Память на кончиках пальцев: оценка мобильных GUI-агентов

Новое исследование представляет всесторонний инструмент для анализа способности мобильных приложений запоминать и использовать информацию в динамичных условиях.
Новое исследование представляет всесторонний инструмент для анализа способности мобильных приложений запоминать и использовать информацию в динамичных условиях.
Представлен набор задач, призванный расширить возможности ИИ в области научных исследований и автоматизации процесса открытия.
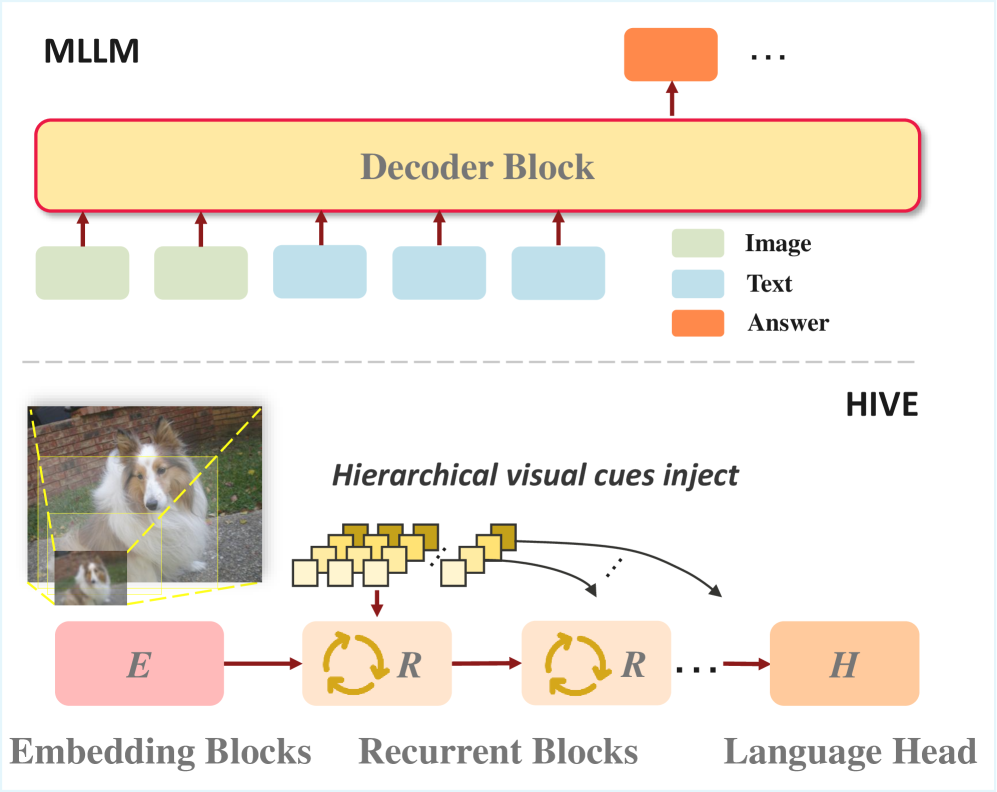
Исследователи представили HIVE — систему, позволяющую языковым моделям анализировать изображения более глубоко и делать более обоснованные выводы, не полагаясь только на текстовые объяснения.
![Универсальная линейная зависимость между структурными корреляциями, описываемыми функцией распределения пар [latex]g(r)[/latex], и различными свойствами, связанными с фононами - такими как плотность состояний, спектры комбинационного рассеяния и неупругого рассеяния нейтронов - позволяет предсказывать эти свойства аморфных материалов, включая однослойные, объемные и высокоэнтропийные сплавы, с помощью единой модели, основанной на обучаемых весах и смещениях.](https://arxiv.org/html/2602.05313v1/x1.png)
Новое исследование показывает, что для предсказания колебательных свойств аморфных материалов достаточно простой линейной модели.
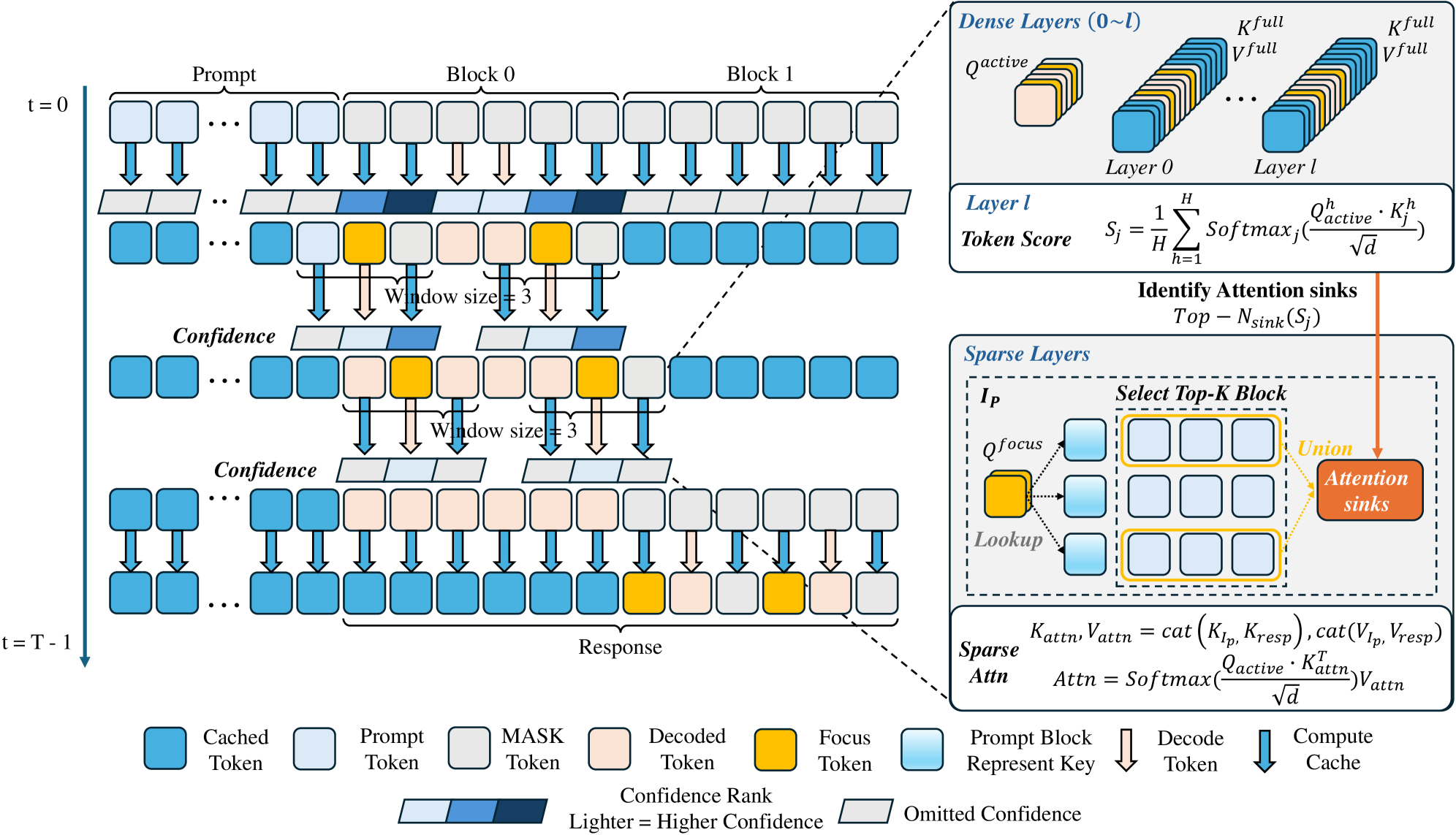
Исследователи предлагают эффективный метод повышения скорости работы больших языковых моделей при обработке длинных текстов, не жертвуя качеством генерации.
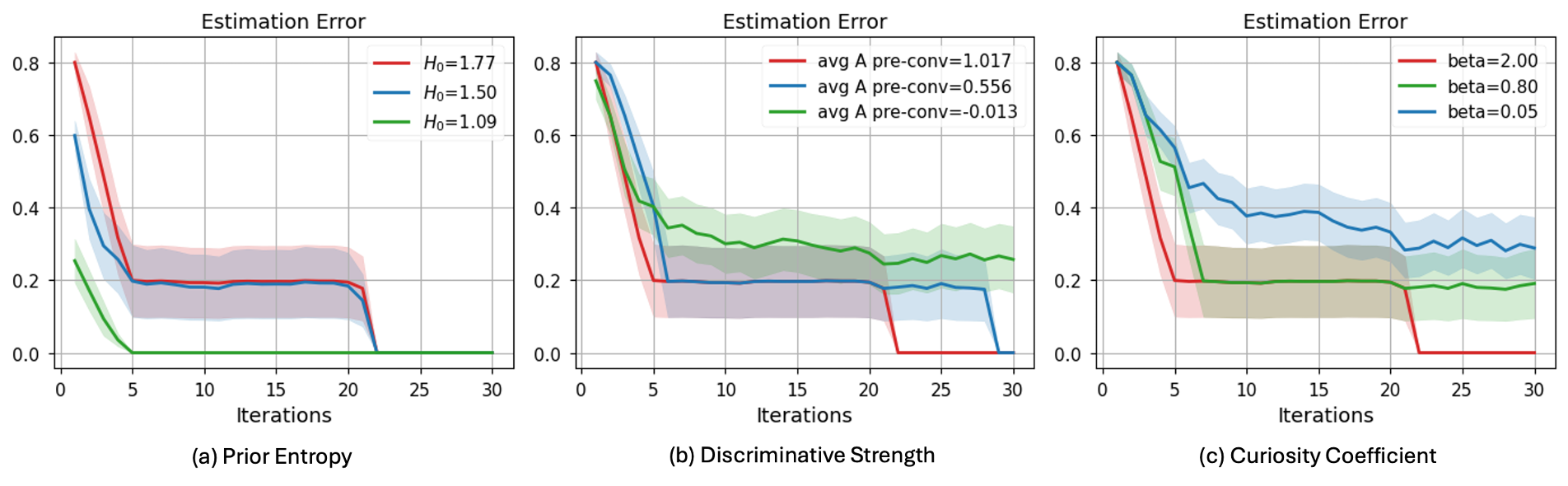
Новое исследование теоретически обосновывает, что достаточно высокий коэффициент ‘любопытства’ в алгоритмах активного вывода гарантирует как самосогласованное обучение, так и оптимальное принятие решений.

Исследователи представили инновационную архитектуру для эффективного сжатия и восстановления видеоданных, основанную на диффузионных моделях и трансформерах.
Представлен BioFVM-B — библиотека, значительно ускоряющая многомасштабное моделирование клеток и позволяющая симулировать целые микроокружения органов.
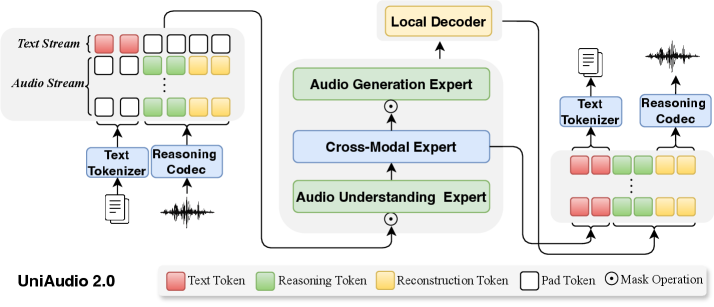
Исследователи представили UniAudio 2.0 — универсальную модель для обработки звука, способную понимать и создавать аудиоконтент, подобно тому, как языковые модели работают с текстом.

Новая архитектура DARWIN демонстрирует способность нейронных сетей к самосовершенствованию посредством генетического алгоритма и взаимодействия агентов.