Видео как ключ к пониманию: новый взгляд на визуальное мышление

Исследование показывает, что модели генерации видео способны эффективно решать задачи пространственного планирования, превосходя текстовые подходы, и демонстрируют улучшение результатов с увеличением продолжительности генерируемого видео.
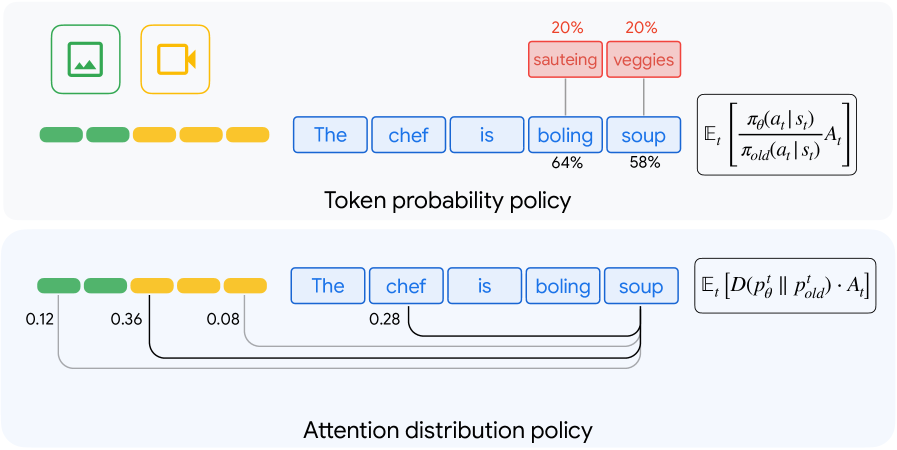
![Процесс дистилляции данных, реализованный в InfoUtil, максимизирует их ценность посредством двух последовательных этапов: сначала отбираются наиболее информативные фрагменты с использованием значений Шейпли [latex] \text{Shapley Value} [/latex] - метода атрибуции из теории игр, а затем, из этих кандидатов, выбираются образцы с наивысшей полезностью, оцениваемой с помощью градиентной нормы [latex] \text{Gradient Norm} [/latex], выступающей в качестве верхней границы полезности, в результате чего формируется дистиллированный набор данных, содержащий лишь наиболее ценные и информативные элементы.](https://arxiv.org/html/2601.21296v1/x2.png)
![Предлагаемое древо решений определяет процедуру вмешательства во время выполнения, опираясь на предварительные оценки вероятности отказа ([latex]pp[/latex]), восстановления ([latex]rr[/latex]) и нарушения ([latex]dd[/latex]), в результате чего формируется пороговое значение ([latex]p^{\star} = d/(r+d)[/latex]), продемонстрированное на примере ALFWorld с использованием Qwen-3-8B.](https://arxiv.org/html/2602.03338v1/x1.png)
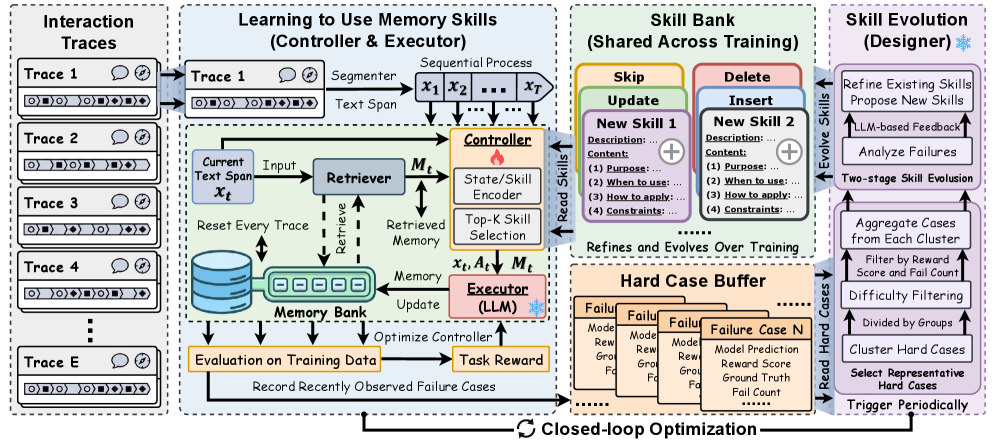
![Обучающая схема STProtein использует многоуровневое представление белковых последовательностей, включающее в себя как глобальные контекстные эмбеддинги, полученные с помощью трансформеров, так и локальные признаки, извлекаемые сверточными слоями, для точного предсказания структуры белка, опираясь на оптимизацию с помощью алгоритма [latex] AdamW [/latex] и стратегию планирования обучения, направленную на улучшение обобщающей способности модели.](https://arxiv.org/html/2602.05811v1/images/structure/framework4.jpg)