компактные размеры — всего 0.729 мм². Несмотря на свою функциональность, энергопотребление данного блока составляет 897 мВт. Этот показатель позволяет достичь оптимального баланса между вычислительной мощностью и энергоэффективностью, что особенно важно для систем, требующих высокой производительности при ограниченных ресурсах. Минимальная площадь чипа способствует увеличению плотности интеграции и снижению стоимости производства, в то время как контролируемое энергопотребление обеспечивает стабильную работу и снижает требования к системе охлаждения.
Исследование, представленное в данной работе, стремится к оптимизации поиска ближайших соседей в векторах, что особенно актуально для систем с иерархической памятью. Авторы предлагают подход FaTRQ, который позволяет снизить затраты на ввод-вывод данных и повысить пропускную способность поиска. В этом контексте, слова Брайана Кернигана: «Простота — это высшая степень совершенства» (Простота — это высшая степень совершенства), находят глубокий отклик. Стремление к элегантности и минимизации избыточности, лежащее в основе FaTRQ, перекликается с философией Кернигана. Сокращение сложности за счет эффективного использования остаточной квантизации и многоуровневой памяти демонстрирует, что истинная красота заключается в компрессии без потерь, когда система работает эффективно и лаконично.
Что дальше?
Представленное исследование, фокусируясь на снижении стоимости ввода-вывода в системах приближенного поиска ближайших соседей, лишь подчеркивает фундаментальную сложность проблемы. Успешное применение иерархической памяти и остаточной квантизации — это не триумф, а признание того, что изначальная задача была сформулирована слишком оптимистично. Каждый уровень абстракции, каждая оптимизация — это компромисс, а компромиссы требуют дальнейшей рефлексии.
Будущие работы, вероятно, будут направлены на преодоление неизбежных потерь точности, возникающих при агрессивном сжатии данных. Упрощение — это иллюзия; реальность всегда сложнее. Необходимо исследовать методы динамической адаптации уровней квантизации к специфике данных и запросов, а также рассмотреть возможность интеграции с новыми архитектурами памяти, такими как CXL, не как с панацеей, а как очередным инструментом в арсенале.
В конечном счете, совершенство достигается не в создании более сложных систем, а в их упрощении до предела. Истинный прогресс — это исчезновение автора, когда решение становится настолько очевидным, что перестает требовать объяснений. Пока же, предстоит ещё долгий путь к этой иллюзорной цели.
Оригинал статьи: https://arxiv.org/pdf/2601.09985.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Укрощение шума: как оптимизировать квантовые алгоритмы
- Квантовый Борьба: Китай и США на Передовой
- Квантовая химия: моделирование сложных молекул на пороге реальности
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Интеллектуальная маршрутизация в коллаборации языковых моделей
2026-01-19 00:21